This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Caching is the process of storing frequently accessed data or resources in a temporary storage location, such as memory or disk, to improve retrieval speed and reduce the need for repetitive processing.
After selecting a mode, users can interact with APIs without needing to worry about the underlying storage mechanisms and counting methods. Best Effort Regional Counter This type of counter is powered by EVCache , Netflix’s distributed caching solution built on the widely popular Memcached.
We introduce a caching mechanism in the API gateway layer, allowing us to offload processing from singleton leader elected controllers without giving up strict data consistency and guarantees clients observe. When a new leader is elected it loads all data from external storage. The cache is kept in sync with the current leader process.
Firstly, the synchronous process which is responsible for uploading image content on file storage, persisting the media metadata in graph data-storage, returning the confirmation message to the user and triggering the process to update the user activity. Fetching User Feed. Sample Queries supported by Graph Database. Optimization.
This means you no longer have to provision, scale, and maintain servers to run your applications, databases, and storage systems. Speed is next; serverless solutions are quick to spin up or down as needed, and there are no delays due to limited storage or resource access. Scalability. Finally, there’s scalability.
While we were able to put out the immediate fire by disabling the newly created alerts, this incident raised some critical concerns around the scalability of our alerting system. It became clear to us that we needed to solve the scalability problem with a fundamentally different approach. OK, Results?
For example, you can switch to a scalable cloud-based web host, or compress/optimize images to save bandwidth. Choose A Scalable Web Host The most convenient way to design a high-traffic website without worrying about website crashes is to upgrade your web hosting solution. Caching can help your website combat this issue.
MongoDB offers several storage engines that cater to various use cases. The default storage engine in earlier versions was MMAPv1, which utilized memory-mapped files and document-level locking. The newer, pluggable storage engine, WiredTiger, addresses this by using prefix compression, collection-level locking, and row-based storage.
Central to this infrastructure is our use of multiple online distributed databases such as Apache Cassandra , a NoSQL database known for its high availability and scalability. This flexibility allows our Data Platform to route different use cases to the most suitable storage system based on performance, durability, and consistency needs.
A distributed storage system is foundational in today’s data-driven landscape, ensuring data spread over multiple servers is reliable, accessible, and manageable. Understanding distributed storage is imperative as data volumes and the need for robust storage solutions rise.
Through effortless provisioning, a larger number of small hosts provide a cost-effective and scalable platform. Of the organizations in the Kubernetes survey, 71% run databases and caches in Kubernetes, representing a +48% year-over-year increase. The different infrastructure setup reflects economic and technical considerations.
Werner Vogels weblog on building scalable and robust distributed systems. a Fast and Scalable NoSQL Database Service Designed for Internet Scale Applications. The original Dynamo design was based on a core set of strong distributed systems principles resulting in an ultra-scalable and highly reliable database system.
The Key-Value Abstraction offers a flexible, scalable solution for storing and accessing structured key-value data, while the Data Gateway Platform provides essential infrastructure for protecting, configuring, and deploying the data tier.
This post will look at using The Oversized-Attribute Storage Technique (TOAST) to improve performance and scalability. Therefore, TOAST is a storage technique used in PostgreSQL to handle large data objects such as images, videos, and audio files.
That means multiple data indirections mean multiple cache misses. Mark LaPedus : MRAM, a next-generation memory type, is being touted as a replacement for embedded flash and cache applications. Cliff Click : The JVM is very good at eliminating the cost of code abstraction, but not the cost of data abstraction. They are very expensive.
In this comparison of Redis vs Memcached, we strip away the complexity, focusing on each in-memory data store’s performance, scalability, and unique features. Redis is better suited for complex data models, and Memcached is better suited for high-throughput, string-based caching scenarios.
While caching continues to be a dominant use of ElastiCache for Redis, we see customers increasingly use it as an in-memory NoSQL database. We have therefore been enhancing the Redis engine running on ElastiCache for the last few years using our own expertise in making enterprise infrastructure scalable and reliable.
For good performance, the filter blocks are cached in the RocksDB block cache and normally stay there since they are accessed frequently. LSM storage engines like MyRocks are very different from the more common B-Tree-based storage engines like InnoDB. Download Percona Distribution for MySQL Today
In addition to the OneAgent collecting all these metrics, Dynatrace has an integration with Azure Monitor to capture additional metrics for platform services such as Storage Accounts, Redis Cache, API Management Services, Load Balancers among others. Organic scalability of the monitoring platform with the applications.
Werner Vogels weblog on building scalable and robust distributed systems. Today AWS has launched Amazon ElastiCache , a new service that makes it easy to add distributed in-memory caching to any application. Systems that make extensive use of caching almost all report a significant reduction in the cost of their database tier.
The first phase involves validating functional correctness, scalability, and performance concerns and ensuring the new systems’ resilience before the migration. It helps expose memory leaks, deadlocks, caching issues, and other system issues.
Despite initial investment costs, DBMS presents long-term savings and improved efficiency through automated processes, efficient query optimizations, and scalability, contributing to enhanced decision-making and end-user productivity. Practical Applications of DBMS DBMS finds practical applications in various fields.
By caching hot datasets, indexes, and ongoing changes, InnoDB can provide faster response times and utilize disk IO in a much more optimal way. Storage The type of storage and disk used for database servers can have a significant impact on performance and reliability. Try Percona Distribution for MySQL today! and MariaDB 10.5.4
Scalability is one of the main drivers of the NoSQL movement. Read/Write scalability. The first figure below depicts logical relationships between different techniques and their coordinates in the system of the consistency-scalability-availability-latency tradeoffs. Consistency-scalability tradeoff. Read/Write latency.
But as companies grow and see more demand for their databases, we need to ensure that PMM also remains scalable so you don’t need to worry about its performance while tending to the rest of your environment. PMM2 uses VictoriaMetrics (VM) as its metrics storage engine. Virtual Memory utilization was averaging 48 GB of RAM.
Active Memory Caching. When you want to get data that you already had quickly, you need to do caching — caching stores data that a user recently retrieved. Caching partially stores your data and is not used as permanent storage. Caching partially stores your data and is not used as permanent storage.
As I have talked about before, one of the reasons why we built Amazon DynamoDB was that Amazon was pushing the limits of what was a leading commercial database at the time and we were unable to sustain the availability, scalability, and performance needs that our growing Amazon.com business demanded. The opposite is true.
Werner Vogels weblog on building scalable and robust distributed systems. Often these namespaces are hierarchical in nature such that it becomes easier to manage them and to decentralize control, which makes the system more scalable. There are two main types of DNS servers: authoritative servers and caching resolvers.
To monitor Redis instances effectively, collect Redis metrics focusing on cache hit ratio, memory allocated, and latency threshold. Advanced monitoring techniques enable you to identify potential issues, such as high latency, CPU utilization, command throughput, and cache hit rate before they become major problems.
The Solution: Distributed Caching. The solution to this challenge is to use scalable, memory-based data storage for fast-changing data so that web sites can keep up with exploding workloads. It’s not enough simply to lash together a set of servers hosting a collection of in-memory caches.
The Solution: Distributed Caching. The solution to this challenge is to use scalable, memory-based data storage for fast-changing data so that web sites can keep up with exploding workloads. It’s not enough simply to lash together a set of servers hosting a collection of in-memory caches.
Last week we looked at a function shipping solution to the problem; Cloudburst uses the more common data shipping to bring data to caches next to function runtimes (though you could also make a case that the scheduling algorithm placing function execution in locations where the data is cached a flavour of function-shipping too).
Werner Vogels weblog on building scalable and robust distributed systems. As some of you may remember I was pretty excited when Amazon Simple Storage Service (S3) released its website feature such that I could serve this weblog completely from S3. Driving Storage Costs Down for AWS Customers. All Things Distributed.
Werner Vogels weblog on building scalable and robust distributed systems. The storage systems weve pioneered demonstrate extreme scalability while maintaining tight control over performance, availability, and cost. Driving Storage Costs Down for AWS Customers. Expanding the Cloud - The AWS Storage Gateway.
File systems unfit as distributed storage backends: lessons from 10 years of Ceph evolution Aghayev et al., In this case, the assumption that a distributed storage backend should clearly be layered on top of a local file system. What is a distributed storage backend? SOSP’19. This is not surprising in hindsight.
PostgreSQL & Elastic for data storage. REDIS for caching. Robert’s AWS & EKS admin team are monitoring most services with that capability but found it beneficial for them to have Dynatrace monitor Elastic File Storage (EFS). Their technology stack looks like this: Spring Boot-based Microservices. NGINX as an API Gateway.
To monitor Redis® instances effectively, collect Redis metrics focusing on cache hit ratio, memory allocated, and latency threshold. Advanced monitoring techniques enable you to identify potential issues, such as high latency, CPU utilization, command throughput, and cache hit rate before they become major problems.
Today, I'm excited to announce the general availability of Amazon DynamoDB Accelerator (DAX) , a fully managed, highly available, in-memory cache that can speed up DynamoDB response times from milliseconds to microseconds, even at millions of requests per second. DynamoDB was the first service at AWS to use SSD storage.
We were pushing the limits of what was a leading commercial database at the time and were unable to sustain the availability, scalability and performance needs that our growing Amazon business demanded. We had an advanced team of database administrators and access to top experts within Oracle. million requests per second.
The rationale behind these methods is that frontend should be able to fetch transient information very efficiently and separately from fetching of heavy-weight domain entities because this information cannot be cached. So, the only way was to cache all necessary data to minimize interaction with RDBMS.
We group the DBMS design choices and tradeoffs into three broad categories, which result from the need for dealing with (A) external storage; (B) query executors that are spun on demand; and (C) DBMS-as-a-service offerings. Query performance is measured from both warm and cold caches. Key findings. Query restrictions. Serverless o?erings
This operation is quite expensive but our database can run it in a few milliseconds or less, thanks to several optimizations that allow the node to execute most of them in memory with no or little access to mass storage. As well, very few cases are in need to have a full system/solution to provide scalability with sharding.
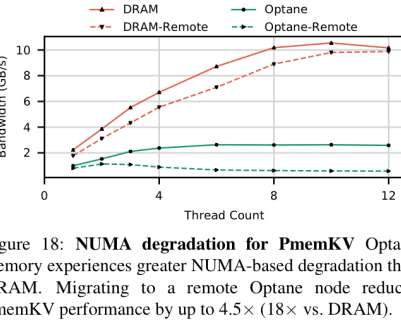
An empirical guide to the behavior and use of scalable persistent memory , Yang et al., The Optane DIMM is the first scalable, commercially available NVDIMM. Use non-temporal stores for large transfers, and control cache evictions. FAST’20. most recently ‘ Efficient lock-free durable sets ‘). to 0.98.
For example, the IMDG must be able to efficiently create millions of objects in each server to make use of its huge storage capacity. Given all this, we thought it would be a good opportunity to see how we are doing relative to the competition, and in particular, relative to Microsoft’s AppFabric caching for Windows on-premise servers.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content