This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Caching is the process of storing frequently accessed data or resources in a temporary storage location, such as memory or disk, to improve retrieval speed and reduce the need for repetitive processing. Bandwidth optimization: Caching reduces the amount of data transferred over the network, minimizing bandwidth usage and improving efficiency.
By: Rajiv Shringi , Oleksii Tkachuk , Kartik Sathyanarayanan Introduction In our previous blog post, we introduced Netflix’s TimeSeries Abstraction , a distributed service designed to store and query large volumes of temporal event data with low millisecond latencies. Today, we’re excited to present the Distributed Counter Abstraction.
We introduce a caching mechanism in the API gateway layer, allowing us to offload processing from singleton leader elected controllers without giving up strict data consistency and guarantees clients observe. We started seeing increased response latencies and leader servers running at dangerously high utilization.
Yet, many are confined to a brief temporal window due to constraints in serving latency or training costs. These insights have shaped the design of our foundation model, enabling a transition from maintaining numerous small, specialized models to building a scalable, efficient system.
For example, you can switch to a scalable cloud-based web host, or compress/optimize images to save bandwidth. Choose A Scalable Web Host The most convenient way to design a high-traffic website without worrying about website crashes is to upgrade your web hosting solution. Caching can help your website combat this issue.
Users might already have the file cached. If website-a.com links to [link] , and a user goes from there to website-b.com who also links to [link] , then the user will already have that file in their cache. On a slower, higher-latency connection, the story is much, mush worse. Penalty: Caching. Myth: Cross-Domain Caching.
When a user requests for feed then there will be two parallel threads involved in fetching the user feeds to optimize for latency. FUN FACT : In this talk , Dikang Gu, a software engineer at Instagram core infra team has mentioned about how they use Cassandra to serve critical usecases, high scalability requirements, and some pain points.
The new Amazon capability enables customers to improve the startup latency of their functions from several seconds to as low as sub-second (up to 10 times faster) at P99 (the 99th latency percentile). This can cause latency outliers and may lead to a poor end-user experience for latency-sensitive applications.
We note that for MongoDB update latency is really very low (low is better) compared to other dbs, however the read latency is on the higher side. The latency table shows that 99th percentile latency for Yugabyte is quite high compared to others (lower is better). Again Yugabyte latency is quite high. Conclusion.
Central to this infrastructure is our use of multiple online distributed databases such as Apache Cassandra , a NoSQL database known for its high availability and scalability. It also serves as central configuration of access patterns such as consistency or latency targets.
Werner Vogels weblog on building scalable and robust distributed systems. a Fast and Scalable NoSQL Database Service Designed for Internet Scale Applications. The original Dynamo design was based on a core set of strong distributed systems principles resulting in an ultra-scalable and highly reliable database system.
While we were able to put out the immediate fire by disabling the newly created alerts, this incident raised some critical concerns around the scalability of our alerting system. It became clear to us that we needed to solve the scalability problem with a fundamentally different approach. OK, Results?
Because of its scalability and distributed architecture, thousands of companies trust it to run their cloud and hybrid-based workloads at high availability without compromising performance. With the Dynatrace Data Explorer, you can easily analyze metrics, such as client read/write latency by Cassandra nodes and disk space usage by keyspaces.
Rajiv Shringi Vinay Chella Kaidan Fullerton Oleksii Tkachuk Joey Lynch Introduction As Netflix continues to expand and diversify into various sectors like Video on Demand and Gaming , the ability to ingest and store vast amounts of temporal data — often reaching petabytes — with millisecond access latency has become increasingly vital.
The first phase involves validating functional correctness, scalability, and performance concerns and ensuring the new systems’ resilience before the migration. It provides a good read on the availability and latency ranges under different production conditions.
That means multiple data indirections mean multiple cache misses. Mark LaPedus : MRAM, a next-generation memory type, is being touted as a replacement for embedded flash and cache applications. Cliff Click : The JVM is very good at eliminating the cost of code abstraction, but not the cost of data abstraction. They are very expensive.
Under the hood, Titus is powered by Kubernetes , but it provides a thick layer of enhancements over off-the-shelf Kubernetes, to make it more observable , secure , scalable , and cost-efficient. Deployment: Cache To produce business value, all our Metaflow projects are deployed to work with other production systems.
For example, when monitoring a database, you’ll want to know about any latency when writing data to a disk or average query response time. Examples include a spike in memory utilization, a decrease in cache hit ratio, or an increase in CPU utilization. An automatic and intelligent approach to monitoring and observability.
Scalability is one of the main drivers of the NoSQL movement. Historically, NoSQL paid a lot of attention to tradeoffs between consistency, fault-tolerance and performance to serve geographically distributed systems, low-latency or highly available applications. Read/Write latency. Read/Write scalability. Data Placement.
Three years ago, as part of our AWS Fast Data journey we introduced Amazon ElastiCache for Redis , a fully managed in-memory data store that operates at sub-millisecond latency. While caching continues to be a dominant use of ElastiCache for Redis, we see customers increasingly use it as an in-memory NoSQL database.
As we prepared to launch these features, I was struck not only by the range of services we provide to enable customers to run fully managed, scalable, high performance database workloads, including Amazon RDS , Amazon DynamoDB , Amazon Redshift and Amazon ElastiCache , but also by the pace at which these services are evolving and improving.
As I have talked about before, one of the reasons why we built Amazon DynamoDB was that Amazon was pushing the limits of what was a leading commercial database at the time and we were unable to sustain the availability, scalability, and performance needs that our growing Amazon.com business demanded. The opposite is true.
RevenueCat extensively uses caching to improve the availability and performance of its product API while ensuring consistency. The company shared its techniques to deliver the platform, which can handle over 1.2 billion daily API requests. The team at RevenueCat created an open-source memcache client that provides several advanced features.
In this comparison of Redis vs Memcached, we strip away the complexity, focusing on each in-memory data store’s performance, scalability, and unique features. Redis is better suited for complex data models, and Memcached is better suited for high-throughput, string-based caching scenarios.
Identifying key Redis metrics such as latency, CPU usage, and memory metrics is crucial for effective Redis monitoring. To monitor Redis instances effectively, collect Redis metrics focusing on cache hit ratio, memory allocated, and latency threshold.
Streams provide you with the underlying infrastructure to create new applications, such as continuously updated free-text search indexes, caches, or other creative extensions requiring up-to-date table changes. DynamoDB Streams enables your application to get real-time notifications of your tables’ item-level changes.
When deciding what to pick, there are many things to consider, like where the proxy needs to be, if it “just” needs to redirect the connections, or if more features need to be in, like caching and filtering, or if it needs to be integrated with some MySQL embedded automation. Given that, there never was a single straight answer.
In-Memory Storage Engine, as the name suggests, stores data in memory for faster performance and lower latencies. It uses a filesystem cache and write-ahead log for crash recovery. MongoDB makes use of both the filesystem cache and the WiredTiger internal cache. Compaction operation defragments data files & indexes.
Identifying key Redis® metrics such as latency, CPU usage, and memory metrics is crucial for effective Redis monitoring. To monitor Redis® instances effectively, collect Redis metrics focusing on cache hit ratio, memory allocated, and latency threshold.
Last week we looked at a function shipping solution to the problem; Cloudburst uses the more common data shipping to bring data to caches next to function runtimes (though you could also make a case that the scheduling algorithm placing function execution in locations where the data is cached a flavour of function-shipping too).
Werner Vogels weblog on building scalable and robust distributed systems. Often these namespaces are hierarchical in nature such that it becomes easier to manage them and to decentralize control, which makes the system more scalable. There are two main types of DNS servers: authoritative servers and caching resolvers.
After the launch of the AWS APAC (Hong Kong) Region, there will be 19 Availability Zones in Asia Pacific for customers to build flexible, scalable, secure, and highly available applications. This enables customers to serve content to their end users with low latency, giving them the best application experience.
Today, I'm excited to announce the general availability of Amazon DynamoDB Accelerator (DAX) , a fully managed, highly available, in-memory cache that can speed up DynamoDB response times from milliseconds to microseconds, even at millions of requests per second. Adding caching when your app is already experiencing load is not easy.
Werner Vogels weblog on building scalable and robust distributed systems. With just one click you can enable content to be distributed to the customer with low latency and high-reliability. Query String based Caching: the ability to include query string parameters as part of the objects cache key. All Things Distributed.
Active Memory Caching. When you want to get data that you already had quickly, you need to do caching — caching stores data that a user recently retrieved. Caching partially stores your data and is not used as permanent storage. Caching partially stores your data and is not used as permanent storage.
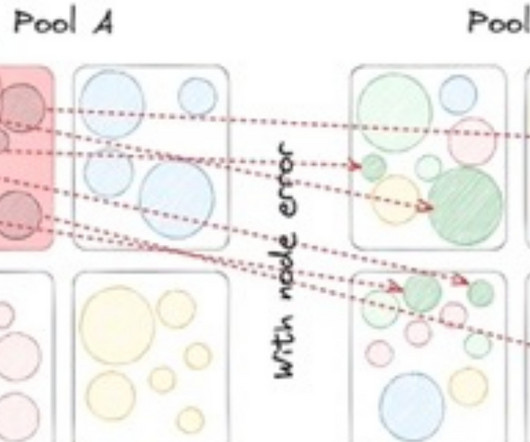
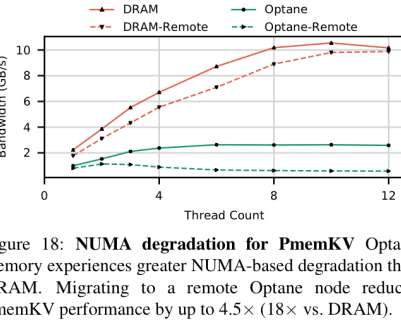
An empirical guide to the behavior and use of scalable persistent memory , Yang et al., higher latency and lower bandwidth)… We have found the actual behavior of Optane DIMMs to be more complicated and nuanced than the "slower, persistent DRAM" label would suggest. The read latency for Optane is 2x-3x higher than DRAM.
Generally to cache data (including non-persistent data that never sees a backing store), to share non-persistent data across application services (e.g. ” Even re-reading that today, the letter of the law there is surprisingly strict to me: you can use the local memory space or filesystem as a brief single transaction cache, but no more.
LinkedIn introduced Couchbase as a centralized caching tier for scaling member profile reads to handle increasing traffic that has outgrown their existing database cluster. The new solution achieved over 99% hit rate, helped reduce tail latencies by more than 60% and costs by 10% annually. By Rafal Gancarz
By caching hot datasets, indexes, and ongoing changes, InnoDB can provide faster response times and utilize disk IO in a much more optimal way. Some cloud providers also offer specialized instances for database workloads, which may provide additional features and optimizations for performance and scalability.
When each of those use cases is powered by a dedicated back-end, investments in better performance, improved scalability and efficiency etc. That’s hard for many reasons, including the differing trade-offs between throughput and latency that need to be made across the use cases. Cache all the things. are divided.
Key Takeaways Distributed storage systems benefit organizations by enhancing data availability, fault tolerance, and system scalability, leading to cost savings from reduced hardware needs, energy consumption, and personnel. Variations within these storage systems are called distributed file systems.
We were pushing the limits of what was a leading commercial database at the time and were unable to sustain the availability, scalability and performance needs that our growing Amazon business demanded. We had an advanced team of database administrators and access to top experts within Oracle. million requests per second.
Redis's microsecond latency has made it a de facto choice for caching. Four years ago, as part of our AWS fast data journey, we introduced Amazon ElastiCache for Redis , a fully managed, in-memory data store that operates at microsecond latency. TB of in-memory capacity in a single cluster.
About 5 years ago, I introduced you to AWS Availability Zones, which are distinct locations within a Region that are engineered to be insulated from failures in other Availability Zones and provide inexpensive, low latency network connectivity to other Availability Zones in the same region.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content