This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Caching them at the other end: How long should we cache files on a user’s device? In one test, I concatenated it all into one big file, and the other had the library split into 12 files. Read the complete test methodology. 4,362ms of cumulative latency; 240ms of cumulative download. That’s almost 22× more!
By: Rajiv Shringi , Oleksii Tkachuk , Kartik Sathyanarayanan Introduction In our previous blog post, we introduced Netflix’s TimeSeries Abstraction , a distributed service designed to store and query large volumes of temporal event data with low millisecond latencies. Today, we’re excited to present the Distributed Counter Abstraction.
We introduce a caching mechanism in the API gateway layer, allowing us to offload processing from singleton leader elected controllers without giving up strict data consistency and guarantees clients observe. We started seeing increased response latencies and leader servers running at dangerously high utilization.
This article is to simply report the YCSB bench test results in detail for five NoSQL databases namely Redis, MongoDB, Couchbase, Yugabyte and BangDB and compare the result side by side. I have also used the default six test scenarios as defined by the YCSB framework. I have restricted it to 10M records for each test.
The three strategies we will discuss today are AB Testing , Replay Testing, and Sticky Canaries. To launch Phase 1 safely, we used AB Testing. To launch Phase 2 safely, we used Replay Testing and Sticky Canaries. We knew we could test the same query with the same inputs and consistently expect the same results.
Users might already have the file cached. If website-a.com links to [link] , and a user goes from there to website-b.com who also links to [link] , then the user will already have that file in their cache. On a slower, higher-latency connection, the story is much, mush worse. Penalty: Caching. All completely avoidable.
This blog post will provide a detailed analysis of replay traffic testing, a versatile technique we have applied in the preliminary validation phase for multiple migration initiatives. In this testing strategy, we execute a copy (replay) of production traffic against a system’s existing and new versions to perform relevant validations.
Because microprocessors are so fast, computer architecture design has evolved towards adding various levels of caching between compute units and the main memory, in order to hide the latency of bringing the bits to the brains. This avoids thrashing caches too much for B and evens out the pressure on the L3 caches of the machine.
In this article, well discuss six ways to design websites for high-traffic events like product drops and sales: Compress and optimize images , Choose a scalable web host , Use a CDN , Leverage caching , Stress test websites , Refine the backend. You can also find optimization plugins or caching solutions that give you access to a CDN.
These include challenges with tail latency and idempotency, managing “wide” partitions with many rows, handling single large “fat” columns, and slow response pagination. It also serves as central configuration of access patterns such as consistency or latency targets. Useful for keeping “n-newest” or prefix path deletion.
What Network Latency Means For Time To First Byte Lets add up all the network round trips in the example above: 2 server connections: 6 round trips. Thats where network latency comes in, or network round trip time (RTT) if we look at the time it takes to send data to a server and receive a response in the browser.
This allows the app to query a list of “paths” in each HTTP request, and get specially formatted JSON (jsonGraph) that we use to cache the data and hydrate the UI. For the migration, testing was a first-class citizen. Replay Testing Enter replay testing.
The new Amazon capability enables customers to improve the startup latency of their functions from several seconds to as low as sub-second (up to 10 times faster) at P99 (the 99th latency percentile). This can cause latency outliers and may lead to a poor end-user experience for latency-sensitive applications.
The RAG process begins by summarizing and converting user prompts into queries that are sent to a search platform that uses semantic similarities to find relevant data in vector databases, semantic caches, or other online data sources. To observe model drift and accuracy, companies can use holdout evaluation sets for comparison to model data.
The Site Reliability Guardian helps automate release validation based on SLOs and important signals that define the expected behavior of your applications in terms of availability, performance errors, throughput, latency, etc. If so, test against the response time objective under the same Site Reliability Guardian.
Disk Caching? — ? MezzFS can be configured to cache objects on the local disk. Regional caching? —?Netflix If an application in region A is using MezzFS to read from an object stored in region B, MezzFS will cache the object in region A. we only pay the transfer costs for one worker, and the rest use the cached object.
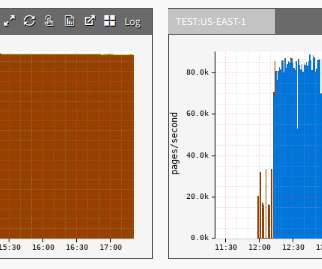
I was doing some cursory research and running a few tests against a potential client’s site so as to get a good understanding of the shape of things before we were to work together. To further exacerbate the problem, the 302 response has a Cache-Control: must-revalidate, private. Can you see it? View full size (31KB).
Key Takeaways Critical performance indicators such as latency, CPU usage, memory utilization, hit rate, and number of connected clients/slaves/evictions must be monitored to maintain Redis’s high throughput and low latency capabilities. It can achieve impressive performance, handling up to 50 million operations per second.
Of course writes were much less common than reads, so I added a caching layer for reads, and that did the trick. So in addition to all the optimization work we did for Google Docs, I got to spend a lot of time and energy working on the measurement problem: how can we get end-to-end latency numbers?
Here’s how the same test performed when running Percona Distribution for PostgreSQL 14 on these same servers: Queries: reads Queries: writes Queries: other Queries: total Transactions Latency (95th) MySQL (A) 1584986 1645000 245322 3475308 122277 20137.61 The throughput didn’t double but increased by 57%.
When deciding what to pick, there are many things to consider, like where the proxy needs to be, if it “just” needs to redirect the connections, or if more features need to be in, like caching and filtering, or if it needs to be integrated with some MySQL embedded automation. micro) The tests We will have very simple test cases.
Some features (as an example) include Device Type ID, SDK Version, Buffer Sizes, Cache Capacities, UI resolution, Chipset Manufacturer and Brand. Restricting Testing and Analysis to one day and device at a time. all OOM kills with the tradeoff of lowering the performance/clearing the cache an extra 1.1%
As developers, we rightfully obsess about the customer experience, relentlessly working to squeeze every millisecond out of the critical rendering path, optimize input latency, and eliminate jank. On top of this foundation, we add layers of caching, prerendering and edge delivery optimizations — not the other way around.
We are standing on the eve of the 5G era… 5G, as a monumental shift in cellular communication technology, holds tremendous potential for spurring innovations across many vertical industries, with its promised multi-Gbps speed, sub-10 ms low latency, and massive connectivity. Throughput and latency. energy consumption).
Last week we looked at a function shipping solution to the problem; Cloudburst uses the more common data shipping to bring data to caches next to function runtimes (though you could also make a case that the scheduling algorithm placing function execution in locations where the data is cached a flavour of function-shipping too).
In-Memory Storage Engine, as the name suggests, stores data in memory for faster performance and lower latencies. It uses a filesystem cache and write-ahead log for crash recovery. MongoDB makes use of both the filesystem cache and the WiredTiger internal cache. Compaction operation defragments data files & indexes.
Deploying your application and database on the same VPC also provides the lowest possible latency path. This becomes really important for cache solutions like Redis™. At ScaleGrid we recommend you deploy your clusters on private VPC subnets so that your database is not routable from the internet. Expert Tip. Security Groups.
ISPs do cache DNS however which means if your first provider goes down it will still try to query the first DNS server for a period of time before querying for the second one. Using a fast DNS hosting provider ensures there is less latency between the DNS lookup and TTFB. So DNS services definitely go down!
The POP is strategially located within the country and lowers latency overall. KeyCDN is always on the lookout for ways to minimize latency and accelerate asset delivery worldwide. Hola Mexico! We've launched our new point of presence (POP) in Mexico City.
Today, I'm excited to announce the general availability of Amazon DynamoDB Accelerator (DAX) , a fully managed, highly available, in-memory cache that can speed up DynamoDB response times from milliseconds to microseconds, even at millions of requests per second. Adding caching when your app is already experiencing load is not easy.
This includes metrics such as query execution time, the number of queries executed per second, and the utilization of query cache and adaptive hash index. query cache: Disable (query_cache_size: 0, query_cache_type:OFF) innodb_adaptive_hash_index: Check adaptive hash index usage to determine its efficiency.
The Xeon Phi x200 (Knights Landing) has a lot of modes of operation (selected at boot time), and the latency and bandwidth characteristics are slightly different for each mode. In “Cache” mode, MCDRAM memory is used as an L3 cache for the main DDR4 memory. numactl).
For most high-end processors these values have remained in the range of 75% to 85% of the peak DRAM bandwidth of the system over the past 15-20 years — an amazing accomplishment given the increase in core count (with its associated cache coherence issues), number of DRAM channels, and ever-increasing pipelining of the DRAMs themselves.
Examples of this might be, expecting that the HTML is fully static, such that we can cache it downstream in some deterministic manner — “partially dynamic” HTML bodies are much more likely to be handled incorrectly by caching logic. Here are a few that come to mind: Is this request served from the service worker cache?
Prediction serving latency matters. Test the business impact of your models using randomised controlled trials (follows from #2). Lesson 4: prediction serving latency matters. In a experiment introducing synthetic latency, Booking.com found that an increase of about 30% in latency cost about 0.5%
Likewise, object access paths must be heavily multi-threaded and avoid lock contention to minimize access latency and maximize throughput. Testing Scale-Up Performance. So our comments will be confined to what testing we felt was valuable and how well SOSS performed. That’s actually quite fast. (We Please retry later.
It’s limited by the laws of physics in terms of end-to-end latency. We saw earlier that there is end-user pressure to replace batch systems with much lower latency online systems. We are observing significant demand from users in terms of avoiding batch telemetry pipelines altogether. Emphasis mine ). Emphasis mine ).
By caching hot datasets, indexes, and ongoing changes, InnoDB can provide faster response times and utilize disk IO in a much more optimal way. The optimal value can be decided after testing multiple settings, starting from eight is a good choice. CPU From a CPU standpoint, faster processors with many cores provide better throughput.
As it is infeasible to test every OLAP system runnable on AWS, we chose widely-used systems that represented a variety of architectures and cost models. InS does now offer an NVMe variant too, and the authors perform limited testing on that as well. Query performance is measured from both warm and cold caches. Key findings.
Reads usually have apps waiting on them; writes may not (write-back caching). biolatency From [bcc], this eBPF tool shows a latency histogram of disk I/O. total used free shared buff/cache available Mem: 64414 15421 349 5 48643 48409 Swap: 0 0 0. This is a 64-Gbyte memory system, and 48 Gbytes is in the page cache.
These devices feature: Eight slow, big.LITTLE ARM cores (A75+A55, or A73+A53) built on last-generation processes with very little cache. These are depressingly similar specs to devices I recommended for testing in 2017. 4GiB of RAM. Qualcomm has some 'splainin to do. But this also gives rise to the critique: OK, but does it work?
With sufficient automated testing, you can have a high level of confidence that an isolated change can be built and integrated without breaking anything else. If any of the automated tests fail, then the build is broken and the change cannot be integrated. So where in a CI/CD pipeline do we put performance testing?
It may even be something you do regularly with Lighthouse in Chrome DevTools, where testing is freely available and produces a very attractive-looking report. The linked-up explainer provides more details, from how scores are weighted to why scores may fluctuate between test runs. Can’t be perfect every time!
Cache-Headers missing? During performance tests, Lighthouse records many metrics focused on what a user sees and experiences. Estimated Input Latency. Estimated Input Latency. Service workers that will cache the bytecode result of a parsed and compiled script. After that, it’ll be mitigated by cache.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content