This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
A critical part of the code yellow was ensuring Google's sites would be fast for users across the globe, even if they had slow networks and low end devices. So in addition to all the optimization work we did for Google Docs, I got to spend a lot of time and energy working on the measurement problem: how can we get end-to-end latency numbers?
Netflix runs dozens of stateful services on AWS under strict sub-millisecond tail-latency requirements, which brings unique challenges. We showcase our casestudies, open-source tools in benchmarking, and how we ensure that AWS cloud services are serving our needs without compromising on tail latencies.
This approach often leads to heavyweight high-latency analytical processes and poor applicability to realtime use cases. This opportunity is leveraged in the following casestudy. CaseStudy. CaseStudy. CaseStudy.
The new AWS Africa (Cape Town) Region will have three Availability Zones and provide lower latency to end users across Sub-Saharan Africa. That's where we built many pioneering networking technologies, our next-generation software for customer support, and the technology behind our compute service, Amazon EC2.
RabbitMQ excels at managing asynchronous processing and reducing latency while distributing workloads effectively across the system. By prioritizing such messages, RabbitMQ delivers notifications with minimal latency, thus improving the user experience while sustaining the efficacy of communication systems. RabbitMQ in Action.
Netflix runs dozens of stateful services on AWS under strict sub-millisecond tail-latency requirements, which brings unique challenges. We showcase our casestudies, open-source tools in benchmarking, and how we ensure that AWS cloud services are serving our needs without compromising on tail latencies.
Netflix runs dozens of stateful services on AWS under strict sub-millisecond tail-latency requirements, which brings unique challenges. We showcase our casestudies, open-source tools in benchmarking, and how we ensure that AWS cloud services are serving our needs without compromising on tail latencies.
This Region will consist of three Availability Zones at launch, and it will provide even lower latency to users across the Middle East. I'm also excited to announce today that we are launching an AWS Edge Network Location in the United Arab Emirates (UAE) in the first quarter of 2018.
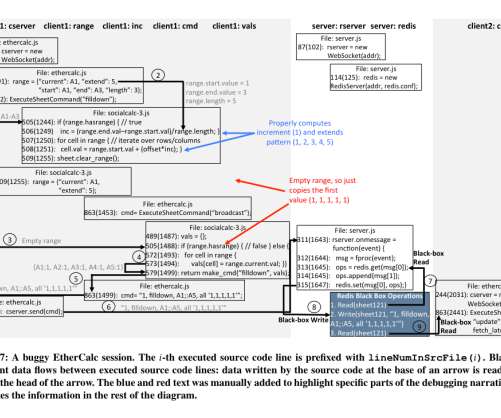
If the edit creates a new, unlogged network request, then the replay framework must inject new network events into the log. The paper contains a casestudy of the authors debugging EtherCalc using Reverb. Across the top 300 Alexa sites the gzipped logs have a median size of 45.4 KB (95%-ile size 113.2 KB), and it takes 7.8
eBPF was created by Alexei Starovoitov while at PLUMgrid (he's now at Facebook) as a generic in-kernel virtual machine, with software defined networks as the primary use case. Back then I could already tell if disks were seeking by interpreting iostat(1) output: seeing high disk latency but small I/O. eBPF does more.
Each stage has its unique challenges and potential pitfalls, as other casestudies show. You need to beware that slow server response times can significantly increase TTFB, often due to server overload, network issues, or un-optimized logic on the server side. Here’s a breakdown of the moving pieces.
The use of server-timing headers by content delivery networks closes a big gap. Latency – How much time does it take to deliver a packet from A to B. Recent server timing casestudies It's great to see server timing starting to get more use in the wild. But what happens when it doesn't? Definitely worth a read!
Large preview ) While browsers are generally pretty fast, these steps still take time to load, typically in seconds, and even longer on slower, high-latencynetwork connections. Homepage with DevTools Network inspection enabled and open. Homepage of a default Drupal site using the Umami theme.
For example, in a casestudy published by Gilt Groupe , Eric Shepherd, who was formerly Gilt’s principal front end engineer, noted that: Both RUM and synthetic monitoring give different views of our performance, and are useful for different things. They each bring different – and complementary – information to the table.
eBPF was created by Alexei Starovoitov while at PLUMgrid (he's now at Facebook) as a generic in-kernel virtual machine, with software defined networks as the primary use case. Back then I could already tell if disks were seeking by interpreting iostat(1) output: seeing high disk latency but small I/O. eBPF does more.
A performance budget as a mechanism for planning a web experience and preventing performance decay might consist of the following yardsticks: Overall page weight, Total number of HTTP requests, Page-load time on a particular mobile network, First Input Delay (FID). Similarly, unoptimized images were the leading cause of page bloat.
Using an image CDN, such as KeyCDN, can significantly reduce the latency of your image delivery. This is crucial due to mobile devices requiring additional optimizations because they typically have less powerful hardware and a slower network connection when compared to desktop devices. Mbps ( Opensignal ).
Networking, HTTP/2, HTTP/3 OCSP stapling, EV/DV certificates, packaging, IPv6, QUIC, HTTP/3. You need a business stakeholder buy-in, and to get it, you need to establish a casestudy, or a proof of concept using the Performance API on how speed benefits metrics and Key Performance Indicators ( KPIs ) they care about.
You need a business stakeholder buy-in, and to get it, you need to establish a casestudy, or a proof of concept using the Performance API on how speed benefits metrics and Key Performance Indicators ( KPIs ) they care about. It will help you build up a company-tailored casestudy with real data. How to get there?
You need a business stakeholder buy-in, and to get it, you need to establish a casestudy on how speed benefits metrics and Key Performance Indicators ( KPIs ) they care about. Study common complaints coming into customer service and see how improving performance can help relieve some of these common problems. How to get there?
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.























Let's personalize your content