This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
At Dynatrace we host most of our Dynatrace SaaS clusters for paying customers as well as trial users in the Amazon Web Services (AWS) cloud. The Autonomous Cloud Enablement (ACE) Team at Dynatrace has an important role to play in that offering. Since we moved to AWS in May 2014 we have had an availability of 99.95%!
More than 90% of enterprises now rely on a hybrid cloudinfrastructure to deliver innovative digital services and capture new markets. That’s because cloud platforms offer flexibility and extensibility for an organization’s existing infrastructure. What is hybrid cloud architecture?
DevOps and security teams managing today’s multicloud architectures and cloud-native applications are facing an avalanche of data. On average, organizations use 10 different tools to monitor applications, infrastructure, and user experiences across these environments.
As organizations adopt more cloud-native technologies, the risk—and consequences—of cyberattacks are also increasing. The Dynatrace platform has been recognized for seamlessly integrating with the Microsoft Sentinel cloud-native security information and event management ( SIEM ) solution. Audit logs.
Infrastructure as code is a way to automate infrastructure provisioning and management. And it’s a crucial step toward achieving cloud automation on the path to NoOps. In this blog, I explore how Dynatrace has made cloud automation attainable—and repeatable—at scale by embracing the principles of infrastructure as code.
In response to this shift, platform engineering is growing in popularity. The practice of platform engineering has evolved alongside the increasing complexity of cloud environments. The result is a cloud-native approach to software delivery. Why is platform engineering important?
Platform engineering is on the rise. According to leading analyst firm Gartner, “80% of software engineering organizations will establish platform teams as internal providers of reusable services, components, and tools for application delivery…” by 2026. Automation, automation, automation.
Infrastructure monitoring is the process of collecting critical data about your IT environment, including information about availability, performance and resource efficiency. Many organizations respond by adding a proliferation of infrastructure monitoring tools, which in many cases, just adds to the noise. Dynatrace news.
According to the Cloud Native Computing Foundation (CNCF), 84% of organizations are using or evaluating Kubernetes , up from 81% in 2022. The average deployment now spans 20 clusters running 10 or more software elements across clouds and data centers. Platform engineering looks to bring in a unified toolset.” billion. “We
Data migration is the process of moving data from one location to another, which is an essential aspect of cloud migration. Data migration involves transferring data from on-premise storage to the cloud. With the rapid adoption of cloud computing , businesses are moving their IT infrastructure to the cloud.
As organizations become cloud-native and their environments more complex, DevOps teams are adapting to new challenges. Site reliability engineering first emerged to address cloud computing’s new performance needs. Understanding the platform engineer role DevOps is a constantly evolving discipline.
As cloud-native, distributed architectures proliferate, the need for DevOps technologies and DevOps platform engineers has increased as well. DevOps engineer tools can help ease the pressure as environment complexity grows. ” What does a DevOps platform engineer do? .” Atlassian Jira.
Today, speed and DevOps automation are critical to innovating faster, and platform engineering has emerged as an answer to some of the most significant challenges DevOps teams are facing. It needs to be engineered properly as a product or service, and it needs automation, observability, and security in itself.”
It’s cliched to say that cloud adoption has changed everything in this race, but a full understanding of the intricacies of cloud-native applications is still rare. Cloud-based application architectures commonly leverage microservices. Extend infrastructure observability to WSO2 API Manager. Read on to see how it works.
AWS Security Hub findings AWS Security Hub provides a great way of aggregating security findings, especially those related to cloudinfrastructure. It can also be challenging to construct a full view of one’s security exposures when analyzing security findings across various environments and cloudinfrastructures.
What is site reliability engineering? Site reliability engineering (SRE) is the practice of applying software engineering principles to operations and infrastructure processes to help organizations create highly reliable and scalable software systems. Dynatrace news. SRE focuses on automation.
Five-nines availability has long been the goal of site reliability engineers (SREs) to provide system availability that is “always on.” But as more organizations adopt cloud-native technologies and distribute workloads among multicloud environments, that goal seems harder to attain. What is always-on infrastructure?
Protecting IT infrastructure, applications, and data requires that you understand security weaknesses attackers can exploit. Cloudinfrastructure analysis ensures the secure configuration of cloudinfrastructure including virtual machines, containers, cloud-hosted databases, and serverless services.
The Dynatrace Software Intelligence Platform gives you a complete Infrastructure Monitoring solution for the monitoring of cloud platforms and virtual infrastructure, along with log monitoring and AIOps. Network traffic data aggregation and filtering for on-premises, cloud, and hybrid networks.
When it comes to platform engineering, not only does observability play a vital role in the success of organizations’ transformation journeys—it’s key to successful platform engineering initiatives. The various presenters in this session aligned platform engineering use cases with the software development lifecycle.
As a leader in cloudinfrastructure and platform services , the Google Cloud Platform is fast becoming an integral part of many enterprises’ cloud strategies. Simplified cloud complexity with fully automated observability of Google Cloud. Dynatrace news.
As organizations look to expand DevOps maturity, improve operational efficiency, and increase developer velocity, they are embracing platform engineering as a key driver. The goal is to abstract away the underlying infrastructure’s complexities while providing a streamlined and standardized environment for development teams.
However, with these benefits come complexities in terms of cloud management, Kubernetes observability, and automation, making it imperative for enterprises to address these intricacies to enhance reliability, performance, and resource usage. So many tools can result in data inconsistencies.
DevOps and platform engineering are essential disciplines that provide immense value in the realm of cloud-native technology and software delivery. Observability of applications and infrastructure serves as a critical foundation for DevOps and platform engineering, offering a comprehensive view into system performance and behavior.
In recent years, function-as-a-service (FaaS) platforms such as Google Cloud Functions (GCF) have gained popularity as an easy way to run code in a highly available, fault-tolerant serverless environment. What is Google Cloud Functions? Google Cloud Functions is a serverless compute service for creating and launching microservices.
Real-time streaming needs real-time analytics As enterprises move their workloads to cloud service providers like Amazon Web Services, the complexity of observing their workloads increases. As cloud complexity grows, it brings more volume, velocity, and variety of log data. Managing this change is difficult.
More organizations than ever are undertaking cloud migration as digital transformation continues to gain momentum across every industry in every region. But what does it take to migrate your existing applications to the cloud? What is cloud migration? However, it can also mean migrating from one cloud to another.
Cloud-native observability for Google’s fully managed GKE Autopilot clusters demands new methods of gathering metrics, traces, and logs for workloads, pods, and containers to enable better accessibility for operations teams. These CSI pods provide a unique way of solving a handful of infrastructure problems. Agent logs security.
However, if you’re an operations engineer who’s been tasked with migrating to HANA from a legacy database system, you’ll need to get up to speed quickly. Enable the Davis AI causation engine to automatically analyze every metric. Enable the Davis AI causation engine to automatically analyze every metric.
As organizations expand their cloud footprints, they are combining public, private, and on-premises infrastructures. But modern cloudinfrastructure is large, complex, and dynamic — and over time, this cloud complexity can impede innovation. VA’s journey into the cloud.
Site reliability engineering (SRE) is the practice of applying software engineering principles to operations and infrastructure processes to help organizations create highly reliable and scalable software systems. Dynatrace news. SRE focuses on automation. SRE drives a “shift left” mindset.
For IT teams seeking agility, cost savings, and a faster on-ramp to innovation, a cloud migration strategy is critical. Cloud migration enables IT teams to enlist public cloudinfrastructure so an organization can innovate without getting bogged down in managing all aspects of IT infrastructure as it scales.
By gaining insights into how your Kubernetes workloads utilize computing and memory resources, you can make informed decisions about how to size and plan your infrastructure, leading to reduced costs. Proper Kubernetes monitoring includes utilizing observability information to optimize your environment.
While Kubernetes is often considered the operating system of the cloud, the scale and complexity of Kubernetes cluster deployments are creating new challenges for IT teams. Five of the most common include cluster instability, resource and cost management, security, observability, and stress on engineering teams.
To gain greater agility, Porsche Informatik migrated to a containerized, hybrid cloud environment. But this approach introduced new complexity and a need for more advanced cloud monitoring capabilities. At Perform 2021, we were joined by Peter Friedwagner, Head of Infrastructure and Cloud Services at Porsche Informatik.
As more organizations invest in a multicloud strategy, improving cloud operations and observability for increased resilience becomes critical to keep up with the accelerating pace of digital transformation. American Family turned to observability for cloud operations. Step 2: Instrument compute and serverless cloud technologies.
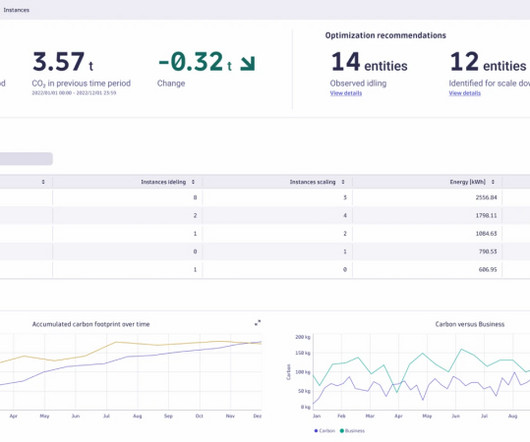
Energy efficiency is a key reason why organizations are migrating workloads from energy-intensive on-premises environments to more efficient cloud platforms. But while moving workloads to the cloud brings overall carbon emissions down, the cloud computing carbon footprint itself is growing. Certainly, this is true for us.
Leveraging cloud-native technologies like Kubernetes or Red Hat OpenShift in multicloud ecosystems across Amazon Web Services (AWS) , Microsoft Azure, and Google Cloud Platform (GCP) for faster digital transformation introduces a whole host of challenges. Dynatrace news. Connecting data siloes requires daunting integration endeavors.
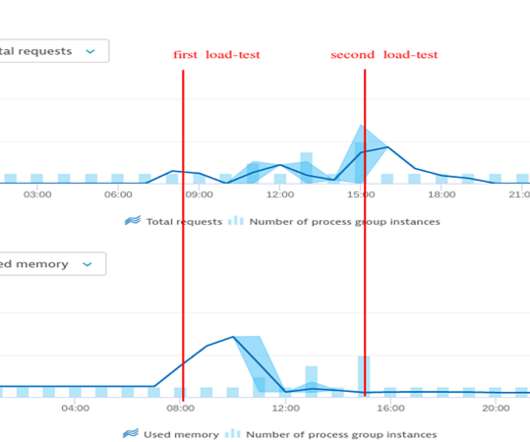
Dynatrace enables our customers to monitor and optimize their cloudinfrastructure and applications through the Dynatrace Software Intelligence Platform. For that reason, we started a simple load-test scenario where we flooded our event-based system with 100 cloud-events per minute.
Platform engineering is the discipline of building and maintaining a self-service platform for developers. The platform provides a set of cloud-native tools and services to help developers deliver applications quickly and efficiently.
In this blog, I will be going through a step-by-step guide on how to automate SRE-driven performance engineering. Kubernetes, OpenShift, Cloud Foundry or Azure Web Apps then install the OneAgent by following the OneAgent PaaS installation options. Dynatrace news. If your apps are deployed in a PaaS Platform, e.g:
How can you reduce the carbon footprint of your hybrid cloud? This is a rather simple move as it doesn’t directly impact your infrastructure, just your contract with your electricity provider. energy-efficient data centers—cloud providers—achieve values closer to 1.2. Is the solution to just move all workloads to the cloud?
Cloud-native observability and artificial intelligence (AI) can help organizations do just that with improved analysis and targeted insight. Additionally, they discuss the need for cloud-native observability with GitOps that provides continuous operational insight across the Kubernetes value stream.
Whether necessary as part of deep root-cause analyses of issues faced by your users that impact your business or if you’re an engineer responsible for the infrastructure hosting your applications and network paths. You want to be able to answer questions like these: What is responsible for application slowdown?
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content