This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Dynatrace continues to deliver on its commitment to keeping your data secure in the cloud. Enhancing data separation by partitioning each customer’s data on the storage level and encrypting it with a unique encryption key adds an additional layer of protection against unauthorized data access.
AI transformation, modernization, managing intelligent apps, safeguarding data, and accelerating productivity are all key themes at Microsoft Ignite 2024. Adopting AI to enhance efficiency and boost productivity is critical in a time of exploding data, cloud complexities, and disparate technologies.
Cloud computing platforms have fundamentally altered how organizations access and manage data. Because of the emergence of cloud services, a broad range of storage choices are now easily available to fulfill the different demands of both organizations and people.
Efficient data processing is crucial for businesses and organizations that rely on big data analytics to make informed decisions. One key factor that significantly affects the performance of data processing is the storage format of the data.
Data migration is the process of moving data from one location to another, which is an essential aspect of cloud migration. Data migration involves transferring data from on-premise storage to the cloud.
We’re excited to announce the expansion of the Dynatrace security portfolio with new Cloud Security Posture Management (CSPM) capabilities. Cloud environments are vast and constantly evolving, making manual identification of misconfigurations virtually impossible. million annually per organization. The solution?
Move beyond logs-only security: Embrace a comprehensive, end-to-end approach that integrates all data from observability and security. More technology, more complexity The benefits of cloud-native architecture for IT systems come with the complexity of maintaining real-time visibility into security compliance and risk posture.
And with cloud-native databases like PostgreSQL and MySQL, the complexity only grows. A shared vision At Dynatrace, weve built a comprehensive observability platform that already includes deep database visibility, the Top Database Statements view, and Grail for unified datastorage and analysis.
It can scale towards a multi-petabyte level data workload without a single issue, and it allows access to a cluster of powerful servers that will work together within a single SQL interface where you can view all of the data. This feature-packed database provides powerful and rapid analytics on data that scales up to petabyte volumes.
But IT teams need to embrace IT automation and new datastorage models to benefit from modern clouds. As they enlist cloud models, organizations now confront increasing complexity and a data explosion. Data explosion hinders better data insight.
The challenge along the path Well-understood within IT are the coarse reduction levers used to reduce emissions; shifting workloads to the cloud and choosing green energy sources are two prime examples. This is partly due to the complexity of instrumenting and analyzing emissions across diverse cloud and on-premises infrastructures.
Key insights for executives: Increase operational efficiency with automation and AI to foster seamless collaboration : With AI and automated workflows, teams work from shared data, automate repetitive tasks, and accelerate resolutionfocusing more on business outcomes. No delays and overhead of reindexing and rehydration.
For IT infrastructure managers and site reliability engineers, or SREs , logs provide a treasure trove of data. But on their own, logs present just another data silo as IT professionals attempt to troubleshoot and remediate problems. Data volume explosion in multicloud environments poses log issues.
In fact, according to a Dynatrace global survey of 1,300 CIOs , 99% of enterprises utilize a multicloud environment and seven cloud monitoring solutions on average. What is cloud monitoring? Cloud monitoring is a set of solutions and practices used to observe, measure, analyze, and manage the health of cloud-based IT infrastructure.
In an era where data is the new oil, effectively utilizing data is crucial for the growth of every organization. It is not enough to store these data durably, but also to effectively query and analyze them. Without a querying capability, the data stored in S3 would not be of any benefit.
The industry has always innovated, and over the last decade, it started moving towards cloud-based workflows. However, unlocking cloud innovation and all its benefits on a global scale has proven to be difficult. The data produced on set is traditionally copied to physical tape stock like LTO.
Some time ago, at a restaurant near Boston, three Dynatrace colleagues dined and discussed the growing data challenge for enterprises. At its core, this challenge involves a rapid increase in the amount—and complexity—of data collected within a company. Work with different and independent data types. Thus, Grail was born.
While data lakes and data warehousing architectures are commonly used modes for storing and analyzing data, a data lakehouse is an efficient third way to store and analyze data that unifies the two architectures while preserving the benefits of both. What is a data lakehouse? How does a data lakehouse work?
As an example, cloud-based post-production editing and collaboration pipelines demand a complex set of functionalities, including the generation and hosting of high quality proxy content. As described by the white paper Apple ProRes ( link ), the target data rate of the Apple ProRes HQ for 1920x1080 at 29.97 is 220 Mbps.
Data processing in the cloud has become increasingly popular due to its scalability, flexibility, and cost-effectiveness. This article will explore how these technologies can be used together to create an optimized data pipeline for data processing in the cloud.
Second, developers had to constantly re-learn new data modeling practices and common yet critical data access patterns. To overcome these challenges, we developed a holistic approach that builds upon our Data Gateway Platform. Data Model At its core, the KV abstraction is built around a two-level map architecture.
As cloud complexity increases and security concerns mount, organizations need log analytics to discover and investigate issues and gain critical business intelligence. With this new DPS pricing model option, customers can retain data at a fixed low cost with no additional cost to query for up to 35 days.
Log management is an organization’s rules and policies for managing and enabling the creation, transmission, analysis, storage, and other tasks related to IT systems’ and applications’ log data. In cloud-native environments, there can also be dozens of additional services and functions all generating data from user-driven events.
At first, data tiering was a tactic used by storage systems to reduce datastorage costs. This involved grouping data that was not accessed as often into more affordable, if less effective, storage array choices. Public clouds presently offer a mix of object and file storage options.
Cloud-based solutions typically aren’t a viable option or enterprises that have strict security or privacy policies that require their data to be maintained on-premise. To give you a helping hand in such scenarios, we decided to facilitate Managed cluster deployments for major cloud platforms. Dynatrace news.
Creating an ecosystem that facilitates data security and data privacy by design can be difficult, but it’s critical to securing information. When organizations focus on data privacy by design, they build security considerations into cloud systems upfront rather than as a bolt-on consideration.
Metric definitions are often scattered across various databases, documentation sites, and code repositories, making it difficult for analysts and data scientists to find reliable information quickly. LORE: How were democratizing analytics atNetflix Apurva Kansara At Netflix, we rely on data and analytics to inform critical business decisions.
ln a world driven by macroeconomic uncertainty, businesses increasingly turn to data-driven decision-making to stay agile. They’re unleashing the power of cloud-based analytics on large data sets to unlock the insights they and the business need to make smarter decisions. All of these factors challenge DevOps maturity.
In recent years, function-as-a-service (FaaS) platforms such as Google Cloud Functions (GCF) have gained popularity as an easy way to run code in a highly available, fault-tolerant serverless environment. What is Google Cloud Functions? Google Cloud Functions is a serverless compute service for creating and launching microservices.
As a leader in cloud infrastructure and platform services , the Google Cloud Platform is fast becoming an integral part of many enterprises’ cloud strategies. Simplified cloud complexity with fully automated observability of Google Cloud. Dynatrace news.
By: Rajiv Shringi , Oleksii Tkachuk , Kartik Sathyanarayanan Introduction In our previous blog post, we introduced Netflix’s TimeSeries Abstraction , a distributed service designed to store and query large volumes of temporal event data with low millisecond latencies. Today, we’re excited to present the Distributed Counter Abstraction.
Mounting object storage in Netflix’s media processing platform By Barak Alon (on behalf of Netflix’s Media Cloud Engineering team) MezzFS (short for “Mezzanine File System”) is a tool we’ve developed at Netflix that mounts cloud objects as local files via FUSE. Assemble and decrypt parts? —?Our Mount multiple objects? — ?
Carbon Impact leverages business events , a special data type designed to support the real-time accuracy and long-term granularity demands common to business use cases. Carbon Impact uses host utilization metrics from OneAgents to report the estimated energy consumption for CPU, storage I/O, memory, and network.
As cloud environments become increasingly complex, legacy solutions can’t keep up with modern demands. As a result, companies run into the cloud complexity wall – also known as the cloud observability wall – as they struggle to manage modern applications and gain multicloud observability with outdated tools.
Log data provides a unique source of truth for debugging applications, optimizing infrastructure, and investigating security incidents. This contextualization of log data enables AI-powered problem detection and root cause analysis at scale. Dynamic landscape and data handling requirements result in manual work.
Modern organizations ingest petabytes of data daily, but legacy approaches to log analysis and management cannot accommodate this volume of data. based financial services group, discussed how the bank uses log monitoring on the Dynatrace platform with an emphasis on observability and security data.
With our latest enhancements, were transforming the way you work with trace data. Whether you’re using OpenTelemetry or OneAgent, operating in the cloud or on-premiseswe’ve got you covered. Say hello to advanced trace an alytics and new datastorage and capture options. But why stop there?
Cloud-native observability for Google’s fully managed GKE Autopilot clusters demands new methods of gathering metrics, traces, and logs for workloads, pods, and containers to enable better accessibility for operations teams. First, we create a small Kubernetes cluster in the Google Cloud Console. Agent logs security.
While this approach can be effective if the model is trained with a large amount of data, even in the best-case scenarios, it amounts to an informed guess, rather than a certainty. But to be successful, data quality is critical. Teams need to ensure the data is accurate and correctly represents real-world scenarios. Consistency.
For many companies, the journey to modern cloud applications starts with serverless. This means you no longer have to provision, scale, and maintain servers to run your applications, databases, and storage systems. Data Store. As data volumes rapidly increase, streamlined datastorage is a top priority.
Software and data are a company’s competitive advantage. But for software to work perfectly, organizations need to use data to optimize every phase of the software lifecycle. But for software to work perfectly, organizations need to use data to optimize every phase of the software lifecycle. But how is this data connected?
Cloud deployments have grown rapidly in recent years, and enterprise hybrid and multicloud environments have become the new standard, resulting in new challenges such as: Keeping up with dynamic, autoscaling environments where instances, applications and microservices come and go fast. AWS Storage Gateway. Dynatrace news. AWS OpsWorks.
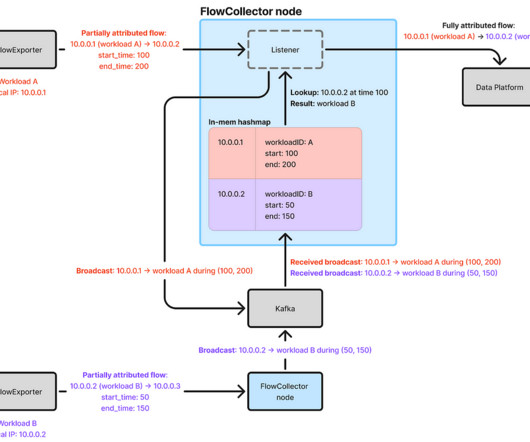
In cloud environments, IP addresses are reassigned to different workloads as workload instances are created and terminated, so IP addresses alone cannot provide insights on which workloads are communicating. Misattribution rendered the flow data unreliable for decision-making. On average, 5 million records are produced persecond.
So many default to Amazon RDS, when MySQL performs exceptionally well on Azure Cloud. In this post, we outline the best way to host MySQL on Azure , including managed solutions, instance types, high availability replication, backup, and disk types to use to optimize your cloud database performance. MySQL DBaaS vs. Self-Managed MySQL.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content