This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Dataengineering projects often require the setup and management of complex infrastructures that support data processing, storage, and analysis. In this article, we will explore the benefits of leveraging IaC for dataengineering projects and provide detailed implementation steps to get started.
DataEngineers of Netflix?—?Interview Interview with Samuel Setegne Samuel Setegne This post is part of our “DataEngineers of Netflix” interview series, where our very own dataengineers talk about their journeys to DataEngineering @ Netflix. What drew you to Netflix?
The data community is striving to incorporate the core concepts of engineering rigor found in software communities but still has further to go. This is achieved through practices like Infrastructure as Code for deployments, automated testing, application observability, and end-to-end application lifecycle ownership.
One of the main reasons this feature exists is just like with food samples, to give you “a taste” of the production quality ETL code that you could encounter inside the Netflix data ecosystem. " , country_code STRING COMMENT "Country code of the playback session." Let’s review the transformation steps below.
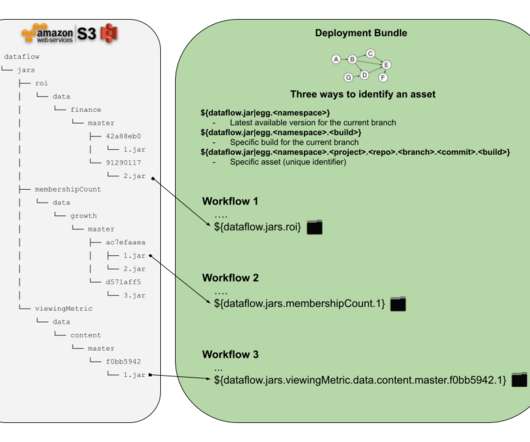
any business logic code in a raw (e.g. JAR) form to be executed as part of the user defined data pipeline. data pipeline ?—?a DAG) for the purpose of transforming data using some business logic. Or what if Alice wanted to add new backup functionality and she accidentally broke existing code while updating it?
coding, math, stats), and do what’s required to answer the highest priority business questions. The Engineer enjoys making data available by piping it in from new sources in optimal ways, building robust data models, prototyping systems, and doing project-specific engineering.
IT automation is the practice of using coded instructions to carry out IT tasks without human intervention. At its most basic, automating IT processes works by executing scripts or procedures either on a schedule or in response to particular events, such as checking a file into a code repository. What is IT automation?
While our engineering teams have and continue to build solutions to lighten this cognitive load (better guardrails, improved tooling, …), data and its derived products are critical elements to understanding, optimizing and abstracting our infrastructure. Give us a holler if you are interested in a thought exchange.
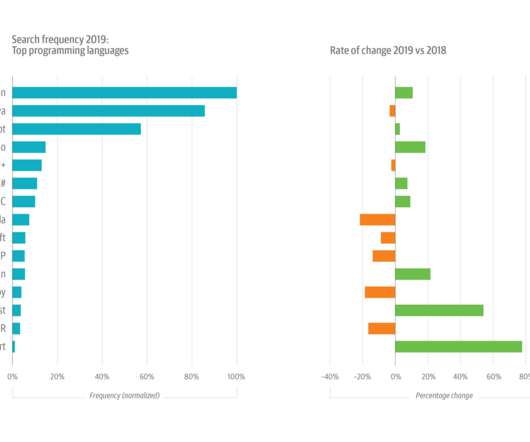
The results for data-related topics are both predictable and—there’s no other way to put it—confusing. Starting with dataengineering, the backbone of all data work (the category includes titles covering data management, i.e., relational databases, Spark, Hadoop, SQL, NoSQL, etc.). This follows a 3% drop in 2018.
At Netflix, our data scientists span many areas of technical specialization, including experimentation, causal inference, machine learning, NLP, modeling, and optimization. Together with data analytics and dataengineering, we comprise the larger, centralized Data Science and Engineering group.
As the scale of the messages being processed increased and we were making more code changes in the message processor, we found ourselves looking for something more flexible. That Pushy delivers the message to the target device (4), and the original Pushy will receive a status code in response, which it can pass back to the source device (5).
These challenges are currently addressed in suboptimal and less cost efficient ways by individual local teams to fulfill the needs, such as Lookback: This is a generic and simple approach that dataengineers use to solve the data accuracy problem. Users configure the workflow to read the data in a window (e.g.
a dynamic Asset Inventory that understands the nuances of our bespoke engineering ecosystem and how our applications and data relate to each other. This has evolved their identity to be a software engineering team that focuses on security problems as opposed to a security engineering team that writes code/software.
It is a general-purpose workflow orchestrator that provides a fully managed workflow-as-a-service (WAAS) to the data platform at Netflix. It serves thousands of users, including data scientists, dataengineers, machine learning engineers, software engineers, content producers, and business analysts, for various use cases.
Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes. Our intuitive software allows dataengineers to maintain pipelines without writing code, and lets analysts gain access to data in minutes instead of months.
Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes. Our intuitive software allows dataengineers to maintain pipelines without writing code, and lets analysts gain access to data in minutes instead of months.
First, the behavior of an AI application depends on a model , which is built from source code and training data. A model isn’t source code, and it isn’t data; it’s an artifact built from the two. This means that, to have a history of how an application was developed, you have to look at more than the source code.
Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes. Our intuitive software allows dataengineers to maintain pipelines without writing code, and lets analysts gain access to data in minutes instead of months.
Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes. Our intuitive software allows dataengineers to maintain pipelines without writing code, and lets analysts gain access to data in minutes instead of months.
Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes. Our intuitive software allows dataengineers to maintain pipelines without writing code, and lets analysts gain access to data in minutes instead of months.
Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes. Our intuitive software allows dataengineers to maintain pipelines without writing code, and lets analysts gain access to data in minutes instead of months.
Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes. Our intuitive software allows dataengineers to maintain pipelines without writing code, and lets analysts gain access to data in minutes instead of months.
A role in data science eventually seemed like a natural transition, but it wasn’t without its hurdles: With my consulting background, I had to go through a few other roles first while learning how to code on the side.
Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes. Our intuitive software allows dataengineers to maintain pipelines without writing code, and lets analysts gain access to data in minutes instead of months.
Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes. Our intuitive software allows dataengineers to maintain pipelines without writing code, and lets analysts gain access to data in minutes instead of months.
Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes. Our intuitive software allows dataengineers to maintain pipelines without writing code, and lets analysts gain access to data in minutes instead of months.
It’s not about getting software developers to write code faster. Perhaps the appropriate yardstick for AI projects is the experiment itself, not the code committed to git.). Key survey results: The C-suite is engaged with data quality. Data quality might get worse before it gets better. Can Agile work for large teams?
Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes. Our intuitive software allows dataengineers to maintain pipelines without writing code, and lets analysts gain access to data in minutes instead of months.
Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes. Our intuitive software allows dataengineers to maintain pipelines without writing code, and lets analysts gain access to data in minutes instead of months.
Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes. Our intuitive software allows dataengineers to maintain pipelines without writing code, and lets analysts gain access to data in minutes instead of months.
Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes. Our intuitive software allows dataengineers to maintain pipelines without writing code, and lets analysts gain access to data in minutes instead of months.
Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes. Our intuitive software allows dataengineers to maintain pipelines without writing code, and lets analysts gain access to data in minutes instead of months.
Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes. Our intuitive software allows dataengineers to maintain pipelines without writing code, and lets analysts gain access to data in minutes instead of months.
There are no hard-and-fast rules to figure out interdependency between technology architecture and engineering organization but below is what I think can really work well for product startup. At this stage you can use CI/CD tooling provide by source code hosting platform (Github, Gitlab) or a SaaS solution like CircleCI.
I entered a PhD program in Computer Science and shortly thereafter discovered I really liked the coding aspects more than the theory. Writing code (SQL, Python) ???? So I earned the honor of being a PhD dropout. A visual representation of all the hats I’ve worn And here’s where things started to click! if such a thing even exists!
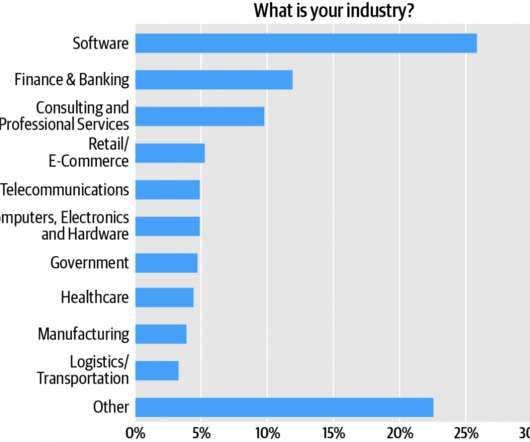
Technical roles represented in the “Other” category include IT managers, dataengineers, DevOps practitioners, data scientists, systems engineers, and systems administrators. Just under 44% cited the benefit of “better overall scalability,” followed (43%) by “more frequent code refreshes.” Footnotes.
There are shadow IT teams of developers or dataengineers that spring up in areas like operations or marketing because the captive IT function is slow, if not outright incapable, of responding to internal customer demand. There are also shadow activities of large software delivery programs. The scope taken out of the 1.0
While BI solutions have existed for decades, customers have told us that it takes an enormous amount of time, engineering effort, and money to bridge this gap. These solutions lack interactive data exploration and visualization capabilities, limiting most business users to canned reports and pre-selected queries.
SUS209 — there was no talk with this code. STP213 Scaling global carbon footprint management — Blake Blackwell Persefoni Manager DataEngineering and Michael Floyd AWS Head of Sustainability Solutions. SUS304 to SUS311 No talks with these codes. Good example, well presented interesting new material.
Unfortunately, building data pipelines remains a daunting, time-consuming, and costly activity. Not everyone is operating at Netflix or Spotify scale dataengineering function. Often companies underestimate the necessary effort and cost involved to build and maintain data pipelines.
The engineering organisation described may not work for you because of a team of 8-10 people is still a very big overhead. In this model, software architecture and code ownership is a reflection of the organisational model. Thirdly, let engineers themselves choose the delivery teams and organise them around the initiative.
There are hundreds of tools through which the automation code can be written in different programming languages. Udacity Udacity provides nanodegree programs on all automation languages like C++, Machine Learning, Dataengineer, Robotics and more.
This was a good, balanced, assessment, and it was fascinating to see Pulumi’s “code over template” approach. From dataengineering, to cost management, via conversations about team dynamics and architecture, we like to get involved with all-things-cloud-and-DevOps related at our clients. I wholeheartedly agree.
Machine learning models can construct entities and associated relationships purely based on the data and signals embedded deep inside the data, or alter the existing entities and relationships in real-time to adopt against the addition of a new data source all while utilizing a probabilistic/statistical model.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content