This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Caches are very useful software components that all engineers must know. It is a transversal component that applies to all the tech areas and architecture layers such as operatingsystems, data platforms, backend, frontend, and other components. What Is a Cache?
Because microprocessors are so fast, computer architecture design has evolved towards adding various levels of caching between compute units and the main memory, in order to hide the latency of bringing the bits to the brains. This avoids thrashing caches too much for B and evens out the pressure on the L3 caches of the machine.
In this article, well discuss six ways to design websites for high-traffic events like product drops and sales: Compress and optimize images , Choose a scalable web host , Use a CDN , Leverage caching , Stress test websites , Refine the backend. You can often do this using built-in apps on your operatingsystem.
User demographics , such as app version, operatingsystem, location, and device type, can help tailor an app to better meet users’ needs and preferences. By monitoring metrics such as error rates, response times, and network latency, developers can identify trends and potential issues, so they don’t become critical.
Uploading and downloading data always come with a penalty, namely latency. Figure 3: Video Processing with Index and Virtual Assembly Using virtual assembly greatly improves the latency performance of the ProRes 422 HQ proxy generation by removing one round trip of cloud downloading and cloud uploading by the physical assembler.
Key Takeaways Critical performance indicators such as latency, CPU usage, memory utilization, hit rate, and number of connected clients/slaves/evictions must be monitored to maintain Redis’s high throughput and low latency capabilities. It can achieve impressive performance, handling up to 50 million operations per second.
In-Memory Storage Engine, as the name suggests, stores data in memory for faster performance and lower latencies. It uses a filesystem cache and write-ahead log for crash recovery. Compaction operation defragments data files & indexes. However, keep in ming that it does not release space to the operatingsystem.
Identifying key Redis metrics such as latency, CPU usage, and memory metrics is crucial for effective Redis monitoring. With these essential support systems in place, you can effectively monitor your databases with up-to-date data about their health and functioning status at all times.
The fact that this shows up as CPU time suggests that the reads were all hitting in the systemcache and the CPU time was the kernel overhead (note ntoskrnl.exe on the first sampled call stack) of grabbing data from the cache. Remember that these are calls to the operatingsystem – kernel calls.
Identifying key Redis® metrics such as latency, CPU usage, and memory metrics is crucial for effective Redis monitoring. With these essential support systems in place, you can effectively monitor your databases with up-to-date data about their health and functioning status at all times.
By caching hot datasets, indexes, and ongoing changes, InnoDB can provide faster response times and utilize disk IO in a much more optimal way. Operatingsystem Linux is the most common operatingsystem for high-performance MySQL servers. A recommended value is two times the number of CPUs plus the number of disks.
For most high-end processors these values have remained in the range of 75% to 85% of the peak DRAM bandwidth of the system over the past 15-20 years — an amazing accomplishment given the increase in core count (with its associated cache coherence issues), number of DRAM channels, and ever-increasing pipelining of the DRAMs themselves.
Likewise, object access paths must be heavily multi-threaded and avoid lock contention to minimize access latency and maximize throughput. During load-balancing, the client gets the following exception when accessing the cache: ErrorCode<ERRCA0017>:SubStatus<ES0006>:There is a temporary failure. Please retry later.
The success of our early results with the Dynamo database encouraged us to write Amazon's Dynamo whitepaper and share it at the 2007 ACM Symposium on OperatingSystems Principles (SOSP conference), so that others in the industry could benefit. This was the genesis of the Amazon Dynamo database.
By implementing data replication strategies, distributed storage systems achieve greater. Durability Availability Fault tolerance These combined outcomes help minimize latency experienced by clients spread across different geographical regions.
All of the SPECfp_rate2000 results were downloaded from www.spec.org, the results were sorted by processor type, and “peak floating-point operations per cycle” was manually added for each processor type. This includes all architectures, all compilers, all operatingsystems, and all system configurations.
If throttling is applied at the operatingsystem level , then the metrics match what a real user with those network conditions would experience. INP is a measure of the latency for all interactions on a given page, where the highest latency — or close to it — informs the final score.
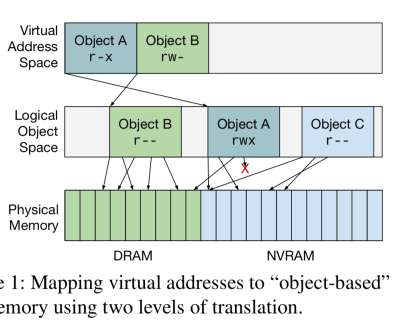
Drawing inspiration from work on single-address-space (SAS) operatingsystems a single system-wide mapping is maintained by the OS which all devices use for accessing memory. It’s the job of the operatingsystem to manage the global and logical object space abstractions. A prototype implementation.
To me this positions Fugaku as the first of a new mainstream, rather than a special purpose system. I have always been particularly interested in the interconnects and protocols used to create clusters, and the latency and bandwidth of the various offerings that are available.
Microarchitectural state of interest includes data and instruction caches, TLBs, branch predictors, instruction- and data-prefetcher state machines, and DRAM row buffers. cache) can be partitioned across domains; for those that are instead time-multiplexed, we have to flush them during domain switches.
Byte-addressable non-volatile memory,) NVM will fundamentally change the way hardware interacts, the way operatingsystems are designed, and the way applications operate on data. This means that the overheads of system calls become much more noticeable. in front of that memory , as we saw last week).
For most high-end processors these values have remained in the range of 75% to 85% of the peak DRAM bandwidth of the system over the past 15-20 years — an amazing accomplishment given the increase in core count (with its associated cache coherence issues), number of DRAM channels, and ever-increasing pipelining of the DRAMs themselves.
All of the SPECfp_rate2000 results were downloaded from www.spec.org, the results were sorted by processor type, and “peak floating-point operations per cycle” was manually added for each processor type. This includes all architectures, all compilers, all operatingsystems, and all system configurations.
In this blog post, we will discuss the best practices on the MongoDB ecosystem applied at the OperatingSystem (OS) and MongoDB levels. OperatingSystem (OS) settings Swappiness Swappiness is a Linux kernel setting that influences the behavior of the Virtual Memory manager when it needs to allocate a swap, ranging from 0-100.
Stable media is commonly physical disk storage, but other devices and certain caching facilities qualify as well. Many high-end disk subsystems provide high-speed cache facilities to reduce the latency of read and write operations. This cache is often supported by a battery-powered backup facility.
The paper examines the implications of microservices at the hardware, OS and networking stack, cluster management, and application framework levels, as well as the impact of tail latency. Smaller microservices demonstrated much better instruction-cache locality than their monolithic counterparts. Hardware implications.
Estimated Input Latency tells us if we are hitting that threshold, and ideally, it should be below 50ms. PRPL stands for Pushing critical resource, Rendering initial route, Pre-caching remaining routes and Lazy-loading remaining routes on demand. An application shell is the minimal HTML, CSS, and JavaScript powering a user interface.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


































Let's personalize your content