This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Today, we’re excited to present the Distributed Counter Abstraction. In this context, they refer to a count very close to accurate, presented with minimal delays. After selecting a mode, users can interact with APIs without needing to worry about the underlying storage mechanisms and counting methods.
In the time since it was first presented as an advanced Mesos framework, Titus has transparently evolved from being built on top of Mesos to Kubernetes, handling an ever-increasing volume of containers. This blog post presents how our current iteration of Titus deals with high API call volumes by scaling out horizontally.
While Atlas is architected around compute & storage separation, and we could theoretically just scale the query layer to meet the increased query demand, every query, regardless of its type, has a data component that needs to be pushed down to the storage layer.
Of the organizations in the Kubernetes survey, 71% run databases and caches in Kubernetes, representing a +48% year-over-year increase. Together with messaging systems (+36% growth), organizations are increasingly using databases and caches to persist application workload states.
Building an elastic query engine on disaggregated storage , Vuppalapati, NSDI’20. This paper presents Snowflake design and implementation along with a discussion on how recent changes in cloud infrastructure (emerging hardware, fine-grained billing, etc.) But the ephemeral storage service for intermediate data is not based on S3.
A distributed storage system is foundational in today’s data-driven landscape, ensuring data spread over multiple servers is reliable, accessible, and manageable. Understanding distributed storage is imperative as data volumes and the need for robust storage solutions rise.
However, storing and querying such data presents a unique set of challenges: High Throughput : Managing up to 10 million writes per second while maintaining high availability. Storage Layer The storage layer for TimeSeries comprises a primary data store and an optional index data store. Note : With Cassandra 4.x
But we cannot search or present low latency retrievals from files Etc. The solution which we present in this blog is not limited to annotations and can be used for any other domain which uses ES and Cassandra as well. We store all OperationIDs which are in STARTED state in a distributed cache (EVCache) for fast access during searches.
When you want to know if a key is present or not in the list, you run it through the hash function and check if the corresponding bits in the bitmap are “1” or “0” If one of the bits is “0”, you know for sure the key is not in the list. If all the bits are “1”, the value may be present.
Since that presentation, Pushy has grown in both size and scope, and this article will be discussing the investments we’ve made to evolve Pushy for the next generation of features. KeyValue is an abstraction over the storage engine itself, which allows us to choose the best storage engine that meets our SLO needs.
Despite initial investment costs, DBMS presents long-term savings and improved efficiency through automated processes, efficient query optimizations, and scalability, contributing to enhanced decision-making and end-user productivity. By implementing data abstraction techniques, these challenges can be addressed more effectively.
The same data, in the form of pages inside the Wiredtiger cache, are also marked dirty. At every checkpoint interval (Default 60 seconds), MongoDB flushes the modified pages that are marked as dirty in the cache to their respective data files (both collection-*.wt This happens at every journalCommitIntervalMs. wt and index-*.wt).
The Solution: Distributed Caching. The solution to this challenge is to use scalable, memory-based data storage for fast-changing data so that web sites can keep up with exploding workloads. It’s not enough simply to lash together a set of servers hosting a collection of in-memory caches.
The Solution: Distributed Caching. The solution to this challenge is to use scalable, memory-based data storage for fast-changing data so that web sites can keep up with exploding workloads. It’s not enough simply to lash together a set of servers hosting a collection of in-memory caches.
Each service encapsulates its own data and presents a hardened API for others to use. In response, we began to develop a collection of storage and database technologies to address the demanding scalability and reliability requirements of the Amazon.com ecommerce platform. The growth of Amazonâ??s Domain scaling limitations. SimpleDBâ??s
Instead of presenting you with a handful of random screenshots from our demo environment I reached out to Robert, a close friend of mine, who leads a development team with the current task to re-architect and re-platform their multi-tenant SaaS-based eCommerce platform. PostgreSQL & Elastic for data storage. REDIS for caching.
Effective management of memory stores with policies like LRU/LFU proactive monitoring of the replication process and advanced metrics such as cache hit ratio and persistence indicators are crucial for ensuring data integrity and optimizing Redis’s performance. Cache Hit Ratio The cache hit ratio represents the efficiency of cache usage.
To monitor Redis instances effectively, collect Redis metrics focusing on cache hit ratio, memory allocated, and latency threshold. Advanced monitoring techniques enable you to identify potential issues, such as high latency, CPU utilization, command throughput, and cache hit rate before they become major problems.
We use high-performance transactions systems, complex rendering and object caching, workflow and queuing systems, business intelligence and data analytics, machine learning and pattern recognition, neural networks and probabilistic decision making, and a wide variety of other techniques. Driving Storage Costs Down for AWS Customers.
To monitor Redis® instances effectively, collect Redis metrics focusing on cache hit ratio, memory allocated, and latency threshold. Advanced monitoring techniques enable you to identify potential issues, such as high latency, CPU utilization, command throughput, and cache hit rate before they become major problems.
This doesn't mean relational databases do not provide utility in present-day development and are not available, scalable, or provide high performance. This consistent performance is a big part of why the Snapchat Stories feature , which includes Snapchat's largest storage write workload, moved to DynamoDB. The opposite is true.
Titus, the Netflix container management platform, is now open source,” [link] Apr 2018 - [Cutress 19] Dr. DDR6: Here's What to Expect in RAM Modules,” [link] Nov 2020 - [Salter 20] Jim Salter, “Western Digital releases new 18TB, 20TB EAMR drives,” [link] Jul 2020 - [Spier 20] Martin Spier, Brendan Gregg, et al.,
This blog post gives a glimpse of the computer systems research papers presented at the USENIX Annual Technical Conference (ATC) 2019, with an emphasis on systems that use new hardware architectures. GAIA proposed to expand the OS page cache into accelerator memory. Heterogeneous ISA. Programmable I/O Devices.
Captivating Data Visualization Data visualization is a key aspect of Power BI, enabling users to present complex data in a visually compelling manner. It involves pushing as much of the data transformation and filtering operations back to the data source (e.g., MySQL) instead of performing them within the BI tool (e.g.,
Note: We received feedback that there was some confusion on us calling this functionality “tail of the log caching” because our documentation and prior history has referred to the tail of the log as the portion of the hardened log that has not been backed up. Block storage is what you think of today as disk access.
When it comes to innovation, most of CMS solutions are constrained by their legacy architecture (read strong coupling between content management and content presentation) which makes it difficult to serve content to new types of emerging channels such as apps and devices. Eventually, we decided to move them to Jekyll.
Its raison d’être is to cache result rows from a plan subtree, then replay those rows on subsequent iterations if any correlated loop parameters are unchanged. Table-valued functions use a table variable, which can be used to cache and replay results in suitable circumstances. Spools are the least costly way to cache partial results.
Attempted modifications in JavaScript might break page functionality, inhibit proper rendering, or present other problems. A natural language translation service presenting a news website article translated from English to Japanese. Search Engine And Web Archive Cached Results. Large preview ). Large preview ).
5 Anti-requirements are deceptively simple: you create some fake requirement concerning two attributes and present it to business stakeholders. “If From a technical perspective, attributes that change together should also be cached similarly. ViewModel composition techniques also allow flexibility in terms of data storage technology.
A then-representative $200USD device had 4-8 slow (in-order, low-cache) cores, ~2GiB of RAM, and relatively slow MLC NAND flash storage. This 2GiB RAM, Android 9 stalwart features the all-too classic lines of a Quad-core A53 (1.4GHz, small mercies) CPU, tastefully presented in a charming 5.5" The Moto G4 , for example.
Configure the PostgreSQL hostname by editing configuration files and restarting the server, with secure storage of connection details to enhance security. The host variable can be found within specified code strings dedicated to creating/modifying content present on that particular remotely located Postgresql platform system.
For INSERT.SELECT , SQL Server makes its own determination whether to ensure rows are presented to the Clustered Index Insert operator in key order or not. The estimated data size calculation here is subject to the same quirks described in the previous article for heaps , except that the 8-byte RID is not present. Trace Flag.
Chrome has missed several APIs for 3+ years: Storage Access API. Helps developers present better, more contextual options and prompts, reducing user annoyance and "prompt spam" Screen Wakelock. Important for apps that present boarding passes and QR codes for scanning, as well as and presentation apps (e.g.
Based on these findings, the authors present four guidelines to get the best performance out of this memory today. Optane DIMMs have lower latency and higher bandwidth than storage devices connected over PCIe (including Optane SSDs), and present a memory address-based interface as opposed to a block-based NVMe interface.
Obviously, there are ways to monitor the backup through storage monitoring or Pod status, but why bother if the Operator already provides this information? Metrics can be captured from the status field of the Custom Resources if present. 274] "discovery finished, cache updated" I0706 14:43:28.285652 1 metrics_handler.go:99]
Guest profiles also start with empty caches, empty cookie stores, empty browser storage, etc. These may get populated during testing, but we can clear them at any time via Application > Storage > Clear Site Data in DevTools. Opening a guest profile in Chrome 2.
On the last morning of the conference Daniel Bittman presented some of the work being done in the context of the Twizzler OS project to explore new programming models for NVM. The beauty of persistent memory is that we can use memory layouts for persistent data (with some considerations for volatile caches etc. What about security?
When a blocking operator is present (for Halloween protection or any other reason), this scheme breaks down because more than one row can be read before any changes are made. Lock classes are needed for key lookups when a blocking operator is present before the lookup. Read Committed and Large Objects.
For example, a one-byte simple bitmap is capable of indicating whether eight contiguous build-side values are present or not. A range of values that does not start at zero can be encoded the same way by offsetting all values by the minimum value present in the set (which we know from the hash table statistics). Complex Bitmaps.
SET NOCOUNT , XACT_ABORT ON ; -- Prevent plan caching for this procedure. -- See [link]. When the SQL Server query processor needs to read or change data, it does so via one or more storage engine access methods. GOTO Start. OPEN SYMMETRIC KEY Banana. DECRYPTION BY CERTIFICATE Banana ; Start : -- Recreate the test table.
… based on interactions with enterprise customers, we expect that storage and inference of ML models will be subject to the same scrutiny and performance requirements of sensitive/mission-critical operational data. For single or very small numbers of predictions, Raven is faster due to SQL Server’s caching. The last word.
Please note that these are presented as general best practices. Depending on your setup, costs can include: Hardware devices (servers, storage devices, network switches, etc.) That will minimize problems that can occur when nodes share access to and the ability to modify the same memory or storage.
GO. -- Clear the plan cache. There is a final condition evaluated by storage engine code ( IndexDataSetSession::WakeUpInternal ) at execution time: DMLRequestSort is currently true ; and. GO. -- Clear the plan cache. We must also remember the final storage engine test for at least 100 rows: I >= 100. DETAILED'. )
MariaDB retains compatibility with MySQL, offers support for different programming languages, including Python, PHP, Java, and Perl, and works with all major open source storage engines such as MyRocks, Aria, and InnoDB. now a release candidate) SQL – Window Functions Present in MariaDB Server 10.2 In-development for MySQL 8.0 (now
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




























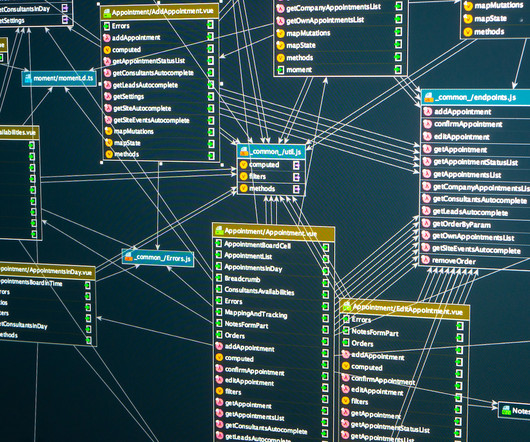



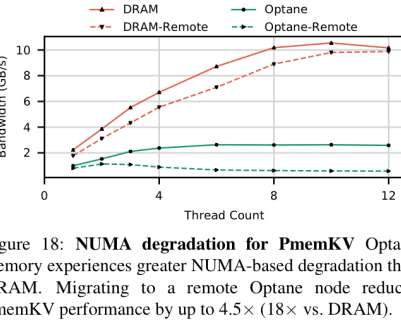

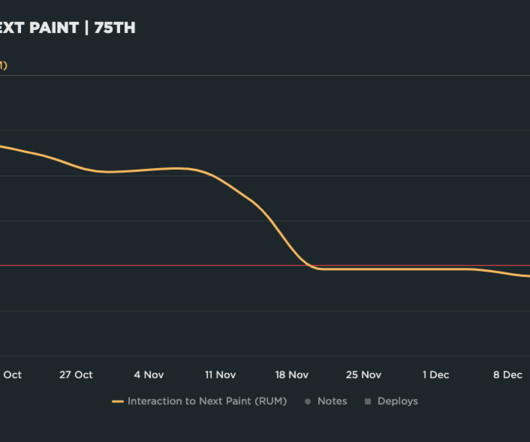




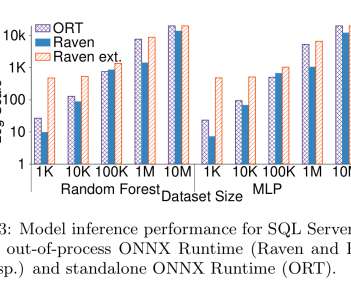









Let's personalize your content