This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
How To Design For High-Traffic Events And Prevent Your Website From Crashing How To Design For High-Traffic Events And Prevent Your Website From Crashing Saad Khan 2025-01-07T14:00:00+00:00 2025-01-07T22:04:48+00:00 This article is sponsored by Cloudways Product launches and sales typically attract large volumes of traffic.
More organizations than ever are undertaking cloud migration as digital transformation continues to gain momentum across every industry in every region. But what does it take to migrate your existing applications to the cloud? What is cloud migration? However, it can also mean migrating from one cloud to another.
A quick canary test was free of errors and showed lower latency, which is expected given that our standard canary setup routes an equal amount of traffic to both the baseline running on 4xl and the canary on 12xl. What’s worse, average latency degraded by more than 50%, with both CPU and latency patterns becoming more “choppy.”
Where you decide to host your cloud databases is a huge decision. You have to choose your hosting model, a cloud provider, and then your primary and standby regions to deploy to. What is ScaleGrid’s Bring Your Own Cloud Plan? Here are the databases and cloud providers supported through each model: Supported Databases.
Scaling RabbitMQ ensures your system can handle growing traffic and maintain high performance. Optimizing RabbitMQ performance through strategies such as keeping queues short, enabling lazy queues, and monitoring health checks is essential for maintaining system efficiency and effectively managing high traffic loads.
Its partitioned log architecture supports both queuing and publish-subscribe models, allowing it to handle large-scale event processing with minimal latency. Apache Kafka uses a custom TCP/IP protocol for high throughput and low latency. However, performance can decline under high traffic conditions.
With cloud deployments growing rapidly during the past few years and enterprise multi-cloud environments becoming the norm, new challenges have emerged, including: Cloud dynamics make it hard to keep up with autoscaling, where services come and go based on demand. Azure Traffic Manager. Dynatrace news. Azure Batch.
Across the board, the topics cloud migration, application modernization, breaking the monolith or hybrid cloud re-platforming have been a center point in many of our discussions with our joint enterprise customers. Resource consumption & traffic analysis. It covers these key areas: Technology & Dependency Analysis.
SREs use Service-Level Indicators (SLI) to see the complete picture of service availability, latency, performance, and capacity across various systems, especially revenue-critical systems. While this empowers teams to frequently deliver new features, the overall business, security, and quality objectives must be maintained. What’s next?
How site reliability engineering affects organizations’ bottom line SRE applies the disciplines of software engineering to infrastructure management, both on-premises and in the cloud. However, cloud complexity has made software delivery challenging. Visibility and automation are two of the most important SRE tools.
We thus assigned a priority to each use case and sharded event traffic by routing to priority-specific queues and the corresponding event processing clusters. This separation allows us to tune system configuration and scaling policies independently for different event priorities and traffic patterns.
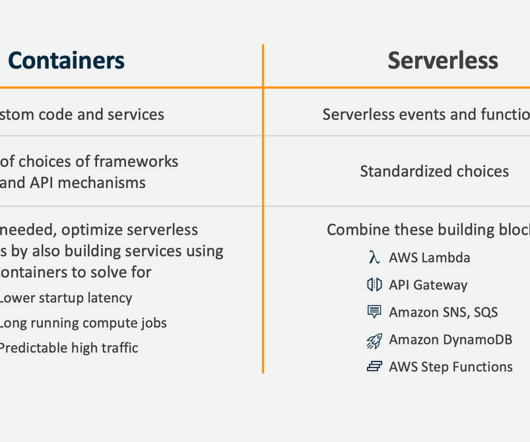
As companies accelerate digital transformation, they implement modern cloud technologies like serverless functions. According to Flexera , serverless functions are the number one technology evaluated by enterprises and one of the top five cloud technologies in use at enterprises. And serverless support is a core capability.
How viewers are able to watch their favorite show on Netflix while the infrastructure self-recovers from a system failure By Manuel Correa , Arthur Gonigberg , and Daniel West Getting stuck in traffic is one of the most frustrating experiences for drivers around the world. Logs and background requests are examples of this type of traffic.
Applying the DORA framework is especially challenging as organizations move more workloads to the cloud and manage sprawling hybrid and multi-cloud environments. Delivering financial services requires a complex landscape of applications, hybrid cloud infrastructure, and third-party vendors.
It's HighScalability time: Instead of turning every car into rolling sensor studded supercomputers, roads could be festooned with stationary edge command and control pods for offloading compute, sensing and managing traffic. Solves compute, latency, and interop. You'll be a real cloud hero. Do you like this sort of Stuff?
by Tomasz Bak and Fabio Kung Introduction Titus is the Netflix cloud container runtime that runs and manages containers at scale. In that scenario, the system would need to deal with the data propagation latency directly, for example, by use of timeouts or client-originated update tracking mechanisms.
How we migrated our Android endpoints out of a monolith into a new microservice by Rohan Dhruva , Ed Ballot As Android developers, we usually have the luxury of treating our backends as magic boxes running in the cloud, faithfully returning us JSON. Replay Testing Enter replay testing.
In their new dashboard, they added dimensions for load, latency, and open problems for each component. The “Four Golden Signals” include the following: Latency. For example, one dashboard is broken down by cloud hosting provider. SLO dashboard defined by architectural boundary. This is the number of requests that fail.
These include challenges with tail latency and idempotency, managing “wide” partitions with many rows, handling single large “fat” columns, and slow response pagination. It also serves as central configuration of access patterns such as consistency or latency targets. Useful for keeping “n-newest” or prefix path deletion.
Complementing the hardware is the software on the RAE and in the cloud, and bridging the software on both ends is a bi-directional control plane. Since Kafka is a supported messaging platform at Netflix, a bridge is established between the two protocols to allow cloud-side services to communicate with the control plane.
While you may assume a great majority of the cloud database deployments are run on AWS, Azure, or Google Cloud Platform, small to medium-sized businesses in particular are gravitating towards the developer-friendly cloud provider, DigitalOcean , for their hosting for MongoDB® needs. DigitalOcean Droplets.
Exploring artificial intelligence in cloud computing reveals a game-changing synergy. This article delves into the specifics of how AI optimizes cloud efficiency, ensures scalability, and reinforces security, providing a glimpse at its transformative role without giving away extensive details.
A brief history of IPC at Netflix Netflix was early to the cloud, particularly for large-scale companies: we began the migration in 2008, and by 2010, Netflix streaming was fully run on AWS. Today we have a wealth of tools, both OSS and commercial, all designed for cloud-native environments.
When you’re running in the cloud your containers are in a shared space; in particular they share the CPU’s memory hierarchy of the host instance. These applications range from critical low-latency services powering our customer-facing video streaming service, to batch jobs for encoding or machine learning.
Netflix shares how Amazon EC2 Auto Scaling allows its infrastructure to automatically adapt to changing traffic patterns in order to keep its audience entertained and its costs on target. Netflix runs dozens of stateful services on AWS under strict sub-millisecond tail-latency requirements, which brings unique challenges. Wednesday?—?December
This enables customers to serve content to their end users with low latency, giving them the best application experience. In 2008, AWS opened a point of presence (PoP) in Hong Kong to enable customers to serve content to their end users with low latency. Since then, AWS has added two more PoPs in Hong Kong, the latest in 2016.
With DEM solutions, organizations can operate over on-premise network infrastructure or private or public cloud SaaS or IaaS offerings. STM generates traffic that replicates the typical path or behavior of a user on a network to measure performance for example, response times, availability, packet loss, latency, jitter, and other variables).
You may already be using it daily and find it makes running applications in the cloud much more manageable. It simplifies infrastructure management and is the driving force behind many cloud-native applications and services. It has become the industry standard for cloud-native container orchestration.
They can run applications in Sweden, serve end users across the Nordics with lower latency, and leverage advanced technologies such as containers, serverless computing, and more. In addition, we are working with the venture capital community, startup accelerators, and incubators to help startups grow in the cloud. " Hemnet.
The AWS GovCloud (US-East) Region is our second AWS GovCloud (US) Region, joining AWS GovCloud (US-West) to further help US government agencies, the contractors that serve them, and organizations in highly regulated industries move more of their workloads to the AWS Cloud by implementing a number of US government-specific regulatory requirements.
Cross Region Read Replicas also enable you to serve read traffic for your global customer base from regions that are nearest to them. Up until AWS and the Cloud, reliable Disaster Recovery had largely remained cost prohibitive for most companies excepting for large enterprises.
This architecture shift greatly reduced the processing latency and increased system resiliency. We expanded pipeline support to serve our studio/content-development use cases, which had different latency and resiliency requirements as compared to the traditional streaming use case. divide the input video into small chunks 2.
What is workload in cloud computing? Simply put, it’s the set of computational tasks that cloud systems perform, such as hosting databases, enabling collaboration tools, or running compute-intensive algorithms. The environments, which were previously isolated, are now working seamlessly under central control.
While infrastructure has historically been treated as a bottleneck where proper scaling and compute power are applied to improve performance, these aspects are now typically addressed by hyperscalers that offer cloud-based infrastructure and infrastructure as a service.
DynamoDB is the result of 15 years of learning in the areas of large scale non-relational databases and cloud services. s web-based applications often encounter database scaling challenges when faced with growth in users, traffic, and data. Amazon DynamoDB offers low, predictable latencies at any scale.
Organizations across Italy have been using the AWS Cloud for over a decade, using AWS Regions located outside of Italy. We have offices in Rome and Milan, where we continue to help Italian customers of all sizes move to the AWS Cloud. The company decided it wanted the scalability, flexibility, and cost benefits of working in the cloud.
Then they tried to scale it to cope with high traffic and discovered that some of the state transitions in their step functions were too frequent, and they had some overly chatty calls between AWS lambda functions and S3. They state in the blog that this was quick to build, which is the point.
If we had an ID for each streaming session then distributed tracing could easily reconstruct session failure by providing service topology, retry and error tags, and latency measurements for all service calls. Using simple lookup indices in Cassandra gives us the ability to maintain acceptable read latencies while doing heavy writes.
Expanding the Cloud â?? This new Asia Pacific (Sydney) Region has been highly requested by companies worldwide, and it provides low latency access to AWS services for those who target customers in Australia and New Zealand. All Things Distributed. Werner Vogels weblog on building scalable and robust distributed systems. Comments ().
It is available for the major OS and cloud platforms (for example, Windows, Linux, Solaris, AWS, Azure, and more) and only requires the deployment of a single service to monitor its environment. And that’s where Dynatrace OneAgent comes in. What is OneAgent? On the other hand, if we checked out the process page for our Node.js
In this fast-paced ecosystem, two vital elements determine the efficiency of this traffic: latency and throughput. LATENCY: THE WAITING GAME Latency is like the time you spend waiting in line at your local coffee shop. All these moments combined represent latency – the time it takes for your order to reach your hands.
We are standing on the eve of the 5G era… 5G, as a monumental shift in cellular communication technology, holds tremendous potential for spurring innovations across many vertical industries, with its promised multi-Gbps speed, sub-10 ms low latency, and massive connectivity. Throughput and latency. energy consumption).
That’s a significant amount and certainly more than is necessary relative to the traffic on most clusters. More acutely, if a traffic spike occurs and Zuul instances scale up, it exponentially increases connections open to origins. There is effectively no churn of connections, even at peak traffic.
Harnessing DNS for traffic steering, load balancing, and intelligent response. When designing cloud architecture, it’s critical to consider that your applications could be affected by failures and that you must be prepared to respond to those failures quickly and effectively.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content