This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
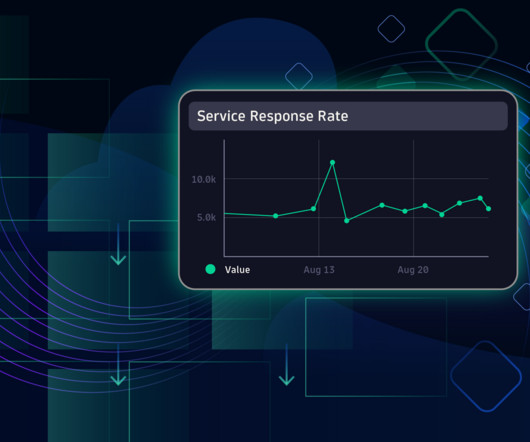
Imagine you’re using a lot of OpenTelemetry and Prometheus metrics on a crucial platform. A histogram is a specific type of metric that allows users to understand the distribution of data points over a period of time. You’re gathering a lot of data, but you can’t make sense of it. What are histograms, and why use them?
That is, relying on metrics, logs, and traces to understand what software is doing and where it’s running into snags. While classic logging is an essential tool in debugging issues, it often lacks context and only provides snapshot information of one specific location in your code/application. What is OpenTelemetry?
A natural solution is to make flows configurable using configuration files, so variants can be defined without changing the code. Unlike parameters, configs can be used more widely in your flow code, particularly, they can be used in step or flow level decorators as well as to set defaults for parameters.
In the first part of this three-part series, The road to observability with OpenTelemetry demo part 1: Identifying metrics and traces with OpenTelemetry , we talked about observability and how OpenTelemetry works to instrument applications across different languages and platforms. php declare(strict_types=1); require __DIR__.
Making applications observable—relying on metrics, logs, and traces to understand what software is doing and how it’s performing—has become increasingly important as workloads are shifting to multicloud environments. We also introduced our demo app and explained how to define the metrics and traces it uses.
Amazon Bedrock , equipped with Dynatrace Davis AI and LLM observability , gives you end-to-end insight into the Generative AI stack, from code-level visibility and performance metrics to GenAI-specific guardrails. Send unified data to Dynatrace for analysis alongside your logs, metrics, and traces.
There’s no lack of metrics, logs, traces, or events when monitoring your Kubernetes (K8s) workloads. Dynatrace Davis , our deterministic AI, recently notified our teams about a problem in one of our Keptn instances we just recently spun up to demo our automated performance analysis capabilities orchestrated by Keptn. Dynatrace news.
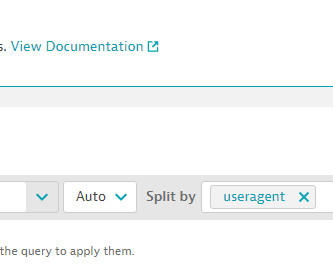
Metrics matter. But without complex analytics to make sense of them in context, metrics are often too raw to be useful on their own. To achieve relevant insights, raw metrics typically need to be processed through filtering, aggregation, or arithmetic operations. Examples of metric calculations. Dynatrace news.
I never thought I’d write an article in defence of DOMContentLoaded , but here it is… For many, many years now, performance engineers have been making a concerted effort to move away from technical metrics such as Load , and toward more user-facing, UX metrics such as Speed Index or Largest Contentful Paint. Or are they…?
Agentless RUM, OpenKit, and Metric ingest to the rescue! Agentless RUM allows you to monitor your front-end apps by simply pasting a JavaScript tag into your code. With the SDK you wrap your application code to report Sessions and Actions. Doing so is as simple as a click on the Create Metric button and then Pin to Dashboard.
If you want to know more about keptn, I encourage you to check out www.keptn.sh , “What is keptn and how to get started” (blog), “Getting started with keptn” (YouTube) or my slides on Shipping Code like a keptn. Automated Metric Anomaly Detection. Alerting on high CPU is not special – but – I am really only running a small node.js
Davis AI contextually aligns all relevant data points—such as logs, traces, and metrics—enabling teams to act quickly and accurately while still providing power users with the flexibility and depth they desire and need. Learn how Dynatrace can address your specific needs with a custom live demo.
Spring also introduced Micrometer, a vendor-agnostic metric API with rich instrumentation options. Soon after, Dynatrace built a registry for exporting Micrometer metrics. Our data APIs, which ingest millions of metrics, traces, and logs per second, are reconciled using Micrometer-based metrics.
Organizations can now accelerate innovation and reduce the risk of failed software releases by incorporating on-demand synthetic monitoring as a metrics provider for automatic, continuous release-validation processes. This metric indicates how quickly software can be released to production. Dynatrace news.
Like general observability , AWS observability is the capacity to measure the current state of your AWS environment based on the data it generates, including its logs, metrics, and traces. Lambda is Amazon’s event-driven, functions-as-a-service (FaaS) compute service that runs code when triggered for application and back-end services.
This view seamlessly correlates crucial events across all affected components, eliminating the manual effort of sifting through various monitoring tools for infrastructure, process, or service metrics. By using JavaScript and DQL, these dashboards can help generate reports on the current DORA metrics.
To ensure high standards, it’s essential that your organization establish automated validations in an early phase of the software development process—ideally when code is written. Ensure expected production behavior One Dynatrace team is responsible for the demo applications we use to demonstrate Dynatrace capabilities.
A full-stack observability solution uses telemetry data such as logs, metrics, and traces to give IT teams insight into application, infrastructure, and UX performance. Not just infrastructure connections, but the relationships and dependencies between containers, microservices , and code at all network layers. Watch webinar now!
Monitoring-as-code can also be configured in GitOps fashion. Open source logs and metrics take precedence in the monitoring process. In addition, Dynatrace effortlessly collects crucial DORA metrics, SLOs, and business analytics data via its robust unified data platform, Dynatrace Grail™. Say goodbye to high watermark pricing.
The Local self-monitoring environment collects and aggregates all the self-monitoring metrics that are captured from the other environments on the cluster. When the capture rate for metrics is at or near 100%, data capture is in progress and all incoming data is covered. The Code Modules metric show the deployment status of the?OneAgent
Metrics, logs , and traces make up three vital prongs of modern observability. Together with metrics, three sources of data help IT pros identify the presence and causes of performance problems, user experience issues, and potential security threats. For context, teams collect metrics for further analysis and indexing.
I could upgrade the vehicle in the app, or simply get in the car and use the QR code to exit the garage. The hotel’s rental subsidiary limits their IT monitoring to internal system metrics, with no visibility into user journeys or business transactions. What do you think my net promoter score ( NPS ) might be for each of these?
Observability is made up of three key pillars: metrics, logs, and traces. Metrics are measures of critical system values, such as CPU utilization or average write latency to persistent storage. Observability tools, such as metrics monitoring, log viewers, and tracing applications, are relatively small in scope.
This gives you deep visibility into your code running in Azure Functions, and, as a result, an understanding of its impact on overall application performance and user experience. Code-level visibility continues to be supported for.NET-based functions running in an App Service plan. Optimize your code with code-level visibility.
In recent years, function-as-a-service (FaaS) platforms such as Google Cloud Functions (GCF) have gained popularity as an easy way to run code in a highly available, fault-tolerant serverless environment. GCF also enables teams to run custom-written code to connect multiple services in Node, Python, Go, Java,NET, Ruby, and PHP.
In this blog post, we’ll use Dynatrace Security Analytics to go threat hunting, bringing together logs, traces, metrics, and, crucially, threat alerts. Instead, we want to focus on detecting and stopping attacks before they happen: In your applications, in context, at the exact line of code that is vulnerable and in use.
I could upgrade the vehicle in the app, or simply get in the car and use the QR code to exit the garage. The hotel’s rental subsidiary limits their IT monitoring to internal system metrics, with no visibility into user journeys or business transactions. What do you think my net promoter score ( NPS ) might be for each of these?
Someone hacks together a quick demo with ChatGPT and LlamaIndex. The system is inconsistent, slow, hallucinatingand that amazing demo starts collecting digital dust. Check out the graph belowsee how excitement for traditional software builds steadily while GenAI starts with a flashy demo and then hits a wall of challenges?
As an example, Kubernetes does not deploy source code, nor does it have the capacity to connect application-level services. In fact, once containerized, many of these services and the source code itself is virtually invisible in a standalone Kubernetes environment. Code level visibility for fast problem resolution.
Real user monitoring collects data on a variety of metrics. For example, data collected on load actions can include navigation start, request start, and speed index metrics. Real user monitoring works by injecting code into an application to capture metrics while the application is in use. How real user monitoring works.
In addition to requiring a high degree of custom coding, feature flags can rapidly accrue technical debt that can be opaque to diagnose. Using scripting tags, feature flags work without having to deploy new code. Deploy code without releasing it to end users such as new functionality hidden by default behind a feature flag.
This new service is a step forward to enhance the user experience with code-driven automation of Kubernetes EKS and the Dynatrace Intelligent Observability Platform. The advanced observability gained for the EKS infrastructure gives teams code-level detail, context, and tracing to every service the application touches.
This could be adding high-quality graphics, running A/B testing to make UX tweaks, or deploying new code to make it perform better. Dynatrace Business Analytics is powered by Dynatrace Real User Monitoring (RUM) , Dynatrace PurePaths , and external metrics ingested through the Dynatrace API. New to Dynatrace? Try our free trial !
This blog continues with more examples of Dynatrace’s Monitoring as Code (Monaco) and Service Level Objectives (SLOs) release validation using Dynatrace SaaS Cloud Automation. Example #3 – Automate Monitoring configuration as code. Below is a picture illustrating the use case of using Monaco as part of a code delivery pipeline.
This gives you deep visibility into your code running in Azure Functions, and, as a result, an understanding of its impact on overall application performance and user experience. Code-level visibility continues to be supported for.NET-based functions running in an App Service plan. Optimize your code with code-level visibility.
As such, we recently opened up our platform for metric ingestion and log monitoring and built integrations for key formats in those spaces. Say you’re running the Online Boutique , a cloud-native microservices demo application, that allows users to browse items, add them to a shopping cart, and purchase them. Detailed use case.
Keptn is an event-based platform for continuous delivery and automated operations to help developers focus on code instead of witting tons of configuration and pipeline files. The Jenkins to Keptn integration was explained and demoed in one of our Performance Clinic videos; “. Jenkins code libraries.
These sets of tools are acquiring one or more different types of raw data (metrics, logs, traces, events, code-level details…) at various granularity, process them and create alerts (a threshold or learned baseline was breached, a certain log pattern occurred and so forth). I’ve illustrated that on the right half on the image below.
Having the right metrics available on demand and at a high resolution is key to understanding how a system behaves and helps to quickly troubleshoot performance issues. Snoops: block IO, exec() Scheduler run queue latency In the below diagram we can see a demo for a wget job. or “are there noisy neighbors affecting my container task?”.
Your team should incorporate performance metrics, errors, and access logs into your monitoring platform. It captures their metrics, logs, traces, and user experience data, and analyzes them in the context of their dependencies among other services and infrastructure. Bugs, security, and throttling related slowdowns are concerns.
A container with inefficient code might affect critical workloads and practically make the whole node unusable , or worse, because of replication, it can impact the whole cluster. For that, on top of the resource usage metrics, you need to monitor cluster events and object state metrics. . Need help getting started?
With clear insight into crucial system metrics, teams can automate more processes and responses with greater precision. With the complexity of modern multicloud environments, traditional aggregation and correlation approaches are inadequate to quickly discover faulty code, anomalies, and vulnerabilities. More automation.
In other words, where the application code resides. Data Explorer “test your Metric Expression” for info result coming from the above metric. Following the previous metric (above) used for the SLO, the threshold employed is an average of 100 ms for the Key Performance Indicator (KPI) of DOM Interactive.
Gone are the days for Christian manually looking at dashboards and metrics after a new build got deployed into a testing or acceptance environment: Integrating Keptn into your existing DevOps tools such as GitLab is just a matter of an API call. Monitoring Configuration as Code. Incident Notification and Auto-Remediation.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content