This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
By: Rajiv Shringi , Oleksii Tkachuk , Kartik Sathyanarayanan Introduction In our previous blog post, we introduced Netflix’s TimeSeries Abstraction , a distributed service designed to store and query large volumes of temporal event data with low millisecond latencies. Today, we’re excited to present the Distributed Counter Abstraction.
These include challenges with tail latency and idempotency, managing “wide” partitions with many rows, handling single large “fat” columns, and slow response pagination. It also serves as central configuration of access patterns such as consistency or latency targets. Useful for keeping “n-newest” or prefix path deletion.
The GraphQL shim enabled client engineers to move quickly onto GraphQL, figure out client-side concerns like cache normalization, experiment with different GraphQL clients, and investigate client performance without being blocked by server-side migrations. To launch Phase 1 safely, we used AB Testing.
Migrating Critical Traffic At Scale with No Downtime — Part 1 Shyam Gala , Javier Fernandez-Ivern , Anup Rokkam Pratap , Devang Shah Hundreds of millions of customers tune into Netflix every day, expecting an uninterrupted and immersive streaming experience. It helps expose memory leaks, deadlocks, caching issues, and other system issues.
Dynomite is a Netflix open source wrapper around Redis that provides a few additional features like auto-sharding and cross-region replication, and it provided Pushy with low latency and easy record expiry, both of which are critical for Pushy’s workload. As Pushy’s portfolio grew, we experienced some pain points with Dynomite.
Rajiv Shringi Vinay Chella Kaidan Fullerton Oleksii Tkachuk Joey Lynch Introduction As Netflix continues to expand and diversify into various sectors like Video on Demand and Gaming , the ability to ingest and store vast amounts of temporal data — often reaching petabytes — with millisecond access latency has become increasingly vital.
Uploading and downloading data always come with a penalty, namely latency. Figure 3: Video Processing with Index and Virtual Assembly Using virtual assembly greatly improves the latency performance of the ProRes 422 HQ proxy generation by removing one round trip of cloud downloading and cloud uploading by the physical assembler.
If we were to select the most important MySQL setting, if we were given a freshly installed MySQL or Percona Server for MySQL and could only tune a single MySQL variable, which one would it be? To be fair, that is also true with PostgreSQL; it hasn’t been tuned either, and it, too, can also perform much better.
Key Takeaways Critical performance indicators such as latency, CPU usage, memory utilization, hit rate, and number of connected clients/slaves/evictions must be monitored to maintain Redis’s high throughput and low latency capabilities. It can achieve impressive performance, handling up to 50 million operations per second.
This article will cover many areas that database administrators need to be aware of in order to properly license, recover, and tune a Reporting Services installation. Tuning Options. Tuning SSRS is much like any other application. Disk latency for ReportServer and ReportServerTempDB are very important. General Tuning.
This may help tune your table level autovacuum settings appropriately. Tuning Autovacuum in PostgreSQL. How do we identify the tables that need their autovacuum settings tuned ? . In order to tune autovacuum for tables individually, you must know the number of inserts/deletes/updates on a table for an interval.
The POP is strategially located within the country and lowers latency overall. KeyCDN is always on the lookout for ways to minimize latency and accelerate asset delivery worldwide. Hola Mexico! We've launched our new point of presence (POP) in Mexico City.
As developers, we rightfully obsess about the customer experience, relentlessly working to squeeze every millisecond out of the critical rendering path, optimize input latency, and eliminate jank. On top of this foundation, we add layers of caching, prerendering and edge delivery optimizations — not the other way around.
Some features (as an example) include Device Type ID, SDK Version, Buffer Sizes, Cache Capacities, UI resolution, Chipset Manufacturer and Brand. Internally, the app caches several pre-fetched data, images, descriptions etc, and the time spent in the level could indicate whether or not those caches are cleared.
By caching hot datasets, indexes, and ongoing changes, InnoDB can provide faster response times and utilize disk IO in a much more optimal way. If you see concurrency issues, you can tune this variable. Application tuning for InnoDB Make sure your application is prepared to handle deadlocks that may happen. I hope this helps!
The image below shows a significant drop in latency once we've launched the new point of presence in Israel. In fact, latency has been reduced by almost 50%! With a total of 5 POPs in Oceania, this continent benefits from lower latency with every POP added. With a population of 2.5 Happy content delivery everyone!
For most high-end processors these values have remained in the range of 75% to 85% of the peak DRAM bandwidth of the system over the past 15-20 years — an amazing accomplishment given the increase in core count (with its associated cache coherence issues), number of DRAM channels, and ever-increasing pipelining of the DRAMs themselves.
While there is no magic bullet for MySQL performance tuning, there are a few areas that can be focused on upfront that can dramatically improve the performance of your MySQL installation. What are the Benefits of MySQL Performance Tuning? A finely tuned database processes queries more efficiently, leading to swifter results.
This way, log event processing can resume event-by-event afterwards, eventually discovering the watermarks, without ever needing to cache log event entries. Passive instances across regions are also possible, though it is recommended to operate in the same region as the database host in order to keep the change capture latencies low.
This way, log event processing can resume event-by-event afterwards, eventually discovering the watermarks, without ever needing to cache log event entries. Passive instances across regions are also possible, though it is recommended to operate in the same region as the database host in order to keep the change capture latencies low.
Performant – DynamoDB consistently delivers single-digit millisecond latencies even as your traffic volume increases. DynamoDB automatically re-distributes your data to healthy servers to ensure there are always multiple replicas of your data without you needing to intervene.
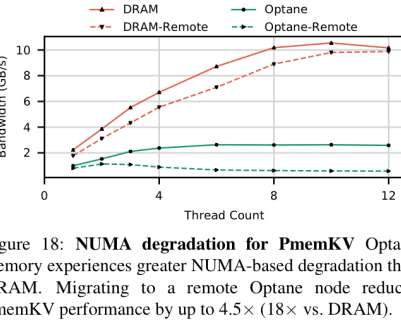
higher latency and lower bandwidth)… We have found the actual behavior of Optane DIMMs to be more complicated and nuanced than the "slower, persistent DRAM" label would suggest. The read latency for Optane is 2x-3x higher than DRAM. Use non-temporal stores for large transfers, and control cache evictions.
KeyCDN is always looking for ways to minimize latency and accelerate the delivery of assets worldwide. If you'd like to request a POP in another location or a new feature please let us know and stay tuned for more exciting announcements. So far, we could cover Latin America through Mexico City, Santiago, and São Paulo.
With a dedicated POP, latency for visitors is reduced even further, resulting in better loading times. If you want to see a POP in another location or a new feature, please let us know and stay tuned for more exciting announcements. The new POPs are in production and have been automatically added to all existing Zones.
A co-worker introduced me to Craig Hanson and Pat Crain's performance mantras, which neatly summarize much of what we do in performance analysis and tuning. In some cases, a benchmark may appear to exceed network bandwidth because it returns from a local memory cache instead of the remote target. They are: **Performance mantras**.
Hyperscale achieves high performance from each compute node having SSD-based caches which helps minimize the network round trips to fetch data. There is a lot of awesome technology involved with Hyperscale in how it is architected to use SSD-based caches and page servers. Azure SQL Managed Instance Performance Considerations.
This approach was touted to be better for fine-grained caching because each subresource could be cached individually and the full bundle didn’t need to be redownloaded if one of them changed. Finally, not inlining resources has an added latency cost because the file needs to be requested. What Does It All Mean? Large preview ).
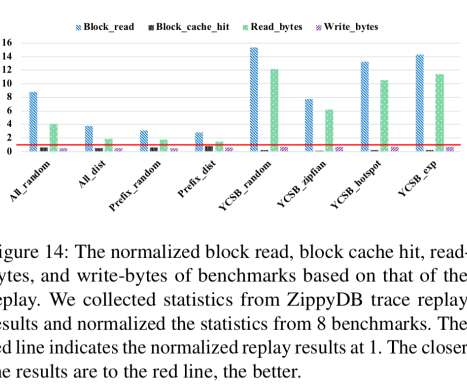
All cache read misses and all writes go through UDB servers, with SQL queries being converted into RocksDB queries. For UDB, many read requests for popular data will be handled by the upper cache tiers and so never hit RocksDB. YCSB lets you tune the query type ratio, KV-pair hotness distribution, and value size distribution.
â€A CDN, or Content Delivery Network, is a network of servers strategically positioned across various locations to expedite content delivery to users based on their geographic location.These patterns split into two main forms of traffic:Static Traffic: When a user request targets static content, the CDN first checks its cache.
A co-worker introduced me to Craig Hanson and Pat Crain's performance mantras, which neatly summarize much of what we do in performance analysis and tuning. In some cases, a benchmark may appear to exceed network bandwidth because it returns from a local memory cache instead of the remote target. They are: **Performance mantras**.
The main objective of this post is to share my experience over the past years tuning MongoDB and centralize the diverse sources that I crossed in this journey in a unique place. The CFQ works well for many general use cases but lacks latency guarantees. Spoiler alert: This post focuses on MongoDB 3.6.X tcp_fin_timeout = 30 net.ipv4.tcp_keepalive_intvl
The next closest active POP location to Bucharest was Istanbul which was still almost 900km away; this distance adds up in terms of latency. Alternatively, If you would like to request a POP in a certain location or a new feature please let us know on our feature requests community page and stay tuned for more exciting announcements.
Although both countries are relatively close to one another, they are separated by a distance of approximately 500km, which adds up in terms of latency. Before the implementation of our Helsinki POP, Finnish users were delivered content from our POP in Stockholm, Sweden. Happy content delivery!
For most high-end processors these values have remained in the range of 75% to 85% of the peak DRAM bandwidth of the system over the past 15-20 years — an amazing accomplishment given the increase in core count (with its associated cache coherence issues), number of DRAM channels, and ever-increasing pipelining of the DRAMs themselves.
A CDN, or Content Delivery Network, is a network of servers strategically positioned across various locations to expedite content delivery to users based on their geographic location.These patterns split into two main forms of traffic:Static Traffic: When a user request targets static content, the CDN first checks its cache.
You’ve probably heard things like: “HTTP/3 is much faster than HTTP/2 when there is packet loss”, or “HTTP/3 connections have less latency and take less time to set up”, and probably “HTTP/3 can send data more quickly and can send more resources in parallel”. Stay tuned! (vf, vf, il, al).
Stable media is commonly physical disk storage, but other devices and certain caching facilities qualify as well. Many high-end disk subsystems provide high-speed cache facilities to reduce the latency of read and write operations. This cache is often supported by a battery-powered backup facility.
Additionally for the log disk component it is latency for an individual write that is crucial rather than the total I/O bandwidth. To illustrate the data reads on Oracle we can flush the buffer cache. Consequently we now need to increase the buffer cache in size if we are to see more CPU activity. so what are your options?
Because we are dealing with network protocols here, we will mainly look at network aspects, of which two are most important: latency and bandwidth. Latency can be roughly defined as the time it takes to send a packet from point A (say, the client) to point B (the server). Two-way latency is often called round-trip time (RTT).
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content