This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This gives fascinating insights into the network topography of our visitors, and how much we might be impacted by high latency regions. Round-trip-time (RTT) is basically a measure of latency—how long did it take to get from one endpoint to another and back again? What is RTT? RTT isn’t a you-thing, it’s a them-thing.
Uploading and downloading data always come with a penalty, namely latency. Virtual Assembly Figure 3 describes how a virtual assembly of the encoded chunks replaces the physical assembly used in our previous architecture. For write operations, those challenges do not apply.
The new Amazon capability enables customers to improve the startup latency of their functions from several seconds to as low as sub-second (up to 10 times faster) at P99 (the 99th latency percentile). This can cause latency outliers and may lead to a poor end-user experience for latency-sensitive applications.
The first was voice control, where you can play a title or search using your virtual assistant with a voice command like “Show me Stranger Things on Netflix.” (See In our case, we value low latency — the faster we can read from KeyValue, the faster these messages can get delivered.
A vast majority of the features are the same, outside of these advanced features available through the BYOC model: Virtual Private Clouds / Virtual Networks. Amazon Virtual Private Clouds (VPC) and Azure Virtual Networks (VNET) are private, isolated sections of the cloud infrastructure where you can launch resources.
Amazon ElastiCache is a fully managed, in-memory caching service for customers to optimize the latency, performance and cost of their read workloads. We allow customers to provision the number of input and output operations (IOPS) they require by using Amazon RDS with Provisioned IOPS.
Here’s how the same test performed when running Percona Distribution for PostgreSQL 14 on these same servers: Queries: reads Queries: writes Queries: other Queries: total Transactions Latency (95th) MySQL (A) 1584986 1645000 245322 3475308 122277 20137.61 MySQL (B) 2517529 2610323 389048 5516900 194140 11523.48
In-Memory Storage Engine, as the name suggests, stores data in memory for faster performance and lower latencies. However, due to its reliance on the virtual memory subsystem, it is not suitable for larger datasets. It uses a filesystem cache and write-ahead log for crash recovery.
Amazon DynamoDB offers low, predictable latencies at any scale. This is not just predictability of median performance and latency, but also at the end of the distribution (the 99.9th percentile), so we could provide acceptable performance for virtually every customer. s read latency, particularly as dataset sizes grow.
My personal opinion is that I don't see a widespread need for more capacity given horizontal scaling and servers that can already exceed 1 Tbyte of DRAM; bandwidth is also helpful, but I'd be concerned about the increased latency for adding a hop to more memory. Ford, et al., “TCP
Back on December 5, 2017, Microsoft announced that they were using AMD EPYC 7551 processors in their storage-optimized Lv2-Series virtual machines. The L3 cache size is 64MB. The L3 cache size is 64MB. The key specifications for the Lsv2 series virtual machines are shown in Table 1. lanes for I/O connectivity.
Likewise, object access paths must be heavily multi-threaded and avoid lock contention to minimize access latency and maximize throughput. Given all this, we thought it would be a good opportunity to see how we are doing relative to the competition, and in particular, relative to Microsoft’s AppFabric caching for Windows on-premise servers.
VPC Endpoints give you the ability to control whether network traffic between your application and DynamoDB traverses the public Internet or stays within your virtual private cloud. Performant – DynamoDB consistently delivers single-digit millisecond latencies even as your traffic volume increases.
For example, iostat(1), or a monitoring agent, may tell you your average disk latency, but not the distribution of this latency. For smaller environments, it can be of more use helping eliminate latency outliers. bpftrace uses BPF (Berkeley Packet Filter), an in-kernel execution engine that processes a virtual instruction set.
There are three common mechanisms to access remote memory: modifying applications, modifying virtual memory, and hardware-level cache coherence support. even lowered the latency by introducing a multi-headed device that collapses switches and memory controllers. The recently announced CXL3.0
Durability Availability Fault tolerance These combined outcomes help minimize latency experienced by clients spread across different geographical regions. By leveraging the strengths of both fields, organizations can attain increased efficiency and operational capability within a highly virtualized landscape.
In both cases, when using virtually-synchronous replication, the process will require certification from each node and local (by node) write; as such, the number of writes is NOT distributed across multiple nodes but duplicated. Because the solutions still rely on writing in one single node that works as Primary.
You might think of it like racing a car in virtual reality, where the conditions are decided in advance, rather than racing on a live track where conditions may vary. INP is a measure of the latency for all interactions on a given page, where the highest latency — or close to it — informs the final score.
My personal opinion is that I don't see a widespread need for more capacity given horizontal scaling and servers that can already exceed 1 Tbyte of DRAM; bandwidth is also helpful, but I'd be concerned about the increased latency for adding a hop to more memory. Ford, et al., “TCP
OSes usually show you virtual memory and resident memory, shown as the "VIRT" and "RES" columns in top. Short durations can be useful for understanding how well a WSS will fit into the CPU caches (L1/L2/L3, TLB L1/L2, etc). That's the working set size. It is used for capacity planning and scalability analysis. Consider these overheads.
Fast forward a few years after Azure SQL Database was released to when Azure SQL Managed Instance was in public preview, and "vCores" (virtual cores) were announced for Azure SQL Database. Hyperscale achieves high performance from each compute node having SSD-based caches which helps minimize the network round trips to fetch data.
A CDN (Content Delivery Network) is a network of geographically distributed servers that brings web content closer to where end users are located, to ensure high availability, optimized performance and low latency. In case of an error, a Virtual Edge solution also enables reverting to the previous configuration easily and quickly.5.
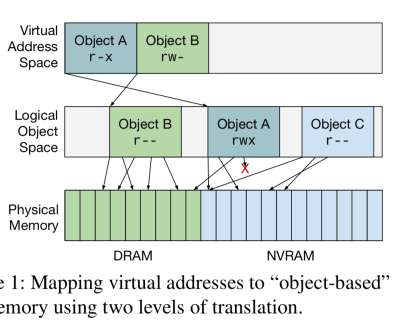
This is a companion paper to the " persistent problem " piece that we looked at earlier this week, going a little deeper into the object pointer representation choices and the mapping of a virtual object space into physical address spaces. " Epheremal virtual addresses don’t cut it as the basis for persistent pointers.
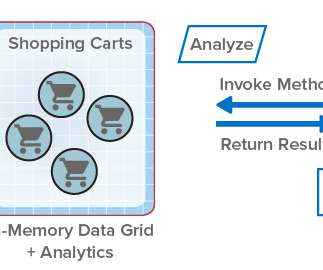
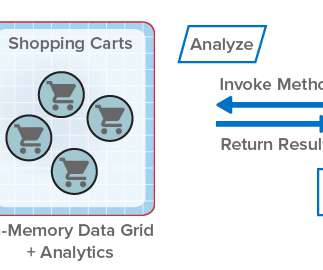
For more than fifteen years, ScaleOut StateServer® has demonstrated technology leadership as an in-memory data grid (IMDG) and distributed cache. Designed to help scalable applications deliver high performance, it stores live, fast-changing data in memory (DRAM) for fast updates and retrieval. The Challenges with Parallel Queries.
For more than fifteen years, ScaleOut StateServer® has demonstrated technology leadership as an in-memory data grid (IMDG) and distributed cache. Designed to help scalable applications deliver high performance, it stores live, fast-changing data in memory (DRAM) for fast updates and retrieval. The Challenges with Parallel Queries.
Microarchitectural state of interest includes data and instruction caches, TLBs, branch predictors, instruction- and data-prefetcher state machines, and DRAM row buffers. cache) can be partitioned across domains; for those that are instead time-multiplexed, we have to flush them during domain switches.
Some are standard, offering the basic services you need to ensure traffic routing and low latency, while others offer premium services like advanced security capabilities. Split and Separate Static and Dynamic TrafficStatic traffic is traffic that is cached close to the user and stored and served to them by the nearest server.
Given its unchanging nature, static content is ideal for caching. This type of traffic originates directly from the server, making it more challenging to handle due to latency and server load considerations; it’s hard but not impossible. It doesn’t change very often and is generally not affected by user sessions.
Therefore any programming abstraction must be low latency and the kernel needs to be kept off the path of persistent data access as much as possible. The beauty of persistent memory is that we can use memory layouts for persistent data (with some considerations for volatile caches etc. in front of that memory , as we saw last week).
Now in development in WebKit after years of radio silence, WebXR APIs provide Augmented Reality and Virtual Reality input and scene information to web applications. For heavily latency-sensitive use-cases like WebXR, this is a critical component in delivering a good experience. Offscreen Canvas. Content Indexing. PWA App Shortcuts.
This type of traffic originates directly from the server, making it more challenging to handle due to latency and server load considerations; it’s hard but not impossible. Statistics reveal that a 1% improvement in latency can lead to a 3% increase in viewer engagement, highlighting its significance in live content delivery.3.
A CDN (Content Delivery Network) is a network of geographically distributed servers that brings web content closer to where end users are located, to ensure high availability, optimized performance and low latency. In case of an error, a Virtual Edge solution also enables reverting to the previous configuration easily and quickly.5.
with its low latency I/O operations, gives the benefit of ‘No buffering’ to developers. React is an open-source front-end library based on JavaScript, created and maintained by Facebook, and is well known for its virtual DOM feature. The performance of React improves because of the Virtual DOM algorithm. Faster virtual DOM.
Operating System (OS) settings Swappiness Swappiness is a Linux kernel setting that influences the behavior of the Virtual Memory manager when it needs to allocate a swap, ranging from 0-100. The CFQ works well for many general use cases but lacks latency guarantees. Without further ado, let’s start with the OS settings.
Some are standard, offering the basic services you need to ensure traffic routing and low latency, while others offer premium services like advanced security capabilities. Split and Separate Static and Dynamic TrafficStatic traffic is traffic that is cached close to the user and stored and served to them by the nearest server.
OSes usually show you virtual memory and resident memory, shown as the "VIRT" and "RES" columns in top. Short durations can be useful for understanding how well a WSS will fit into the CPU caches (L1/L2/L3, TLB L1/L2, etc). That's the working set size. It is used for capacity planning and scalability analysis. Consider these overheads.
Additionally for the log disk component it is latency for an individual write that is crucial rather than the total I/O bandwidth. The first example shows a data load, the second a TPC-C based workload with 5 virtual users and the 2nd example with 10 virtual users. SQL> alter system flush buffer_cache; System altered.
Stable media is commonly physical disk storage, but other devices and certain caching facilities qualify as well. Many high-end disk subsystems provide high-speed cache facilities to reduce the latency of read and write operations. This cache is often supported by a battery-powered backup facility.
While we understand it’s virtually impossible to achieve a linear increase in throughput as the number of vCPUs grow, a near-linear increase is attainable. What’s worse, average latency degraded by more than 50%, with both CPU and latency patterns becoming more “choppy.” This was our starting point for troubleshooting.
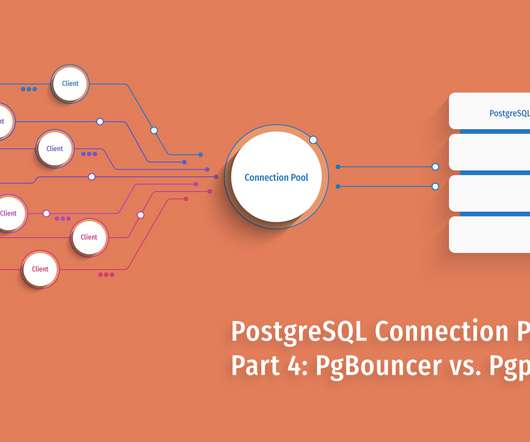
PgBouncer provides a virtual database that reports various useful statistics. Also, note the test here was actually perfectly crafted for Pgpool-II – since when N > 32, the number of clients and number of children processes were the same, and hence, each reconnection was guaranteed to find a cached process. Administration.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content