This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
By: Rajiv Shringi , Oleksii Tkachuk , Kartik Sathyanarayanan Introduction In our previous blog post, we introduced Netflix’s TimeSeries Abstraction , a distributed service designed to store and query large volumes of temporal event data with low millisecond latencies. Today, we’re excited to present the Distributed Counter Abstraction.
This gives fascinating insights into the network topography of our visitors, and how much we might be impacted by high latency regions. Round-trip-time (RTT) is basically a measure of latency—how long did it take to get from one endpoint to another and back again? What is RTT? RTT isn’t a you-thing, it’s a them-thing.
We introduce a caching mechanism in the API gateway layer, allowing us to offload processing from singleton leader elected controllers without giving up strict data consistency and guarantees clients observe. We started seeing increased response latencies and leader servers running at dangerously high utilization.
“Latency” is the duration from the execution of a load instruction (to an address that misses in all the caches), and the completion of that load instruction when the data is returned from memory. . The example below is for a 2005-era processor with 60 ns memory latency and 6.4
Caches are very useful software components that all engineers must know. In this article, we are going to describe what is a cache and explain specific use cases focusing on the frontend and client side. What Is a Cache?
Your team celebrates a success story where a trace identified a pesky latency issue in your application's authentication service. It turns out that the fix we made did improve performance at one point but created a situation in which key information was never cached. But the celebrations are short-lived.
The new Amazon capability enables customers to improve the startup latency of their functions from several seconds to as low as sub-second (up to 10 times faster) at P99 (the 99th latency percentile). This can cause latency outliers and may lead to a poor end-user experience for latency-sensitive applications.
In this article, well discuss six ways to design websites for high-traffic events like product drops and sales: Compress and optimize images , Choose a scalable web host , Use a CDN , Leverage caching , Stress test websites , Refine the backend. You can also find optimization plugins or caching solutions that give you access to a CDN.
When a user requests for feed then there will be two parallel threads involved in fetching the user feeds to optimize for latency. FUN FACT : In this talk , Dikang Gu, a software engineer at Instagram core infra team has mentioned about how they use Cassandra to serve critical usecases, high scalability requirements, and some pain points.
Utilizing cloned real traffic, we can exercise the diversity of inputs from a wide range of devices and device application software versions in production. It provides a good read on the availability and latency ranges under different production conditions. Logging is selective to cases where the old and new responses do not match.
In this blog post, we’ll demonstrate how Dynatrace automation and the Dynatrace Site Reliability Guardian can help you implement your applications according to all six AWS Well-Architected pillars by integrating them into your software development lifecycle (SDLC).
The Tech Hollow , an OSS technology we released a few years ago, has been best described as a total high-density near cache : Total : The entire dataset is cached on each node?—?there there is no eviction policy, and there are no cache misses. Near : the cache exists in RAM on any instance which requires access to the dataset.
Key Takeaways Critical performance indicators such as latency, CPU usage, memory utilization, hit rate, and number of connected clients/slaves/evictions must be monitored to maintain Redis’s high throughput and low latency capabilities. It can achieve impressive performance, handling up to 50 million operations per second.
Deployment: Cache To produce business value, all our Metaflow projects are deployed to work with other production systems. In other cases, it is more convenient to share the results via a low-latency API. A Streamlit app houses the visualization software and data aggregation logic.
For example, when monitoring a database, you’ll want to know about any latency when writing data to a disk or average query response time. Examples include a spike in memory utilization, a decrease in cache hit ratio, or an increase in CPU utilization. Luckily, there are tools and practices that address these challenges.
Identifying key Redis metrics such as latency, CPU usage, and memory metrics is crucial for effective Redis monitoring. To monitor Redis instances effectively, collect Redis metrics focusing on cache hit ratio, memory allocated, and latency threshold.
Data lakehouses deliver the query response with minimal latency. By applying massively parallel processing and high-performance caches, all this contextualized data can be interrogated at high speeds for ad-hoc analytics or AI-powered precise answers. Massively parallel processing. The Dynatrace difference, now powered by Grail.
Identifying key Redis® metrics such as latency, CPU usage, and memory metrics is crucial for effective Redis monitoring. To monitor Redis® instances effectively, collect Redis metrics focusing on cache hit ratio, memory allocated, and latency threshold.
Best of all, our page can load much faster since everything is cached in Elasticsearch. Listening to Kafka events adds little latency, our fan out operations are really quick since we store foreign keys to identify the edges, and looking up data in an inverted index is fast as well. Our data changes constantly?—?
Amazon DynamoDB offers low, predictable latencies at any scale. This is not just predictability of median performance and latency, but also at the end of the distribution (the 99.9th percentile), so we could provide acceptable performance for virtually every customer. s read latency, particularly as dataset sizes grow.
for us at Netflix, this is a combination of the device type, app session ID and software development kit version (SDK version). Some features (as an example) include Device Type ID, SDK Version, Buffer Sizes, Cache Capacities, UI resolution, Chipset Manufacturer and Brand. This is because since the kill happens rarely (0.9%
Today, I'm excited to announce the general availability of Amazon DynamoDB Accelerator (DAX) , a fully managed, highly available, in-memory cache that can speed up DynamoDB response times from milliseconds to microseconds, even at millions of requests per second. Adding caching when your app is already experiencing load is not easy.
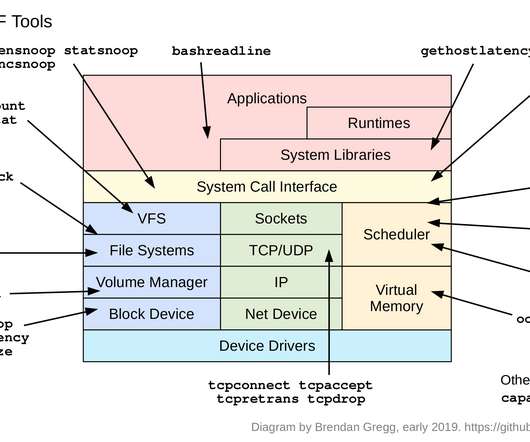
biolatency Disk I/O latency histogram heat map. cachestat File system cache statistics line charts. runqlat CPU scheduler latency heat map. This is thinking like a sysadmin who installs and maintains software, and not like a programmer who codes everything. execsnoop New processes (via exec(2)) table. That's the fast way.
“Latency” is the duration from the execution of a load instruction (to an address that misses in all the caches), and the completion of that load instruction when the data is returned from memory. . The example below is for a 2005-era processor with 60 ns memory latency and 6.4
There are two main types of DNS servers: authoritative servers and caching resolvers. But the real robustness of the DNS system comes through the way lookups are handled, which is what caching resolvers do. Caching techniques ensure that the DNS system doesnt get overloaded with queries.
Streams provide you with the underlying infrastructure to create new applications, such as continuously updated free-text search indexes, caches, or other creative extensions requiring up-to-date table changes. DynamoDB Streams enables your application to get real-time notifications of your tables’ item-level changes.
The most obvious and common way this happens is when companies try to evolve their caches into a data platform that can, for example, be used as highly available enterprise key-value stores for volatile data. Software always evolves, but not always in a good way. Why can’t you just use an abstract cache that loads data lazily?
Three years ago, as part of our AWS Fast Data journey we introduced Amazon ElastiCache for Redis , a fully managed in-memory data store that operates at sub-millisecond latency. While caching continues to be a dominant use of ElastiCache for Redis, we see customers increasingly use it as an in-memory NoSQL database.
Tue-Thu Apr 25-27: High-Performance and Low-Latency C++ (Stockholm). On April 25-27, I’ll be in Stockholm (Kista) giving a three-day seminar on “High-Performance and Low-Latency C++.” If you’re interested in attending, please check out the links, and I look forward to meeting and re-meeting many of you there.
All of the web performance monitoring software we work with provide RUM clients that put additional layers of monkey patching on the page to maintain direct access to a request being made or the response coming back. Here are a few that come to mind: Is this request served from the service worker cache?
We have spent a great deal of time at ScaleOut Software re-architecting our in-memory data grid (IMDG)’s code base to make best use of many cores and large memory. Likewise, object access paths must be heavily multi-threaded and avoid lock contention to minimize access latency and maximize throughput. Testing Scale-Up Performance.
My personal opinion is that I don't see a widespread need for more capacity given horizontal scaling and servers that can already exceed 1 Tbyte of DRAM; bandwidth is also helpful, but I'd be concerned about the increased latency for adding a hop to more memory. Ford, et al., “TCP
We push as much data processing as possible onto warehouse-scale computers and systems software. It’s limited by the laws of physics in terms of end-to-end latency. We saw earlier that there is end-user pressure to replace batch systems with much lower latency online systems. Emphasis mine ). Emphasis mine ).
This includes metrics such as query execution time, the number of queries executed per second, and the utilization of query cache and adaptive hash index. query cache: Disable (query_cache_size: 0, query_cache_type:OFF) innodb_adaptive_hash_index: Check adaptive hash index usage to determine its efficiency.
Redirects are often pretty light in terms of the latency that they add to a website, but they are an easy first thing to check, and they can generally be removed with little effort. I’m going to update my referenced URL to the new site to help decrease latency that adds drag to the initial page load. Text-based assets.
The mean and percentile measurements hide this structure, but the rest of this post will show how the structure can be measured and analyzed so that you can figure out a useful model of your system, understand what is driving the long tail of latencies and come up with better SLAs and measures of capacity.
Caching of query results on the other hand, looks like a good business model, at large enough scale these might amount to pretty much the same thing). How’s that going to work given what we know about the throughput and latency of blockchains, and the associated mining costs?" An embodiment for structured data for IoT.
The benefits of modeling data as events as a mechanism to evolve our software systems. My own journey into microservices began with work I was doing to help organizations ship software more quickly. All too often, the software wasn’t designed in a way that made it easy to ship. And data was at the heart of the problem.
MongoDB Community Edition software might set the stage for achieving your high-volume database goals, but you quickly learn that its features fall short of your enterprise needs. So you look at MongoDB Enterprise software, but its costly and complex licensing structure does not meet your budget goals.
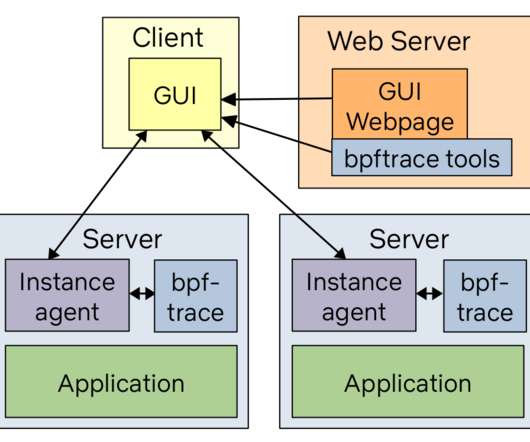
bpftrace is a new open source tracer for Linux for analyzing production performance problems and troubleshooting software. For example, iostat(1), or a monitoring agent, may tell you your average disk latency, but not the distribution of this latency. software Kernel software-based events.
For query executors that can be frequently started and stopped the authors explore performance with cold and warm caches (where applicable), and also the horizontal and vertical scaling performance. For cost calculations, the costs are a combination of compute costs, storage costs, data scan costs, and software license costs.
Performant – DynamoDB consistently delivers single-digit millisecond latencies even as your traffic volume increases. DynamoDB automatically re-distributes your data to healthy servers to ensure there are always multiple replicas of your data without you needing to intervene.
Existing systems can be studied with measurement, while prospective systems are most often studied by extrapolating from measurements of prior systems or via simulation software that mimics target system function and provides performance metrics. Can one both minimize latency and maximize throughput for unscheduled work? Little’s Law.
using Compute Express Link or CXL), organizing memory components for optimal performance, adapting system software traditionally designed for homogeneous memory systems, and developing memory abstractions and programming constructs for HCM management. Figure 2: Latency characteristics of memory technologies (source: Maruf et al.,
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content