This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Dataengineering projects often require the setup and management of complex infrastructures that support data processing, storage, and analysis. In this article, we will explore the benefits of leveraging IaC for dataengineering projects and provide detailed implementation steps to get started.
In software engineering, we've learned that building robust and stable applications has a direct correlation with overall organization performance. The data community is striving to incorporate the core concepts of engineering rigor found in software communities but still has further to go.
DataEngineers of Netflix?—?Interview Interview with Samuel Setegne Samuel Setegne This post is part of our “DataEngineers of Netflix” interview series, where our very own dataengineers talk about their journeys to DataEngineering @ Netflix. What drew you to Netflix?
One of the main reasons this feature exists is just like with food samples, to give you “a taste” of the production quality ETL code that you could encounter inside the Netflix data ecosystem. " , country_code STRING COMMENT "Country code of the playback session." Let’s review the transformation steps below.
Analytics at Netflix: Who We Are and What We Do An Introduction to Analytics and Visualization Engineering at Netflix by Molly Jackman & Meghana Reddy Explained: Season 1 (Photo Credit: Netflix) Across nearly every industry, there is recognition that data analytics is key to driving informed business decision-making.
IT automation is the practice of using coded instructions to carry out IT tasks without human intervention. At its most basic, automating IT processes works by executing scripts or procedures either on a schedule or in response to particular events, such as checking a file into a code repository. What is IT automation?
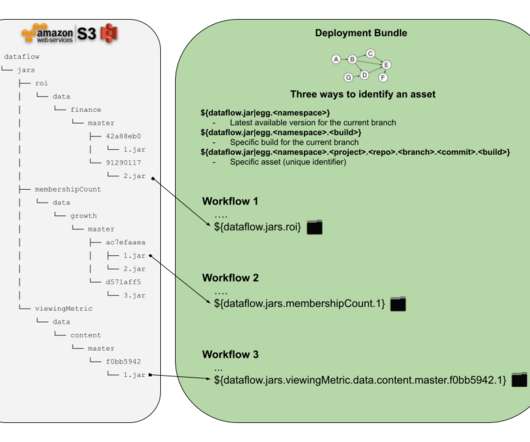
any business logic code in a raw (e.g. JAR) form to be executed as part of the user defined data pipeline. data pipeline ?—?a DAG) for the purpose of transforming data using some business logic. Or what if Alice wanted to add new backup functionality and she accidentally broke existing code while updating it?
Netflix’s engineering culture is predicated on Freedom & Responsibility, the idea that everyone (and every team) at Netflix is entrusted with a core responsibility and they are free to operate with freedom to satisfy their mission. All these micro-services are currently operated in AWS cloud infrastructure.
At Netflix, our data scientists span many areas of technical specialization, including experimentation, causal inference, machine learning, NLP, modeling, and optimization. Together with data analytics and dataengineering, we comprise the larger, centralized Data Science and Engineering group.
Our customers are product and engineering teams at Netflix that build these software services and platforms. Our goal is to manage security risks to Netflix via clear, opinionated security guidance, and by providing risk context to Netflix engineering teams to make pragmatic risk decisions at scale.
Usability Netflix is a data-driven company, where key decisions are driven by data insights, from the pixel color used on the landing page to the renewal of a TV-series. Data scientists, engineers, non-engineers, and even content producers all run their data pipelines to get the necessary insights.
It also improves the engineering productivity by simplifying the existing pipelines and unlocking the new patterns. Users configure the workflow to read the data in a window (e.g. The window is set based on users’ domain knowledge so that users have a high confidence that the late arriving data will be included or will not matter (i.e.
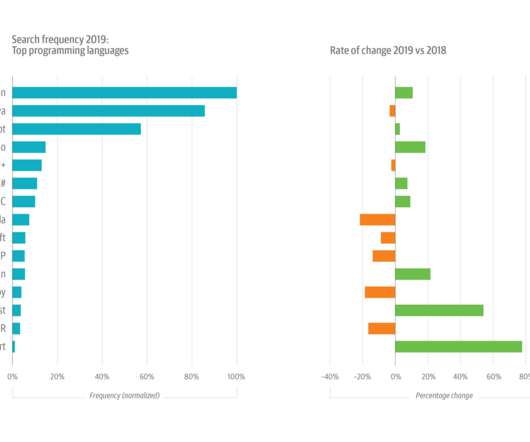
This year’s growth in Python usage was buoyed by its increasing popularity among data scientists and machine learning (ML) and artificial intelligence (AI) engineers. there’s a Python library for virtually anything a developer or data scientist might need to do. In aggregate, dataengineering usage declined 8% in 2019.
—?and what the role entails by Julie Beckley & Chris Pham This Q&A provides insights into the diverse set of skills, projects, and culture within Data Science and Engineering (DSE) at Netflix through the eyes of two team members: Chris Pham and Julie Beckley. Photo from a team curling offsite?—?There’s There’s us to the right!
The evolution of your technology architecture should depend on the size, culture, and skill set of your engineering organization. There are no hard-and-fast rules to figure out interdependency between technology architecture and engineering organization but below is what I think can really work well for product startup.
As the scale of the messages being processed increased and we were making more code changes in the message processor, we found ourselves looking for something more flexible. KeyValue is an abstraction over the storage engine itself, which allows us to choose the best storage engine that meets our SLO needs.
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Apply here.
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Apply here.
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Apply here.
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Apply here.
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Apply here. World-class tech companies do things very differently.
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Apply here. World-class tech companies do things very differently.
When it comes to organising engineering teams, a popular view has been to organise your teams based on either Spotify's agile model (i.e. One thing stand-out to me is being intentional and practical about your engineering organisation design. squads, chapters, tribes, and guilds) or simply follow Amazon's two-pizza team model.
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Apply here.
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Apply here.
I wasn’t even entirely sure what the right role fit would be and originally applied for a different position, before being redirected to the Analytics Engineer role. Working in Studio Data Science & Engineering (“Studio DSE”) was basically a dream come true. Writing code (SQL, Python) ???? How did you come to Netflix?
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Apply here. World-class tech companies do things very differently.
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Apply here. World-class tech companies do things very differently.
Scrapinghub is hiring a Senior Software Engineer (Big Data/AI). You will be designing and implementing distributed systems : large-scale web crawling platform, integrating Deep Learning based web data extraction components, working on queue algorithms, large datasets, creating a development platform for other company departments, etc.
Scrapinghub is hiring a Senior Software Engineer (Big Data/AI). You will be designing and implementing distributed systems : large-scale web crawling platform, integrating Deep Learning based web data extraction components, working on queue algorithms, large datasets, creating a development platform for other company departments, etc.
Scrapinghub is hiring a Senior Software Engineer (Big Data/AI). You will be designing and implementing distributed systems : large-scale web crawling platform, integrating Deep Learning based web data extraction components, working on queue algorithms, large datasets, creating a development platform for other company departments, etc.
Scrapinghub is hiring a Senior Software Engineer (Big Data/AI). You will be designing and implementing distributed systems : large-scale web crawling platform, integrating Deep Learning based web data extraction components, working on queue algorithms, large datasets, creating a development platform for other company departments, etc.
Scrapinghub is hiring a Senior Software Engineer (Big Data/AI). You will be designing and implementing distributed systems : large-scale web crawling platform, integrating Deep Learning based web data extraction components, working on queue algorithms, large datasets, creating a development platform for other company departments, etc.
First, the behavior of an AI application depends on a model , which is built from source code and training data. A model isn’t source code, and it isn’t data; it’s an artifact built from the two. This means that, to have a history of how an application was developed, you have to look at more than the source code.
Scrapinghub is hiring a Senior Software Engineer (Big Data/AI). You will be designing and implementing distributed systems : large-scale web crawling platform, integrating Deep Learning based web data extraction components, working on queue algorithms, large datasets, creating a development platform for other company departments, etc.
It’s not about getting software developers to write code faster. Perhaps the appropriate yardstick for AI projects is the experiment itself, not the code committed to git.). Key survey results: The C-suite is engaged with data quality. Data quality might get worse before it gets better. Can Agile work for large teams?
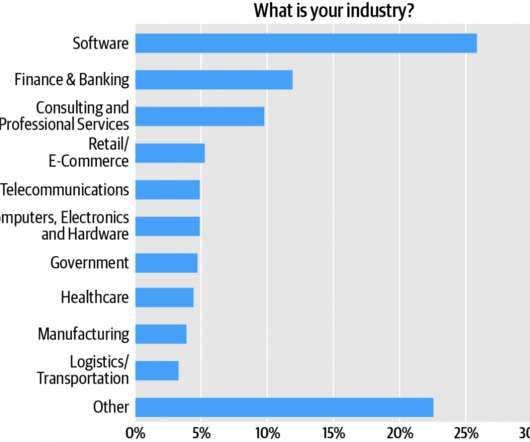
Software engineers comprise the survey audience’s single largest cluster, over one quarter (27%) of respondents (Figure 1). Adding architects and engineers, we see that roughly 55% of the respondents are directly involved in software development. Technical roles dominate, but management roles are represented, too. services).
However, the data infrastructure to collect, store and process data is geared toward developers (e.g., In AWS’ quest to enable the best data storage options for engineers, we have built several innovative database solutions like Amazon RDS, Amazon RDS for Aurora, Amazon DynamoDB, and Amazon Redshift.
There are shadow IT teams of developers or dataengineers that spring up in areas like operations or marketing because the captive IT function is slow, if not outright incapable, of responding to internal customer demand. There are also shadow activities of large software delivery programs. The scope taken out of the 1.0
In recent times, in order to gain valuable insights or to develop the data-driven products companies such as Netflix, Spotify, Uber, AirBnB have built internal data pipelines. If built correctly, data pipelines can offer strategic advantages to the business. It can be used to power new analytics, insight, and product features.
SUS206 Sustainability and AWS silicon — Kamran Khan AWS Senior Product Manager Inferential/Trainium/FPGA, David Chaiken Pinterest Chief Architect, and Paul Mazurkiewicz AWS Senior Principal Engineer. SUS209 — there was no talk with this code. SUS304 to SUS311 No talks with these codes.
There are hundreds of tools through which the automation code can be written in different programming languages. Udacity Udacity provides nanodegree programs on all automation languages like C++, Machine Learning, Dataengineer, Robotics and more. That was it.
The machine learning process starts with the discovery of domain data types for attributes (aka columns or fields). Then machine learning engine assembles these individual attributes into higher-level business entities. The discovery of domains and data type for attributes is a classification problem.
This was a good, balanced, assessment, and it was fascinating to see Pulumi’s “code over template” approach. From dataengineering, to cost management, via conversations about team dynamics and architecture, we like to get involved with all-things-cloud-and-DevOps related at our clients. I wholeheartedly agree.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content