This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
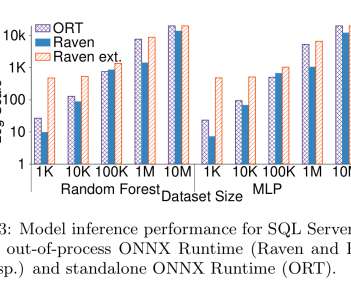
After selecting a mode, users can interact with APIs without needing to worry about the underlying storage mechanisms and counting methods. Best Effort Regional Counter This type of counter is powered by EVCache , Netflix’s distributed caching solution built on the widely popular Memcached.
Caching is the process of storing frequently accessed data or resources in a temporary storage location, such as memory or disk, to improve retrieval speed and reduce the need for repetitive processing.
We introduce a caching mechanism in the API gateway layer, allowing us to offload processing from singleton leader elected controllers without giving up strict data consistency and guarantees clients observe. cell): Titus Job Coordinator is a leader elected process managing the active state of the system.
There are two major processes which gets executed when a user posts a photo on Instagram. Firstly, the synchronous process which is responsible for uploading image content on file storage, persisting the media metadata in graph data-storage, returning the confirmation message to the user and triggering the process to update the user activity.
This means you no longer have to provision, scale, and maintain servers to run your applications, databases, and storage systems. Speed is next; serverless solutions are quick to spin up or down as needed, and there are no delays due to limited storage or resource access. AWS offers four serverless offerings for storage.
Our goal was to build a versatile and efficient data storage solution that could handle a wide variety of use cases, ranging from the simplest hashmaps to more complex data structures, all while ensuring high availability, tunable consistency, and low latency. Developers just provide their data problem rather than a database solution!
By Xiaomei Liu , Rosanna Lee , Cyril Concolato Introduction Behind the scenes of the beloved Netflix streaming service and content, there are many technology innovations in media processing. Packaging has always been an important step in media processing. Uploading and downloading data always come with a penalty, namely latency.
MongoDB offers several storage engines that cater to various use cases. The default storage engine in earlier versions was MMAPv1, which utilized memory-mapped files and document-level locking. The newer, pluggable storage engine, WiredTiger, addresses this by using prefix compression, collection-level locking, and row-based storage.
A distributed storage system is foundational in today’s data-driven landscape, ensuring data spread over multiple servers is reliable, accessible, and manageable. Understanding distributed storage is imperative as data volumes and the need for robust storage solutions rise.
Data warehouses offer a single storage repository for structured data and provide a source of truth for organizations. However, organizations must structure and store data inputs in a specific format to enable extract, transform, and load processes, and efficiently query this data. Massively parallel processing. Query language.
Of the organizations in the Kubernetes survey, 71% run databases and caches in Kubernetes, representing a +48% year-over-year increase. Together with messaging systems (+36% growth), organizations are increasingly using databases and caches to persist application workload states.
Building an elastic query engine on disaggregated storage , Vuppalapati, NSDI’20. Snowflake is a data warehouse designed to overcome these limitations, and the fundamental mechanism by which it achieves this is the decoupling (disaggregation) of compute and storage. joins) during query processing. Disaggregation (or not).
The shortcomings and drawbacks of batch-oriented data processing were widely recognized by the Big Data community quite a long time ago. It became clear that real-time query processing and in-stream processing is the immediate need in many practical applications. Fault-tolerance. Interoperability with Hadoop.
A shared characteristic in most (if not all) databases, be them traditional relational databases like Oracle, MySQL, and PostgreSQL or some kind of NoSQL-style database like MongoDB, is the use of a caching mechanism to keep (a copy of) part of the data in memory. How do you know if your MySQL database caching is operating efficiently?
Flexible Storage : The service is designed to integrate with various storage backends, including Apache Cassandra and Elasticsearch , allowing Netflix to customize storage solutions based on specific use case requirements. Note : With Cassandra 4.x
Rachel Kelley (AWS), Ranjit Raju (AWS) Rendering is core to the the VFX process VFX studios around the world create amazing imagery for Netflix productions. By: Peter Cioni (Netflix), Alex Schworer (Netflix), Mac Moore (Conductor Tech.), Rendering on AWS provides the flexibility to control how quickly a project is completed.
are stored in secure storage layers. Amsterdam is built on top of three storage layers. To avoid the ES query for the list of indices for every indexing request, we keep the list of indices in a distributed cache. We also utilize Kafka to process these assets asynchronously without impacting our real time traffic.
Replays provide on-demand data about where conversion processes aren’t working. By analyzing sessions of new employees interacting with key tools, teams can provide detailed instructions that will help to streamline the onboarding process and get staff up to speed faster. Are customers losing interest? Enhancing error correction.
This post will look at using The Oversized-Attribute Storage Technique (TOAST) to improve performance and scalability. This process is done automatically and does not significantly impact how the database is used. text, bytea), and “strategy” is one of the four TOAST storage strategies (PLAIN, EXTENDED, EXTERNAL, MAIN).
Key Takeaways Redis offers complex data structures and additional features for versatile data handling, while Memcached excels in simplicity with a fast, multi-threaded architecture for basic caching needs. Redis is better suited for complex data models, and Memcached is better suited for high-throughput, string-based caching scenarios.
The voice service then constructs a message for the device and places it on the message queue, which is then processed and sent to Pushy to deliver to the device. The previous version of the message processor was a Mantis stream-processing job that processed messages from the message queue.
This process enables you to continuously evaluate software against predefined quality criteria and service level objectives (SLOs) in pre-production environments. Storing frequently accessed data in faster storage, usually in-memory caching, improves data retrieval speed and overall system performance. Beyond
Traffic Duplication and Correlation: The initial step requires the implementation of a mechanism to clone and fork production traffic to the newly established pathway, along with a process to record and correlate responses from the original and alternative routes.
This information is gathered from remote, often inaccessible points within your ecosystem and processed by some sort of tool or equipment. The data is incredibly plentiful and difficult to store over long periods due to capacity limitations — a reason why private and public cloud storage services have been a boon to DevOps teams.
Dependency agent Installation – Maps connections between servers and processes. AI engine, Davis – Automatically processes billions of dependencies to serve up precise answers; rather than processing simple time-series data, Davis uses high-fidelity metrics, traces, logs, and real user data that are mapped to a unified entity.
Every unnecessary bit of JavaScript code you bundle and serve will be more code the client has to load and process. Active Memory Caching. When you want to get data that you already had quickly, you need to do caching — caching stores data that a user recently retrieved. Caching Schemes. Large preview ).
But since retrieving data from disk is slow, databases tend to work with a caching mechanism to keep as much hot data, the bits and pieces that are most often accessed, in memory. In MySQL, considering the standard storage engine, InnoDB , the data cache is called Buffer Pool. In PostgreSQL, it is called shared buffers.
As datasets continue to grow in size, the amount of RAM required to store and process these datasets also increases. By caching hot datasets, indexes, and ongoing changes, InnoDB can provide faster response times and utilize disk IO in a much more optimal way. Setting oom_score_adj to -800. Refer to innodb_redo_log_capacity below.
Journal It’s a process where every write operation gets written (appended) from Memory to a Journal file, AKA transaction log that exists on disk at a specific interval configured using “ journalCommitIntervalMs.” The same data, in the form of pages inside the Wiredtiger cache, are also marked dirty. wt and index-*.wt).
The Solution: Distributed Caching. The solution to this challenge is to use scalable, memory-based data storage for fast-changing data so that web sites can keep up with exploding workloads. It’s not enough simply to lash together a set of servers hosting a collection of in-memory caches.
The Solution: Distributed Caching. The solution to this challenge is to use scalable, memory-based data storage for fast-changing data so that web sites can keep up with exploding workloads. It’s not enough simply to lash together a set of servers hosting a collection of in-memory caches.
Despite initial investment costs, DBMS presents long-term savings and improved efficiency through automated processes, efficient query optimizations, and scalability, contributing to enhanced decision-making and end-user productivity. It provides tools for organizing and retrieving data efficiently.
Effective management of memory stores with policies like LRU/LFU proactive monitoring of the replication process and advanced metrics such as cache hit ratio and persistence indicators are crucial for ensuring data integrity and optimizing Redis’s performance. If the cache hit ratio is lower than ~0.8
Last week we looked at a function shipping solution to the problem; Cloudburst uses the more common data shipping to bring data to caches next to function runtimes (though you could also make a case that the scheduling algorithm placing function execution in locations where the data is cached a flavour of function-shipping too).
When the JavaScript engine runs a garbage-collection process, the man object will be removed from memory and from the WeakMap that we assigned it to. The process of clearing memory when objects are no longer being used is referred to as garbage collection. With caching, a copy of the result from a request is saved locally.
PostgreSQL & Elastic for data storage. REDIS for caching. In order to filter these dashboards by tenant all they need is a Dynatrace Management Zone , which is based on meta data extracted by Dynatrace from e.g. k8s tags, container labels or process environment variables. NGINX as an API Gateway. 3 Log Analytics.
Extending relational query processing with ML inference , Karanasos, CIDR’10. … based on interactions with enterprise customers, we expect that storage and inference of ML models will be subject to the same scrutiny and performance requirements of sensitive/mission-critical operational data. " Query execution.
File systems unfit as distributed storage backends: lessons from 10 years of Ceph evolution Aghayev et al., In this case, the assumption that a distributed storage backend should clearly be layered on top of a local file system. What is a distributed storage backend? SOSP’19. This is not surprising in hindsight.
To monitor Redis instances effectively, collect Redis metrics focusing on cache hit ratio, memory allocated, and latency threshold. Advanced monitoring techniques enable you to identify potential issues, such as high latency, CPU utilization, command throughput, and cache hit rate before they become major problems.
The service workers enable the offline usage of the PWA by fetching cached data or informing the user about the absence of an Internet connection. When developing a PWA, you can cache the application shell’s resources and assets in the browser. Cached content with IndexedDB. Cache first, then network. Service Workers.
The rationale behind these methods is that frontend should be able to fetch transient information very efficiently and separately from fetching of heavy-weight domain entities because this information cannot be cached. So, the only way was to cache all necessary data to minimize interaction with RDBMS.
We use high-performance transactions systems, complex rendering and object caching, workflow and queuing systems, business intelligence and data analytics, machine learning and pattern recognition, neural networks and probabilistic decision making, and a wide variety of other techniques. Driving Storage Costs Down for AWS Customers.
This includes metrics such as query execution time, the number of queries executed per second, and the utilization of query cache and adaptive hash index. query cache: Disable (query_cache_size: 0, query_cache_type:OFF) innodb_adaptive_hash_index: Check adaptive hash index usage to determine its efficiency.
To monitor Redis® instances effectively, collect Redis metrics focusing on cache hit ratio, memory allocated, and latency threshold. Advanced monitoring techniques enable you to identify potential issues, such as high latency, CPU utilization, command throughput, and cache hit rate before they become major problems.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content