This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Deliver high-quality, cloud-native applications to accelerate innovation. Overcome the complexity of cloud-native environments and stay ahead of regulatory reporting rules by automating continuous discovery, proactive anomaly detection, and optimization across the software development lifecycle.
5 FedRAMP (Federal Risk and Authorization Management Program) is a government program that provides a standardized approach to security assessment, authorization, and continuous monitoring for cloud products and services for U.S. These exercises go beyond penetration testing by targeting multiple systems and potential avenues of attack.
—?Mounting object storage in Netflix’s media processing platform By Barak Alon (on behalf of Netflix’s Media Cloud Engineering team) MezzFS (short for “Mezzanine File System”) is a tool we’ve developed at Netflix that mounts cloud objects as local files via FUSE. Encoding is not a one-time process?—?large
AIOps combines big data and machine learning to automate key IT operations processes, including anomaly detection and identification, event correlation, and root-cause analysis. To achieve these AIOps benefits, comprehensive AIOps tools incorporate four key stages of data processing: Collection. What is AIOps, and how does it work?
Across the two days, there were sixteen new sessions – delivered for the first time – based on content derived from lab exercises developed and delivered by working with Dynatrace experts and our Partner communicate to showcase Dynatrace’s newest features. You can see a similar automation process on this GitHub repo.
Fermentation process: Steve Amos, IT Experience Manager at Vitality spoke about how the health and life insurance market is now busier than ever. As a company that’s ethos is based on a points-based system for health, by doing exercise and being rewarded with vouchers such as cinema tickets, the pandemic made both impossible tasks to do.
HashiCorp’s Terraform is an open-source infrastructure as a code software tool that provides a consistent CLI workflow to manage hundreds of cloud services. Terraform codifies cloud APIs into declarative configuration files. It has now become a parallel exercise in the same CLI. What is monitoring as code? Step 2: Plan.
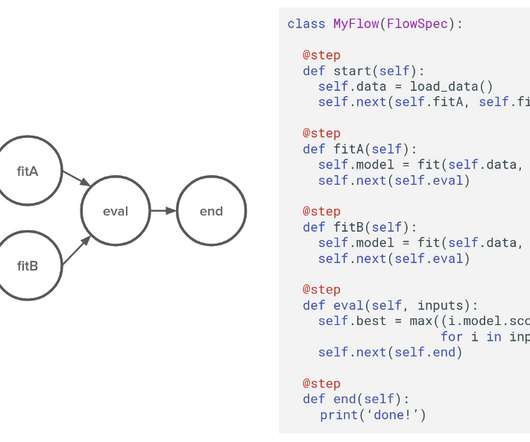
We heard many stories about difficulties related to data access and basic data processing. The infrastructure should allow them to exercise their freedom as data scientists but it should provide enough guardrails and scaffolding, so they don’t have to worry about software architecture too much. Metaflow is a cloud-native framework.
During the recent pandemic, organizations that lack processes and systems to scale and adapt to remote workforces and increased online shopping are feeling the pressure even more. Rethinking the process means digital transformation. Different teams have their own siloed monitoring solution.
Hosted and moderated by Amazon, AWS GameDay is a hands-on, collaborative, gamified learning exercise for applying AWS services and cloud skills to real-world scenarios. Major cloud providers such as AWS offer certification programs to help technology professionals develop and mature their cloud skills.
This is especially true when we consider the explosive growth of cloud and container environments, where containers are orchestrated and infrastructure is software defined, meaning even the simplest of environments move at speeds beyond manual control, and beyond the speed of legacy Security practices.
The SEC cybersecurity mandate states that starting December 15 th , all public organizations are required to annually describe their processes for assessing, identifying, and managing material risks from any cybersecurity threats on a Form 10-K. Additionally, ensure they are aware of each of their roles and responsibility during the process.
You apply for multiple roles at the same company and proceed through the interview process with each hiring team separately, despite the fact that there is tremendous overlap in the roles. Interviewing can be a daunting endeavor and how companies, and teams, approach the process varies greatly.
As organizations adopt microservices architecture with cloud-native technologies such as Microsoft Azure , many quickly notice an increase in operational complexity. To guide organizations through their cloud migrations, Microsoft developed the Azure Well-Architected Framework. Cost optimization.
Traditional application security measures are not living up to the challenges presented by dynamic and complex cloud-native architectures and rapid software release cycles. When considering DevOps vs DevSecOps, it becomes obvious that both look to integrate disparate processes using a combination of agility and automation.
Migrating a message-based system from on-premises to the cloud is a colossal undertaking. If you search for “how to migrate to the cloud”, there are reams of articles that encourage you to understand your system, evaluate cloud providers, choose the right messaging service, and manage security and compliance.
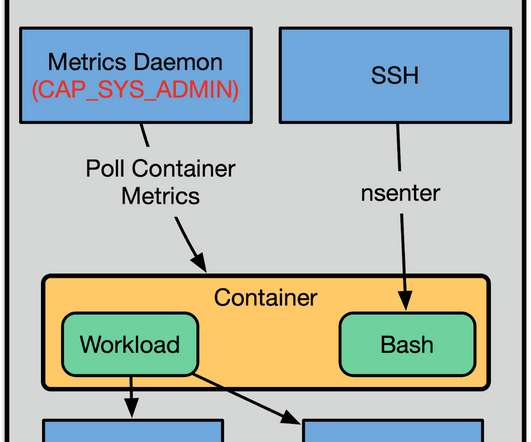
For example, the PID namespace makes it so that a process can only see PIDs in its own namespace, and therefore cannot send kill signals to random processes on the host. There are also more common capabilities that are granted to users like CAP_NET_RAW, which allows a process the ability to open raw sockets. User Namespaces.
While Google’s SRE Handbook mostly focuses on the production use case for SLIs/SLOs, Keptn is “Shifting-Left” this approach and using SLIs/SLOs to enforce Quality Gates as part of your progressive delivery process. This will enable deep monitoring of those Java,NET, Node, processes as well as your web servers.
How we migrated our Android endpoints out of a monolith into a new microservice by Rohan Dhruva , Ed Ballot As Android developers, we usually have the luxury of treating our backends as magic boxes running in the cloud, faithfully returning us JSON. The thoroughness and flexibility of this replay pipeline is best described in its own post.
Here’s what we discussed so far: In Part 1 we explored how DevOps teams can prevent a process crash from taking down services across an organization. In doing so, they automate build processes to speed up delivery, and minimize human involvement to prevent error. But now you realize it doesn’t work well with the other services running.
At Dynatrace, our Autonomous Cloud Enablement (ACE) team are the coaches or teach and train our customers to always get the best out of Dynatrace and reach their objectives. In our exercise: Metric 1 (Number of requests with a response time > 1 second): requires the creation of a calculated metric with the right filter.
We heard many stories about difficulties related to data access and basic data processing. The infrastructure should allow them to exercise their freedom as data scientists but it should provide enough guardrails and scaffolding, so they don’t have to worry about software architecture too much. Metaflow is a cloud-native framework.
However, with today’s highly connected digital world, monitoring use cases expand to the services, processes, hosts, logs, networks, and of course, end-users that access these applications — including a company’s customers and employees. Why cloud-native applications make APM challenging. What does APM stand for?
The voice service then constructs a message for the device and places it on the message queue, which is then processed and sent to Pushy to deliver to the device. Where aws ends and the internet begins is an exercise left to the reader. Security As the edge of the Netflix cloud, security considerations are always top of mind.
Expanding the Cloud - Adding the Incredible Power of the Amazon EC2 Cluster GPU Instances. From financial processing and traditional oil & gas exploration HPC applications to integrating complex 3D graphics into online and mobile applications, the applications of GPU processing appear to be limitless. Comments ().
While there isn’t an authoritative definition for the term, it shares its ethos with its predecessor, the DevOps movement in software engineering: by adopting well-defined processes, modern tooling, and automated workflows, we can streamline the process of moving from development to robust production deployments.
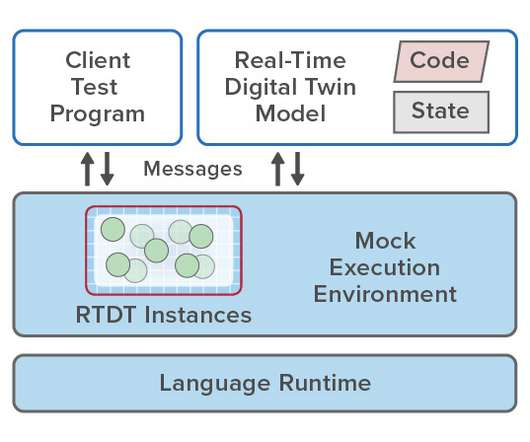
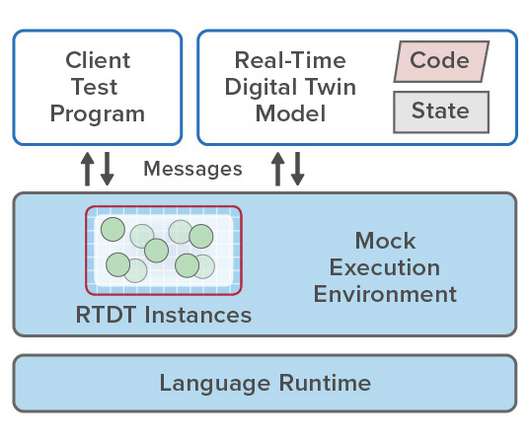
Simplifying the Development Process with Mock Environments. This blog post explains how a new software construct called a real-time digital twin running in a cloud-hosted service can create a breakthrough for streaming analytics. Debugging with a Mock Environment.
Simplifying the Development Process with Mock Environments. This blog post explains how a new software construct called a real-time digital twin running in a cloud-hosted service can create a breakthrough for streaming analytics. Debugging with a Mock Environment.
" Of course, no technology change happens in isolation, and at the same time NoSQL was evolving, so was cloud computing. The requirements for a fully hosted cloud database service needed to be at an even higher bar than what we had set for our Amazon internal system. Auto Scaling is on by default for all new tables and indexes.
You might say that the outcome of this exercise is a performant predictive model. Second, this exercise in model-building was … rather tedious? Especially when you consider how Certain Big Cloud Providers treat autoML as an on-ramp to model hosting. That’s sort of true. Building a Better for() loop for ML. Damn convenient.
In contrast, a process suffering a total failure can be quickly identified, restarted, or repaired by existing mechanisms, thus limiting the failure impact. 71% of failures are triggered by a specific environment condition, input, or faults in other processes. In 13% of cases a module became a zombie with undefined failure semantics.
Adrian Cockcroft outlines the architectural principles of chaos engineering and shares methods engineers can use to exercise failure modes in safety and business-critical systems. Accelerate application delivery with a cloud-native mindset. Watch " Accelerate application delivery with a cloud-native mindset.".
Across the industry, this includes work being done by individual vendors, that they are then contributing to the standardization process so C++ programmers can use it portably. Background in a nutshell: In C++, code that (usually accidentally) exercises UB is the primary root cause of our memory safety and security vulnerability issues.
The Agile manager does specific things: advances the understanding of the domain, has a symbiotic relationship with the do-ers, creates and adjusts the processes and social systems, and protects the team’s execution. Yes, people still pass this off as “cloud migration”.
Deployment options in the cloud, on-premise, or hybrid configurations. We are here to make the process as seamless as possible; migration is a part of our onboarding process. We are here to make the process as seamless as possible; migration is a part of our onboarding process. Here’s how it works.
Netflix’s system is deployed on the public cloud as complex set of interacting microservices. They use a combination of timeouts, retries, and fallbacks to try to mitigate the effects of these failures, but these don’t get exercised as often as the happy path, so how can we be confident they’ll work as intended when called upon?
Decommissioning Public102 was an exercise in the mundane, gradually transitioning tiny service after tiny service to new homes over the course of weeks, as the development schedule allowed. When finally we had all the processes migrated, we celebrated as we decommissioned Public102. It's not so easy with a junk drawer server.
Regardless of whether the computing platform to be evaluated is on-prem, containerized, virtualized, or in the cloud, it is crucial to consider several essential factors. Instead, focus on understanding what the workloads exercise to help us determine how to best use them to aid our performance assessment.
When SQL Server reads data under locking read committed isolation (the default for non-cloud offerings) and chooses row-level locking granularity, it normally only locks one row at a time. The engine processes the row through parent operators before releasing the shared lock prior to locking and reading the next row.
Some opinions claim that “Benchmarks are meaningless”, “benchmarks are irrelevant” or “benchmarks are nothing like your real applications” However for others “Benchmarks matter,” as they “account for the processing architecture and speed, memory, storage subsystems and the database engine.”
I've worked with quite a few companies for which long-lived software assets remain critical to day-to-day operations, ranging from 20-year-old ERP systems to custom software products that first processed a transaction way back in the 1960s. Several things stand out about these initiatives.
Employees will see replatforming as an exercise in re-creating software. and then we'll change process and organization once it's up and running. Additionally, ambitious replatforming efforts lay bare deficiencies in organization, skills, capability, knowledge, process, and infrastructure. Changing those takes time.
There are many possible failure modes, and each exercises a different aspect of resilience. Staff should be familiar with recovery processes and the behavior of the system when it’s working hard to mitigate failures. The third team is the infrastructure platform team, who deal with datacenter and cloud based resources.
Tracking the processes to plan better. During a testing process, you need to track and plan the testing activities such as: Test planning Test scripts writing Test data creation and management Test versioning, review, and approvals Test case scheduling Test reporting. helps in having a clear picture of the testing process.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content