This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
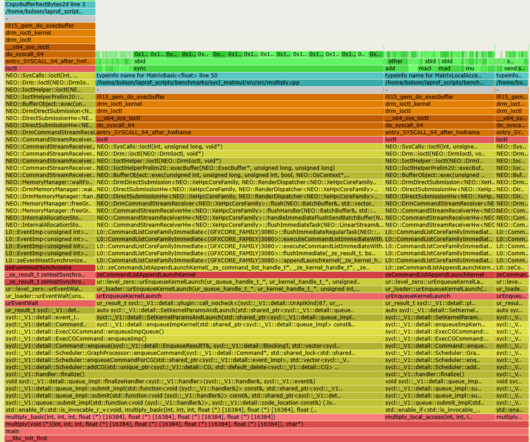
At Intel we've been creating a new analyzer tool to help reduce AI costs called AI Flame Graphs : a visualization that shows an AI accelerator or GPU hardware profile along with the full software stack, based on my CPU flame graphs. Here is an example: Simple example: SYCL matrix multiply microbenchmark (Click for interactive SVG.)
VMware commercialized the idea of virtual machines, and cloud providers embraced the same concept with services like Amazon EC2, Google Compute, and Azure virtual machines. Serverless computing is a cloud-based, on-demand execution model where customers consume resources solely based on their application usage.
The IBM Z platform is a range of mainframe hardware solutions that are quite frequently used in large computing shops. Typically, these shops run the z/OS operating system, but more recently, it’s not uncommon to see the Z hardware running special versions of Linux distributions. Stay tuned for more announcements on this topic.
If cloud-native technologies and containers are on your radar, you’ve likely encountered Docker and Kubernetes and might be wondering how they relate to each other. Docker Engine is built on top containerd , the leading open-source container runtime, a project of the Cloud Native Computing Foundation (DNCF). Dynatrace news.
Compare ease of use across compatibility, extensions, tuning, operating systems, languages and support providers. Cloud Deployments. Can be deployed on any cloud provider, with a variety of PostgreSQL hosting solutions available. Compare PostgreSQL vs. Oracle functionality across available tools, capabilities and services.
Optimizing RabbitMQ requires clustering, queue management, and resource tuning to maintain stability and efficiency. Several factors impact RabbitMQs responsiveness, including hardware specifications, network speed, available memory, and queue configurations. RabbitMQ ensures fast message delivery when queues are not overloaded.
Log monitoring, log analysis, and log analytics are more important than ever as organizations adopt more cloud-native technologies, containers, and microservices-based architectures. Driving this growth is the increasing adoption of hyperscale cloud providers (AWS, Azure, and GCP) and containerized microservices running on Kubernetes.
Following the innovation of microservices, serverless computing is the next step in the evolution of how applications are built in the cloud. With Azure Functions, engineers don’t have to worry about provisioning and maintaining underlying hardware; they simply upload their code, and it’s up and running seconds later. So stay tuned!
Limits of a lift-and-shift approach A traditional lift-and-shift approach, where teams migrate a monolithic application directly onto hardware hosted in the cloud, may seem like the logical first step toward application transformation. However, the move to microservices comes with its own challenges and complexities.
The IBM Z platform is a range of mainframe hardware solutions that are quite frequently used in large computing shops. Typically, these shops run the z/OS operating system, but more recently, it’s not uncommon to see the Z hardware running special versions of Linux distributions. Stay tuned for more announcements on this topic.
The agencies resisted adopting the tool because it required significant time to configure and tune collected metrics into valuable information. The obvious costs of tool sprawl can quickly add up, including licensing, support, maintenance, training, hardware, and often additional headcount. Register to listen to the webinar.
The evolution of cloud-native technology has been nothing short of revolutionary. As we step into 2024, the cornerstone of cloud-native technology, Kubernetes, will turn ten years old. Keynotes were focused on how Kubernetes and Cloud Native help businesses embrace the new AI era. We expect that number to rise higher in 2024.
Following the innovation of microservices, serverless computing is the next step in the evolution of how applications are built in the cloud. With Azure Functions, engineers don’t have to worry about provisioning and maintaining underlying hardware; they simply upload their code, and it’s up and running seconds later. So stay tuned!
This is especially the case with microservices and applications created around multiple tiers, where cheaper hardware alternatives play a significant role in the infrastructure footprint. We understand the dependencies between the mainframe, data center, and cloud, including all application components and even end-user experience.
Hardware Memory The amount of RAM to be provisioned for database servers can vary greatly depending on the size of the database and the specific requirements of the company. Cloud Different cloud providers offer a range of instance types and sizes, each with varying amounts of CPU, memory, and storage.
Such applications track the inventory of our network gear: what devices, of which models, with which hardware components, located in which sites. Demand Engineering Demand Engineering is responsible for Regional Failovers , Traffic Distribution, Capacity Operations and Fleet Efficiency of the Netflix cloud.
This centralized approach reduces your hardware imprint as well as configuration effort, making your work easier and more cost-effective. Stay tuned for more Synthetic Monitoring news, including: Credential vault support for HTTP monitors. New public Synthetic locations from already supported cloud vendors. What’s next?
AV1 playback on TV platforms relies on hardware solutions, which generally take longer to be deployed. Throughout 2020 the industry made impressive progress on AV1 hardware solutions. The Encoding Technologies team took a first stab at this problem by fine-tuning the encoding recipe. Stay tuned!
By Vikram Srivastava and Marcelo Mayworm Netflix has one of the most complex data platforms in the cloud on which our data scientists and engineers run batch and streaming workloads. This has led to a dramatic reduction in the time it takes to detect issues in hardware or bugs in recently rolled out data platform software.
When configuring a RabbitMQ cluster, consider the availability zones and cloud regions to ensure high availability. With 24/7 expert support, ScaleGrid assists with troubleshooting, performance tuning, and migration processes. Each RabbitMQ node must be stopped before it can join an existing cluster.
Complementing the hardware is the software on the RAE and in the cloud, and bridging the software on both ends is a bi-directional control plane. When a new hardware device is connected, the Local Registry detects and collects a set of information about it, such as networking information and ESN.
Default settings can help you get started quickly – but they can also cost you performance and a higher cloud bill at the end of the month. I’ll show you some MySQL settings to tune to get better performance, and cost savings, with AWS RDS. Want to save money on your AWS RDS bill?
Tom Davidson, Opening Microsoft's Performance-Tuning Toolbox SQL Server Pro Magazine, December 2003. Waits and Queues has been used as a SQL Server performance tuning methodology since Tom Davidson published the above article as well as the well-known SQL Server 2005 Waits and Queues whitepaper in 2006. The Top Queries That Weren't.
The same model will run in the cloud at a reasonable cost without specialized servers. These smaller distilled models can run on off-the-shelf hardware without expensive GPUs. And they can do useful work, particularly if fine-tuned for a specific application domain.
assigning to a specific CPU) is a manageable resource, represented by the concept of “virtual CPU” as a term that includes CPU cores, hyperthreads, hardware threads, and so forth. Then we need to see IF implementing the tuning will work or not. It is possible to do more tuning in the case that ETL is too compromised.
Out of the box, the default PostgreSQL configuration is not tuned for any particular workload. It is primarily the responsibility of the database administrator or developer to tune PostgreSQL according to their system’s workload. What is PostgreSQL performance tuning? Why is PostgreSQL performance tuning important?
– Cloud. Cloud seriously impacts system architectures that has a lot of performance-related consequences. To get full advantage of cloud, such cloud-specific features as auto-scaling should be implemented. System’s configuration is not given anymore and often can’t be easily mapped to hardware. – Agile.
Cloud computing? Doubly so as hardware improved, eating away at the lower end of Hadoop-worthy work. And just as we started to complain that the crypto miners were snapping up all of the affordable GPU cards, cloud providers stepped up to offer access on-demand. Not that you’ll even need GPU access all that often.
Resource allocation: Personnel, hardware, time, and money The migration to open source requires careful allocation (and knowledge) of the resources available to you. Evaluating your hardware requirements is another vital aspect of resource allocation. Look closely at your current infrastructure (hardware, storage, networks, etc.)
Even with cloud-based foundation models like GPT-4, which eliminate the need to develop your own model or provide your own infrastructure, fine-tuning a model for any particular use case is still a major undertaking. This is an area where cloud providers already bear much of the burden, and will continue to bear it in the future.
As we saw with the SOAP paper last time out, even with a fixed model variant and hardware there are a lot of different ways to map a training workload over the available hardware. Different hardware architectures (CPUs, GPUs, TPUs, FPGAs, ASICs, …) offer different performance and cost trade-offs.
As a Xen guest, this profile was gathered using perf(1) and the kernel's software cpu-clock soft interrupts, not the hardware NMI. That chance encounter, coupled with the Netflix's fault-tolerant cloud, gave me enough confidence to suggest trying tsc in production as a workaround for the issue. But I'm not completely sure.
Linux has been adding tracing technologies over the years: kprobes (kernel dynamic tracing), uprobes (user-level dynamic tracing), tracepoints (static tracing), and perf_events (profiling and hardware counters). The way the cloud is used helps with security: most instances at my employer have only been up for one or two days.
Regardless of whether the computing platform to be evaluated is on-prem, containerized, virtualized, or in the cloud, it is crucial to consider several essential factors. There are many times we get asked why some cloud instance performed poorly for their database application and almost always turned out to be some configuration error.
those resources now belong to cloud providers, such as AWS Lambda, Google Cloud Platform, Microsoft Azure, and others. Again, the benefit being that the code within your containers or virtual machines is managed by the cloud provider. When code isn’t in use, the cloud providers typically throttle it all the way down.
The data shape will dictate capacity planning, tuning of the backbone, and scalability analysis for individual components. It enables unbounded scalability as more commodity or specialized hardware can be seamlessly added to existing clusters. What message process warranty level do we require? At least once? At most once? Exactly once?
These nodes and edges require a good amount of compute and storage which is typically distributed across a large number servers either running in the cloud or your own data center. A data pipeline is a software which runs on hardware. The software is error-prone and hardware failures are inevitable.
I’ve been diligent about data backup throughout my life, but my files are fragmented amongst different media over the years—burning CDs and DVDs back in the day, several generations of external hard drives (that are in various states of decay), university servers, Dropbox, and other cloud services.
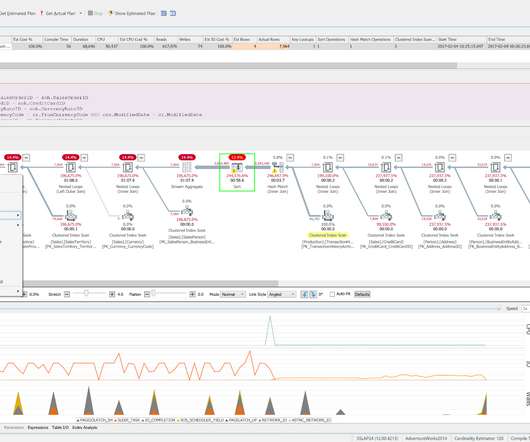
As the chart shows because we know that both HammerDB and the implementation of the TPC-C workload scales then we can determine that with this particular database engine both the software and hardware scales as well. If you only test your own application (and if you have more than one application which one will you use for benchmarking?)
This is basically the position of the major cloud providers, they will all take care of it for you by 2030 or so. I’ve written before about how to tune out retry storms. For an example of an unintended consequence, let’s say the result of your optimization project is spare capacity at a cloud provider.
Both have an excellent customer base, are fully Cloud native solutions and root on a long-standing history. Verify hardware sizing. Make application tuning much easier. They simulate actual and future growth pattern on pre-production stages, identify and fix hotspots and deploy those tuned application into production.
Before you begin tuning your website or application, you must first figure out which metrics matter most to your users and establish some achievable benchmarks. The cloud-based service sends massive numbers of requests per second to simulate how your website holds up. What is Performance Testing?
On multi-core machines – which is the majority of the hardware nowadays – and in the cloud, we have multiple cores available for use. Multiple queries run at the same time will be using different threads and will utilize more than one CPU core. With faster disks (i.e. AWS Aurora (based on MySQL 5.6)
As a Xen guest, this profile was gathered using perf(1) and the kernel's software cpu-clock soft interrupts, not the hardware NMI. That chance encounter, coupled with the Netflix's fault-tolerant cloud, gave me enough confidence to suggest trying tsc in production as a workaround for the issue. But I'm not completely sure.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content