This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
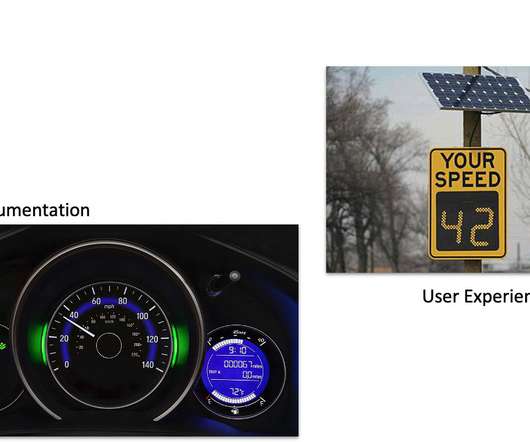
Teams often consider external caches when the existing database cannot meet the required service-level agreement (SLA). However, external caches are not as simple as they are often made out to be. This is a clear performance-oriented decision.
Migrating Critical Traffic At Scale with No Downtime — Part 1 Shyam Gala , Javier Fernandez-Ivern , Anup Rokkam Pratap , Devang Shah Hundreds of millions of customers tune into Netflix every day, expecting an uninterrupted and immersive streaming experience. This approach has a handful of benefits.
How To Design For High-Traffic Events And Prevent Your Website From Crashing How To Design For High-Traffic Events And Prevent Your Website From Crashing Saad Khan 2025-01-07T14:00:00+00:00 2025-01-07T22:04:48+00:00 This article is sponsored by Cloudways Product launches and sales typically attract large volumes of traffic.
This gives fascinating insights into the network topography of our visitors, and how much we might be impacted by high latency regions. Round-trip-time (RTT) is basically a measure of latency—how long did it take to get from one endpoint to another and back again? What is RTT? RTT isn’t a you-thing, it’s a them-thing.
We introduce a caching mechanism in the API gateway layer, allowing us to offload processing from singleton leader elected controllers without giving up strict data consistency and guarantees clients observe. With traffic growth, a single leader node handling all request volume started becoming overloaded.
Caching is the process of storing frequently accessed data or resources in a temporary storage location, such as memory or disk, to improve retrieval speed and reduce the need for repetitive processing. Bandwidth optimization: Caching reduces the amount of data transferred over the network, minimizing bandwidth usage and improving efficiency.
The GraphQL shim enabled client engineers to move quickly onto GraphQL, figure out client-side concerns like cache normalization, experiment with different GraphQL clients, and investigate client performance without being blocked by server-side migrations. The Replay Tester tool samples raw traffic streams from Mantis.
Because microprocessors are so fast, computer architecture design has evolved towards adding various levels of caching between compute units and the main memory, in order to hide the latency of bringing the bits to the brains. This avoids thrashing caches too much for B and evens out the pressure on the L3 caches of the machine.
These include challenges with tail latency and idempotency, managing “wide” partitions with many rows, handling single large “fat” columns, and slow response pagination. It also serves as central configuration of access patterns such as consistency or latency targets. Useful for keeping “n-newest” or prefix path deletion.
This allows the app to query a list of “paths” in each HTTP request, and get specially formatted JSON (jsonGraph) that we use to cache the data and hydrate the UI. Looking at our high traffic UI screens (like the homepage) allowed us to identify any regressions caused by the endpoint before we enabled it for all our users.
Rajiv Shringi Vinay Chella Kaidan Fullerton Oleksii Tkachuk Joey Lynch Introduction As Netflix continues to expand and diversify into various sectors like Video on Demand and Gaming , the ability to ingest and store vast amounts of temporal data — often reaching petabytes — with millisecond access latency has become increasingly vital.
When 54 percent of the internet traffic share is accounted for by Mobile , it's certainly nontrivial to acknowledge how your app can make a difference to that of the competitor!
Each of these models is suitable for production deployments and high traffic applications, and are available for all of our supported databases, including MySQL , PostgreSQL , Redis™ and MongoDB® database ( Greenplum® database coming soon). This becomes really important for cache solutions like Redis™. SSH Access to Machine.
Deployment: Cache To produce business value, all our Metaflow projects are deployed to work with other production systems. In other cases, it is more convenient to share the results via a low-latency API. The back-end auto-scales the number of instances used to back your service based on traffic.
Key Takeaways Critical performance indicators such as latency, CPU usage, memory utilization, hit rate, and number of connected clients/slaves/evictions must be monitored to maintain Redis’s high throughput and low latency capabilities. It can achieve impressive performance, handling up to 50 million operations per second.
When deciding what to pick, there are many things to consider, like where the proxy needs to be, if it “just” needs to redirect the connections, or if more features need to be in, like caching and filtering, or if it needs to be integrated with some MySQL embedded automation. Given that, there never was a single straight answer.
LinkedIn introduced Couchbase as a centralized caching tier for scaling member profile reads to handle increasing traffic that has outgrown their existing database cluster. The new solution achieved over 99% hit rate, helped reduce tail latencies by more than 60% and costs by 10% annually. By Rafal Gancarz
The POP is strategially located within the country and lowers latency overall. KeyCDN is always on the lookout for ways to minimize latency and accelerate asset delivery worldwide. Traffic from this POP will be billed towards Latin America according to our pricing. Hola Mexico!
As developers, we rightfully obsess about the customer experience, relentlessly working to squeeze every millisecond out of the critical rendering path, optimize input latency, and eliminate jank. On top of this foundation, we add layers of caching, prerendering and edge delivery optimizations — not the other way around.
Key Takeaways Redis offers complex data structures and additional features for versatile data handling, while Memcached excels in simplicity with a fast, multi-threaded architecture for basic caching needs. Redis is better suited for complex data models, and Memcached is better suited for high-throughput, string-based caching scenarios.
s web-based applications often encounter database scaling challenges when faced with growth in users, traffic, and data. Behind the scenes, Amazon DynamoDB automatically spreads the data and traffic for a table over a sufficient number of servers to meet the request capacity specified by the customer. Consistency. SimpleDBâ??s
Use cases such as gaming, ad tech, and IoT lend themselves particularly well to the key-value data model where the access patterns require low-latency Gets/Puts for known key values. The purpose of DynamoDB is to provide consistent single-digit millisecond latency for any scale of workloads.
This includes metrics such as query execution time, the number of queries executed per second, and the utilization of query cache and adaptive hash index. query cache: Disable (query_cache_size: 0, query_cache_type:OFF) innodb_adaptive_hash_index: Check adaptive hash index usage to determine its efficiency.
Nonetheless, we found a number of limitations that could not satisfy our requirements e.g. stalling the processing of log events until a dump is complete, missing ability to trigger dumps on demand, or implementations that block write traffic by using table locks. Blocking write traffic by locking tables. Writing events to any output.
We are standing on the eve of the 5G era… 5G, as a monumental shift in cellular communication technology, holds tremendous potential for spurring innovations across many vertical industries, with its promised multi-Gbps speed, sub-10 ms low latency, and massive connectivity. Throughput and latency. energy consumption).
The image below shows a significant drop in latency once we've launched the new point of presence in Israel. In fact, latency has been reduced by almost 50%! With a total of 5 POPs in Oceania, this continent benefits from lower latency with every POP added. So far, traffic from Nigeria has been routed to Europe.
ISPs do cache DNS however which means if your first provider goes down it will still try to query the first DNS server for a period of time before querying for the second one. Using a fast DNS hosting provider ensures there is less latency between the DNS lookup and TTFB. So DNS services definitely go down!
Nonetheless, we found a number of limitations that could not satisfy our requirements e.g. stalling the processing of log events until a dump is complete, missing ability to trigger dumps on demand, or implementations that block write traffic by using table locks. Blocking write traffic by locking tables. Writing events to any output.
This enables customers to serve content to their end users with low latency, giving them the best application experience. In 2008, AWS opened a point of presence (PoP) in Hong Kong to enable customers to serve content to their end users with low latency. Since then, AWS has added two more PoPs in Hong Kong, the latest in 2016.
Cross Region Read Replicas also enable you to serve read traffic for your global customer base from regions that are nearest to them. Cross Region Read Replicas also make it even easier for our global customers to scale database deployments to meet the performance demands of high-traffic, globally disperse applications.
Taiji: managing global user traffic for large-scale internet services at the edge Xu et al., It’s another networking paper to close out the week (and our coverage of SOSP’19), but whereas Snap looked at traffic routing within the datacenter, Taiji is concerned with routing traffic from the edge to a datacenter. SOSP’19.
It increases our visibility and enables us to draw a steady stream of organic (or “free”) traffic to our site. While paid marketing strategies like Google Ads play a part in our approach as well, enhancing our organic traffic remains a major priority. The higher our organic traffic, the more profitable we become as a company.
There is no way to model how much more traffic you can send to that system before it exceeds it’s SLA. Every opportunity for delay due to more work than the best case or more time waiting than the best case increases the latency and they all add up and create a long tail. Mu is the mean of each component, the latency.
Redis's microsecond latency has made it a de facto choice for caching. Four years ago, as part of our AWS fast data journey, we introduced Amazon ElastiCache for Redis , a fully managed, in-memory data store that operates at microsecond latency. TB of in-memory capacity in a single cluster.
VPC Endpoints give you the ability to control whether network traffic between your application and DynamoDB traverses the public Internet or stays within your virtual private cloud. Performant – DynamoDB consistently delivers single-digit millisecond latencies even as your traffic volume increases.
One example could be using an RDBMS for most of the Online transaction processing ( OLTP) data shared by country and having the products as distributed memory cache with a different technology. It will also allow us to redirect read/write traffic to the primary and read-only traffic to all secondaries.
CDNs cache content on edge servers distributed globally, reducing the distance between users and the content they want.â€CDNs CDNs use load-balancing techniques to distribute incoming traffic across multiple servers called Points of Presence (PoPs) which distribute content closer to end-users and improve overall performance.Â
CDNs cache content on edge servers distributed globally, reducing the distance between users and the content they want.CDNs use load-balancing techniques to distribute incoming traffic across multiple servers called Points of Presence (PoPs) which distribute content closer to end-users and improve overall performance.
They cache static content and enable lightning-fast delivery around the globe.This symbiosis reduces server load, boosts loading times, and ensures efficient content distribution. Content Delivery Networks (CDNs), web browsers, and proxy servers can store static files in their caches. For example, consider tools like ChatGPT.
Caching the base page/HTML is common, and it should have a positive impact on backend times. Key things to understand from your CDN Cache Hit/Cache Miss – Was the resource served from the edge, or did the request have to go to origin? Latency – How much time does it take to deliver a packet from A to B.
KeyCDN is always looking for ways to minimize latency and accelerate the delivery of assets worldwide. According to our pricing , traffic from this POP will be billed to Latin America. So far, we could cover Latin America through Mexico City, Santiago, and São Paulo. Now Buenos Aires and Bogotá have been added.
If price is your top priority, you'll need to decide how much you're willing to sacrifice in terms of reliability and performance.What are your traffic patterns like? If your traffic is mostly static, you may be able to meet all your needs with a less expensive CDN that provides content distribution services.
This approach was touted to be better for fine-grained caching because each subresource could be cached individually and the full bundle didn’t need to be redownloaded if one of them changed. Finally, not inlining resources has an added latency cost because the file needs to be requested. Support is unclear at this time.
Cache-Headers missing? Estimated Input Latency. Estimated Input Latency. Service workers that will cache the bytecode result of a parsed and compiled script. After that, it’ll be mitigated by cache. What changed in PageSpeed 5.0? PageSpeed ran a series of heuristics against a given page. Speed Index. Speed Index.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content