This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Efficient query caching is a critical part of application performance in data-intensive systems. Hibernate has supported query caching through its second-level cache and query cache mechanisms. released in December 2024, addresses these problems by introducing enhanced query caching mechanisms. Hibernate 6.3.0,
In this post, I’m going to break these processes down into each of: ? Caching them at the other end: How long should we cache files on a user’s device? Cache This is the easy one. Which brings me nicely on to… The important part of this section is cache busting. main.af8a22.css main.af8a22.css
Best Effort Regional Counter This type of counter is powered by EVCache , Netflix’s distributed caching solution built on the widely popular Memcached. Introducing sufficient jitter to the flush process can further reduce contention. This process can also be used to track the provenance of increments.
We introduce a caching mechanism in the API gateway layer, allowing us to offload processing from singleton leader elected controllers without giving up strict data consistency and guarantees clients observe. cell): Titus Job Coordinator is a leader elected process managing the active state of the system.
Caching is the process of storing frequently accessed data or resources in a temporary storage location, such as memory or disk, to improve retrieval speed and reduce the need for repetitive processing.
For the longest time now, I have been obsessed with caching. I think every developer of any discipline would agree that caching is important, but I do tend to find that, particularly with web developers, gaps in knowledge leave a lot of opportunities for optimisation on the table. Want to know everything (and more) about HTTP cache?
If you work in customer support for any kind of tech firm, you’re probably all too used to talking people through the intricate, tedious steps of clearing their cache and clearing their cookies. set ( ' Clear-Site-Data ' , ' cache ' ); } else { res. Well, there’s an easier way! Something maybe a little like this: const referer = req.
NCache Java Edition with distributed cache technique is a powerful tool that helps Java applications run faster, handle more users, and be more reliable. It doesn't matter if you've been developing for years or if you're new to caching , this article will help you get a good start with NCache Java Edition.
KeyCDN has significantly simplified the way images are transformed and delivered with our Image Processing service. Our Image Processing service makes it easy to do that. Our Image Processing service will automatically optimize the image quality and reduce the size of the image if no query string is provided.
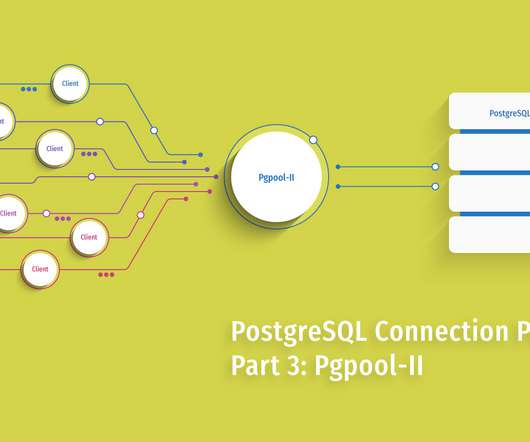
The Pgpool-II parent process forks 32 child processes by default – these are available for connection. The architecture is similar to PostgreSQL server: one process = one connection. It also forks the ‘pcp process’ which is used for administrative tasks, and beyond the scope of this post. Expert Tip.
This process involves: Identifying Stakeholders: Determine who is impacted by the issue and whose input is crucial for a successful resolution. Understanding the BiggerPicture Lets take a comprehensive look at all the elements involved and how they interconnect. We should aim to address questions such as: What is vital to the business?
A shared characteristic in most (if not all) databases, be them traditional relational databases like Oracle, MySQL, and PostgreSQL or some kind of NoSQL-style database like MongoDB, is the use of a caching mechanism to keep (a copy of) part of the data in memory. How do you know if your MySQL database caching is operating efficiently?
Because microprocessors are so fast, computer architecture design has evolved towards adding various levels of caching between compute units and the main memory, in order to hide the latency of bringing the bits to the brains. Its goal is to assign running processes to time slices of the CPU in a “fair” way. Linux to the rescue?
The RAG process begins by summarizing and converting user prompts into queries that are sent to a search platform that uses semantic similarities to find relevant data in vector databases, semantic caches, or other online data sources. Observing AI models Running AI models at scale can be resource-intensive.
There are two major processes which gets executed when a user posts a photo on Instagram. Firstly, the synchronous process which is responsible for uploading image content on file storage, persisting the media metadata in graph data-storage, returning the confirmation message to the user and triggering the process to update the user activity.
These things can make the instrumentation process difficult with a custom SDK. To use the SDK, there are a few steps that you need to follow: Import the SDK. Instrument key portions of your application. Web Requests entry points. Database calls. Messaging calls. Outgoing Web Requests. Custom code. The Dynatrace OneAgent SDK is very intuitive.
By Xiaomei Liu , Rosanna Lee , Cyril Concolato Introduction Behind the scenes of the beloved Netflix streaming service and content, there are many technology innovations in media processing. Packaging has always been an important step in media processing. Uploading and downloading data always come with a penalty, namely latency.
Of the organizations in the Kubernetes survey, 71% run databases and caches in Kubernetes, representing a +48% year-over-year increase. Together with messaging systems (+36% growth), organizations are increasingly using databases and caches to persist application workload states.
You can see the actual command and args that were sub-processed in the Metaboost Execution section below. this could take a few minutes) All packages already cached in s3. All environments already cached in s3. py --environment=conda --config settings.metaboost/settings/compiled/settings.branch_demox.EXP_01.training.mP4eIStG.yaml
Browsers will cache tools popular among vocal, leading-edge developers. There's plenty of space for caching most popular frameworks. The best available proxy data also suggests that shared caches would have a minimal positive effect on performance. Browsers now understand the classic shared HTTP cache behaviour as a privacy bug.
In this example configuration, the ngsegment namespace is backed by both a Cassandra cluster and an EVCache caching layer, allowing for highly durable persistent storage and lower-latency point reads. "persistence_configuration":[ While processing this request, the server retrieves data from the backing store.
Memoization is the process of caching the results of a function call based on its input parameters. The useMemo() hook is a built-in React hook that allows you to optimize the performance of your React application by memoizing expensive computations.
We’re happy to announce that WebP Caching has landed! How Does WebP Caching Work? Either you take advantage of image processing where we convert the images automatically for you or you deliver the WebP assets from your origin based on the accept header. It’s all about the accept header sent from the client.
And while these examples were resolved by just asking a few questions, in many cases, the answers are more elusive, requiring real-time and historical drill-downs into the processes and dependencies specific to each host. Reduce inter-process communications overhead. Implement intelligent retry and failover processes.
The round trip also measures intermediate steps on that journey such as propagation delay, transmission delay, processing delay, etc. Interestingly, 304 responses are still a form of redirect: the server is redirecting your visitor back to their HTTP cache. Cache Everything If you’re going to do something, try only do it once.
delivering a large amount of business value in the process. The Tech Hollow , an OSS technology we released a few years ago, has been best described as a total high-density near cache : Total : The entire dataset is cached on each node?—?there there is no eviction policy, and there are no cache misses.
Amazon compute solutions are designed to streamline resource provisioning and container management with two services: AWS Lambda : Lambda provides serverless compute infrastructure that lets you run code in response to predetermined events or conditions and automatically manage all compute resources required for these processes. Data Store.
Further, Tractor Supply’s transition to Kubernetes introduced many new processes—particularly regarding security. With Dynatrace deep cluster monitoring, “we were able to do upfront detection of security processes consuming higher CPU time on the cluster,” Bollampally said. Further, as Tractor Supply Co.
Spring Boot 2 uses Micrometer as its default application metrics collector and automatically registers metrics for a wide variety of technologies, like JVM, CPU Usage, Spring MVC, and WebFlux request latencies, cache utilization, data source utilization, Rabbit MQ connection factories, and more. That’s a large amount of data to handle.
Rachel Kelley (AWS), Ranjit Raju (AWS) Rendering is core to the the VFX process VFX studios around the world create amazing imagery for Netflix productions. By: Peter Cioni (Netflix), Alex Schworer (Netflix), Mac Moore (Conductor Tech.), Rendering on AWS provides the flexibility to control how quickly a project is completed.
Development Process. Development Process. Instead, use the getter function because it can be mapped into any vue component using the mapGetters behaving like a computed property with the getters result cached based on its dependencies. Tools And Practices To Speed Up The Vue.js Tools And Practices To Speed Up The Vue.js
To prevent such a significant service disruption from happening again, we are taking several immediate and mid-term actions in addition to the existing rigorous automated testing process: Improve architectural design to eliminate SSO bottleneck risk.
In addition to Spark, we want to support last-mile data processing in Python, addressing use cases such as feature transformations, batch inference, and training. We use metaflow.Table to resolve all input shards which are distributed to Metaflow tasks which are responsible for processing terabytes of data collectively.
To avoid the ES query for the list of indices for every indexing request, we keep the list of indices in a distributed cache. We refresh this cache whenever a new index is created for the next time bucket, so that new assets will be indexed appropriately.
The voice service then constructs a message for the device and places it on the message queue, which is then processed and sent to Pushy to deliver to the device. The previous version of the message processor was a Mantis stream-processing job that processed messages from the message queue.
This allows the app to query a list of “paths” in each HTTP request, and get specially formatted JSON (jsonGraph) that we use to cache the data and hydrate the UI. The Not-so-good In the arduous process of breaking a monolith, you might get a sharp shard or two flung at you. This meant that data that was static (e.g.
Replays provide on-demand data about where conversion processes aren’t working. By analyzing sessions of new employees interacting with key tools, teams can provide detailed instructions that will help to streamline the onboarding process and get staff up to speed faster. Are customers losing interest? Enhancing error correction.
Our UI runs on top of a custom rendering engine which uses what we call a “surface cache” to optimize our use of graphics memory. Surface Cache Surface cache is a reserved pool in main memory (or separate graphics memory on a minority of systems) that the Netflix app uses for storing textures (decoded images and cached resources).
You can also analyze table metrics, such as cache hits and misses. Rather than processing simple time-series data, Dynatrace Davis® , our AI causation engine, maps data to a unified entity model using metrics, traces, logs, and real user data. Precise AI-powered answers for Azure Managed Instance for Apache Cassandra.
Missing Cache Settings – Make sure you cache resources that don’t change often on the browser or use a CDN. Or think of requesting a new drivers license which requires your implementation to reach out to many dependent systems, e.g. DMV, police records that are needed to kick off the process of renewing or issuing a new license.
While this strategy is effective, it’s not simple: highly dynamic sites can be difficult to extract styles from, the process needs to be automated, we have to make assumptions about what above the fold even is, it’s hard to capture edge cases, and tooling still in its relative infancy.
If that’s the case, the update process continues to the next set of clusters and that process continues until all clusters are updated to the new version. One of them being a small cache that would have brought the initial startup time down by about 95%. Step 4: Fixing the issue. Conclusion: Dynatrace for Developers.
Lambda then takes a snapshot of the memory and disk state of the initialized execution environment, persists the encrypted snapshot, and caches it for low-latency access. With SnapStart enabled, function code is initialized once when a function version is published. How does Dynatrace help? No manual configuration is necessary.
Moreover, features like Instant Run and the Gradle Build Cache weren’t supported. Out-of-the-box support for Instant Run and the Gradle Build Cache make the auto-instrumentation process barely noticeable. Performance-wise, bytecode instrumentation is a fast process that doesn’t impact build time.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content