This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Compressing them over the network: Which compression algorithm, if any, will we use? Caching them at the other end: How long should we cache files on a user’s device? Cache This is the easy one. Which brings me nicely on to… The important part of this section is cache busting. main.af8a22.css main.af8a22.css
Mobile applications (apps) are an increasingly important channel for reaching customers, but the distributed nature of mobile app platforms and delivery networks can cause performance problems that leave users frustrated, or worse, turning to competitors. Some of the most important KPIs are listed below. Performance optimization.
That is, relying on metrics, logs, and traces to understand what software is doing and where it’s running into snags. In addition to tracing, observability also defines two other key concepts, metrics and logs. When software runs in a monolithic stack on on-site servers, observability is manageable enough. What is OpenTelemetry?
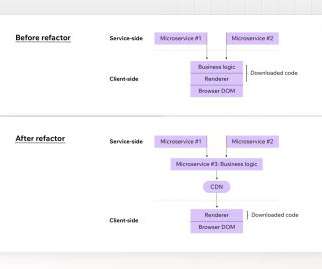
The GraphQL shim enabled client engineers to move quickly onto GraphQL, figure out client-side concerns like cache normalization, experiment with different GraphQL clients, and investigate client performance without being blocked by server-side migrations. So, we relied on higher-level metrics-based testing: AB Testing and Sticky Canaries.
Thats why the Time to First Byte (TTFB) metric is important: it measures how soon after navigation the browser starts receiving the HTML response. But actually, theres a lot more to optimizing this metric. What Components Make Up The Time To First Byte Metric? TTFB stands for Time to First Byte. But where does it measure from ?
I can reload the exact same page under the exact same network conditions over and over, and I can guarantee I will not get the exact same, say, DOMContentLoaded each time. As noted above, it’s not actually possible to improve certain metrics in their own right. There are myriad reasons for this that I won’t cover here. duration ).
This gives fascinating insights into the network topography of our visitors, and how much we might be impacted by high latency regions. You can’t change that someone was from Nigeria, you can’t change that someone was on a mobile, and you can’t change their network conditions. RTT data should be seen as an insight and not a metric.
Depending on how it is configured, Redis can act like a database, a cache or a message broker. Session Cache: Many websites leverage Redis Strings to create a session cache to speed up their website experience by caching HTML fragments or pages. It’s important to note that Redis is a NoSQL database system. Redis Sets.
You will need to know which monitoring metrics for Redis to watch and a tool to monitor these critical server metrics to ensure its health. Redis returns a big list of database metrics when you run the info command on the Redis shell. You can pick a smart selection of relevant metrics from these.
Interestingly, our partner RedHat reported in 2021 that around 80% of deployed workloads are databases or data caches, storing data in persistent volume claims (PVCs). For example, let’s say you have an idea for a new social network and decide to use Kubernetes as your container management platform.
In addition, with 193M members and counting, there is a huge diversity in the networks that stream our content as well as in our members’ bandwidth. It is, thus, imperative that we are sensible in the use of the network and of the bandwidth we require. 264/AVC Main profile per-title encodes.
This allows the app to query a list of “paths” in each HTTP request, and get specially formatted JSON (jsonGraph) that we use to cache the data and hydrate the UI. To prepare ourselves for a big change in the tech stack of our endpoint, we decided to track metrics around the time taken to respond to queries.
Lambda then takes a snapshot of the memory and disk state of the initialized execution environment, persists the encrypted snapshot, and caches it for low-latency access. With SnapStart enabled, function code is initialized once when a function version is published. Users can take advantage of the platform features immediately.
Browsers will cache tools popular among vocal, leading-edge developers. There's plenty of space for caching most popular frameworks. The best available proxy data also suggests that shared caches would have a minimal positive effect on performance. Browsers now understand the classic shared HTTP cache behaviour as a privacy bug.
Storing frequently accessed data in faster storage, usually in-memory caching, improves data retrieval speed and overall system performance. Beyond A study by Amazon found that increasing page load time by just 100 milliseconds costs 1% in sales. Beyond efficiency, validating performance thresholds is also crucial for revenues.
Performance Game Changer: Browser Back/Forward Cache. Performance Game Changer: Browser Back/Forward Cache. With that caveat out of the way, let’s get to the guts of the article: What is the Back/Forward Cache and why does it matter so much? Didn’t The HTTP Cache Do All That Anyway? Barry Pollard.
Annie leads the Chrome Speed Metrics team at Google, which has arguably had the most significant impact on web performance of the past decade. It's really important to acknowledge that none of this would have been possible without the great work from Annie and her small-but-mighty Speed Metrics team at Google. Nice job, everyone!
Most monitoring tools for migrations, development, and operations focus on collecting and aggregating the three pillars of observability— metrics, traces, and logs. Using a data-driven approach to size Azure resources, Dynatrace OneAgent captures host metrics out-of-the-box to assess CPU, memory, and network utilization on a VM host.
However, one metric I feel that front-end developers overlook all too quickly is Time to First Byte (TTFB). The reason is because mobile networks are, as a rule, high latency connections. only to find that the resource they’re requesting isn’t in that PoP ’s cache. can all provide valuable insights.
A well-established metric we provide is APDEX , which tell us how users are perceiving page load times (time to the first byte, page speed, speed index), errors (JavaScript errors, crashes,) and also factors in the overall user journey (each user interaction) including their environment (browser, geolocation, bandwidth). N+1 Query Pattern.
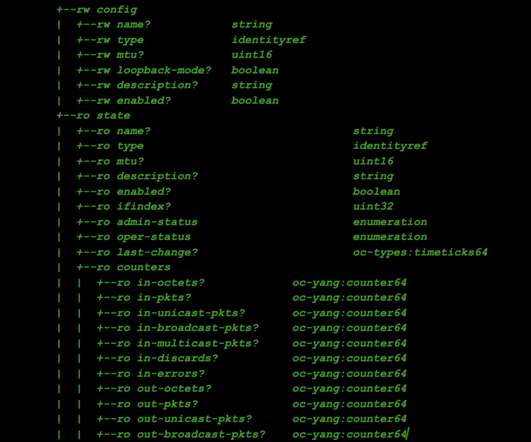
Introducing gnmi-gateway: a modular, distributed, and highly available service for modern network telemetry via OpenConfig and gNMI By: Colin McIntosh, Michael Costello Netflix runs its own content delivery network, Open Connect , which delivers all streaming traffic to our members.
As a networking team, we naturally lean towards abstracting the communication layer with encapsulation wherever possible. The DeviceToDeviceManager is also responsible for observability, with metrics around cache hits, calls to the data store, message delivery rates, and latency percentile measurements.
This blog post introduces the new REST API improvements and some best practices for streamlining API requests and decreasing load on the API by reducing the number of requests required for reporting and reducing the network bandwidth required for implementing common API use cases.
Some of the metrics we use to measure performance on the Netflix TV app include animation frames per second (FPS), key input responsiveness (the amount of time before a member’s key press renders a change in the UI), video playback speed, and app start-up time. The majority of legacy devices run at 28MB of surface cache.
A vast majority of the features are the same, outside of these advanced features available through the BYOC model: Virtual Private Clouds / Virtual Networks. Amazon Virtual Private Clouds (VPC) and Azure Virtual Networks (VNET) are private, isolated sections of the cloud infrastructure where you can launch resources. Security Groups.
Amazon ElastiCache is a fully managed, in-memory caching service for customers to optimize the latency, performance and cost of their read workloads. The db.cr1.8xlarge has 88 ECUs, 244GB of memory, high-bandwidth network, and the ability to deliver up to 20,000 IOPS for MySQL 5.6,
One could argue this is a metric-driven decision. Simulate bad network conditions and slow CPUs and make your project resilient. How would you architecture a non-trivial size web project (client, server, databases, caching layer)? Lots of case studies where changes in performance led to key metric improvement.
Buckle up as we delve into the world of Redis monitoring, exploring the most important Redis metrics, discussing essential tools, and even peering into the future of Redis performance management. Identifying key Redis metrics such as latency, CPU usage, and memory metrics is crucial for effective Redis monitoring.
It is well known and fairly obvious that in geographically distributed systems or other environments with probable network partitions or delays it is not generally possible to maintain high availability without sacrificing consistency because isolated parts of the database have to operate independently in case of network partition.
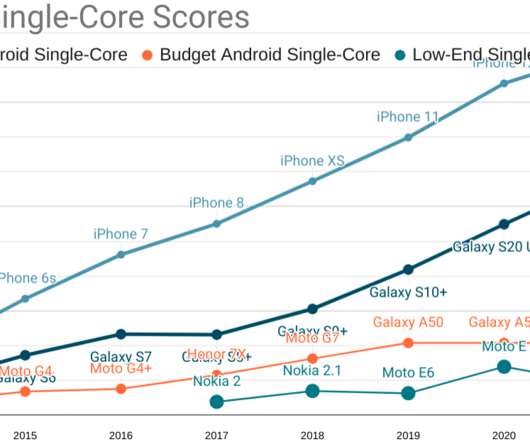
While mobile devices have come a long way in terms of network and CPU speed, many of them are still significantly underpowered when compared to desktops, especially in countries where mobile connectivity is still poor. Better tooling and metrics standardization. In other words, the field lacked standardization.
This header can be set on the response of any network resource, such as XHR, fetch, images, HTML, stylesheets, etc. The header is constructed via a name with an optional description and/or metric value. These subtypes are currently the only subtypes related to network requests and thus exposing the Server-Timing information.
Web performance metrics track the efficiency (or lack thereof) of any individual aspect of your website’s performance. Once you have started collecting some of these must-track web performance metrics for your website, inefficiencies will become clearer. Top 10 Web Perf Metrics to Track. Time to First Byte. Bounce Rate.
Buckle up as we delve into the world of Redis® monitoring, exploring the most important Redis® metrics, discussing essential tools, and even peering into the future of Redis® performance management. Identifying key Redis® metrics such as latency, CPU usage, and memory metrics is crucial for effective Redis monitoring.
Have you ever looked at the page speed metrics – such as Start Render and Largest Contentful Paint – for your site in both your synthetic and real user monitoring tools and wondered "Why are these numbers so different?" Browser use (and abuse) Browser age is just one issue. Over time, these files pile up and slow down the browser.
This includes metrics such as query execution time, the number of queries executed per second, and the utilization of query cache and adaptive hash index. query cache: Disable (query_cache_size: 0, query_cache_type:OFF) innodb_adaptive_hash_index: Check adaptive hash index usage to determine its efficiency.
Thanks to progress in networks and browsers (but not devices), a more generous global budget cap has emerged for sites constructed the "modern" way: ~100KiB of HTML/CSS/fonts and ~300-350KiB of JS (compressed) is the new rule-of-thumb limit for at least the next year or two. Modern network performance and availability.
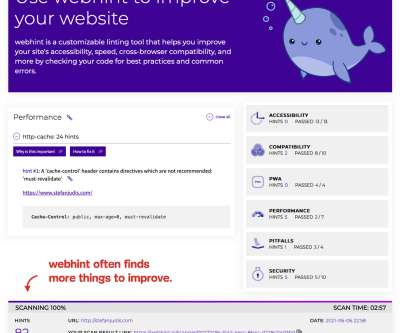
Are all the caching headers set correctly? Waterfaller: A Tool Focusing On Network Waterfalls. Contrary to Lighthouse or WebPage Test, Waterfaller focuses on one thing alone — issues in the network waterfall. Waterfaller focuses on issues in the network waterfall and provides recommendations for improvement.
The Four LCP Subparts LCP subparts split the Largest Contentful Paint metric into four different components: Time to First Byte (TTFB) : How quickly the server responds to the document request. Expand the Largest Contentful Paint metric to see subparts and other details related to your LCP score. Its not (yet?)
Site performance is potentially the most important metric. Having a slow site might leave you on page 452 of search results, regardless of any other metric. Using a network request inspector, I’m going to see if there’s anything we can remove via the Network panel in DevTools.
We do not use it for metrics, histograms, timers, or any such near-real time analytics use case. Challenges At Netflix, temporal data is continuously generated and utilized, whether from user interactions like video-play events, asset impressions, or complex micro-service network activities. Also, with Cassandra 4.x,
Last week we looked at a function shipping solution to the problem; Cloudburst uses the more common data shipping to bring data to caches next to function runtimes (though you could also make a case that the scheduling algorithm placing function execution in locations where the data is cached a flavour of function-shipping too).
TL;DR : To serve users at the 75 th percentile ( P75 ) of devices and networks, we can now afford ~150KiB of HTML/CSS/fonts and ~300-350KiB of JavaScript (gzipped). This is a slight improvement on last year's budgets , thanks to device and network improvements. Networks #. This is an ethical crisis for the frontend.
Failing that, we are usually able to connect to home or public WiFi networks that are on fast broadband connections and have effectively unlimited data. The speed of mobile networks, too, varies considerably between countries. As for mobile network connection type, 84.7% For reference, the metric is $1.19 Mbps upload.
But do you know how Lighthouse calculates performance metrics like First Contentful Paint (FCP), Total Blocking Time (TBT), and Cumulative Layout Shift (CLS)? Still, there’s nothing in there to tell us about the data Lighthouse is using to evaluate metrics. But it comes with caveats.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content