This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
By: Rajiv Shringi , Oleksii Tkachuk , Kartik Sathyanarayanan Introduction In our previous blog post, we introduced Netflix’s TimeSeries Abstraction , a distributed service designed to store and query large volumes of temporal event data with low millisecond latencies. Today, we’re excited to present the Distributed Counter Abstraction.
We introduce a caching mechanism in the API gateway layer, allowing us to offload processing from singleton leader elected controllers without giving up strict data consistency and guarantees clients observe. After the jobs are created, it monitors their execution progress. The cache is kept in sync with the current leader process.
This trend is prompting advances in both observability and monitoring. But exactly what are the differences between observability vs. monitoring? Monitoring and observability provide a two-pronged approach. To get a better understanding of observability vs monitoring, we’ll explore the differences between the two.
The GraphQL shim enabled client engineers to move quickly onto GraphQL, figure out client-side concerns like cache normalization, experiment with different GraphQL clients, and investigate client performance without being blocked by server-side migrations. To launch Phase 1 safely, we used AB Testing.
The RAG process begins by summarizing and converting user prompts into queries that are sent to a search platform that uses semantic similarities to find relevant data in vector databases, semantic caches, or other online data sources. Observing AI models Running AI models at scale can be resource-intensive.
The new Amazon capability enables customers to improve the startup latency of their functions from several seconds to as low as sub-second (up to 10 times faster) at P99 (the 99th latency percentile). This can cause latency outliers and may lead to a poor end-user experience for latency-sensitive applications.
Spring Boot 2 uses Micrometer as its default application metrics collector and automatically registers metrics for a wide variety of technologies, like JVM, CPU Usage, Spring MVC, and WebFlux request latencies, cache utilization, data source utilization, Rabbit MQ connection factories, and more. That’s a large amount of data to handle.
As a result, organizations need to monitor mobile app performance metrics that are meaningful and actionable by gaining adequate observability of mobile app performance. Closely monitoring mobile app performance will help ensure customer interactions via mobile apps are meeting the expectations of the customers. Proactive monitoring.
You will need to know which monitoring metrics for Redis to watch and a tool to monitor these critical server metrics to ensure its health. This blog post lists the important database metrics to monitor. Effective monitoring of key performance indicators plays a crucial role in maintaining this optimal speed of operation.
This extension provides fully app-centric Cassandra performance monitoring for Azure Managed Instance for Apache Cassandra. Cassandra is also essential to Dynatrace because it is integral to our monitoring solution. You can also analyze table metrics, such as cache hits and misses.
What Network Latency Means For Time To First Byte Lets add up all the network round trips in the example above: 2 server connections: 6 round trips. Thats where network latency comes in, or network round trip time (RTT) if we look at the time it takes to send data to a server and receive a response in the browser.
In this article, well discuss six ways to design websites for high-traffic events like product drops and sales: Compress and optimize images , Choose a scalable web host , Use a CDN , Leverage caching , Stress test websites , Refine the backend. You can also find optimization plugins or caching solutions that give you access to a CDN.
In todays data-driven world, the ability to effectively monitor and manage data is of paramount importance. With its widespread use in modern application architectures, understanding the ins and outs of Redis monitoring is essential for any tech professional. Redis, a powerful in-memory data store, is no exception.
Moreover, common database optimizations like caching recently queried data don’t really work for alerting queries because, generally speaking, the last received datapoint is required for correctness. The fundamental idea behind Telltale is to detect anomalies on SLI metrics (for example, latency, error rates, etc).
In today’s data-driven world, the ability to effectively monitor and manage data is of paramount importance. With its widespread use in modern application architectures, understanding the ins and outs of Redis® monitoring is essential for any tech professional. Redis®, a powerful in-memory data store, is no exception.
The second phase involves migrating the traffic over to the new systems in a manner that mitigates the risk of incidents while continually monitoring and confirming that we are meeting crucial metrics tracked at multiple levels. It provides a good read on the availability and latency ranges under different production conditions.
The Site Reliability Guardian helps automate release validation based on SLOs and important signals that define the expected behavior of your applications in terms of availability, performance errors, throughput, latency, etc. A study by Amazon found that increasing page load time by just 100 milliseconds costs 1% in sales.
Rajiv Shringi Vinay Chella Kaidan Fullerton Oleksii Tkachuk Joey Lynch Introduction As Netflix continues to expand and diversify into various sectors like Video on Demand and Gaming , the ability to ingest and store vast amounts of temporal data — often reaching petabytes — with millisecond access latency has become increasingly vital.
Rethinking Server-Timing As A Critical Monitoring Tool. Rethinking Server-Timing As A Critical Monitoring Tool. To me, it’s a must-use in any project where real user monitoring (RUM) is being instrumented. To me, it’s a must-use in any project where real user monitoring (RUM) is being instrumented. Sean Roberts.
Deployment: Cache To produce business value, all our Metaflow projects are deployed to work with other production systems. In other cases, it is more convenient to share the results via a low-latency API. Metaflow Hosting caches the response, so Amber can fetch it after a while.
Amazon ElastiCache is a fully managed, in-memory caching service for customers to optimize the latency, performance and cost of their read workloads. It provides customers with familiar MySQL, Microsoft SQL Server or Oracle database engines while simplifying the monitoring and management of complex RDBMSs.
Spring Boot 2 uses Micrometer as its default application metrics collector and automatically registers metrics for a wide variety of technologies, like JVM, CPU Usage, Spring MVC, and WebFlux request latencies, cache utilization, data source utilization, Rabbit MQ connection factories, and more. That’s a large amount of data to handle.
Spring Boot 2 uses Micrometer as its default application metrics collector and automatically registers metrics for a wide variety of technologies, like JVM, CPU Usage, Spring MVC, and WebFlux request latencies, cache utilization, data source utilization, Rabbit MQ connection factories, and more. That’s a large amount of data to handle.
Data lakehouses deliver the query response with minimal latency. By applying massively parallel processing and high-performance caches, all this contextualized data can be interrogated at high speeds for ad-hoc analytics or AI-powered precise answers. Massively parallel processing. Ready to do more with your data? Download report now!
I’ve used a fourth instance to host a PMM server to monitor servers A and B and used the data collected by the PMM agents installed on the database servers to compare performance. In MySQL, considering the standard storage engine, InnoDB , the data cache is called Buffer Pool. In PostgreSQL, it is called shared buffers.
A monitoring tool like Percona Monitoring and Management (PMM) is a popular choice among open source options for effectively monitoring MySQL performance. In this blog, we will explore various MySQL KPIs that are basic and essential to track using monitoring tools like PMM.
Last week we looked at a function shipping solution to the problem; Cloudburst uses the more common data shipping to bring data to caches next to function runtimes (though you could also make a case that the scheduling algorithm placing function execution in locations where the data is cached a flavour of function-shipping too).
All DBaaS management, monitoring, and maintenance tools are included in both plans, along with 24/7 support. Deploying your application and database on the same VPC also provides the lowest possible latency path. This becomes really important for cache solutions like Redis™. Where to host your cloud database?
Use cases such as gaming, ad tech, and IoT lend themselves particularly well to the key-value data model where the access patterns require low-latency Gets/Puts for known key values. The purpose of DynamoDB is to provide consistent single-digit millisecond latency for any scale of workloads.
We are standing on the eve of the 5G era… 5G, as a monumental shift in cellular communication technology, holds tremendous potential for spurring innovations across many vertical industries, with its promised multi-Gbps speed, sub-10 ms low latency, and massive connectivity. Throughput and latency. energy consumption).
Streams provide you with the underlying infrastructure to create new applications, such as continuously updated free-text search indexes, caches, or other creative extensions requiring up-to-date table changes. You can use triggers to monitor for inventory changes and send notifications in real time. DynamoDB Cross-region Replication.
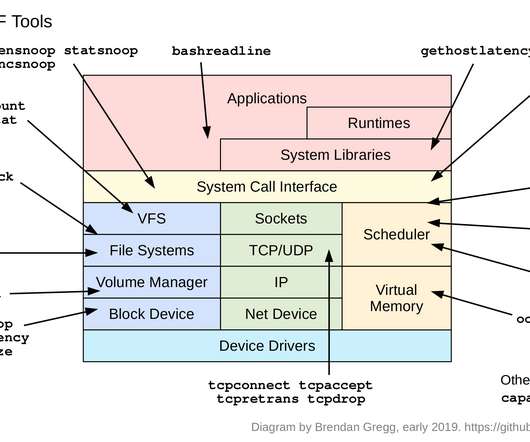
This is also applicable for people adding it to their own in-house monitoring systems. biolatency Disk I/O latency histogram heat map. cachestat File system cache statistics line charts. runqlat CPU scheduler latency heat map. execsnoop New processes (via exec(2)) table. opensnoop Files opened table.
About 5 years ago, I introduced you to AWS Availability Zones, which are distinct locations within a Region that are engineered to be insulated from failures in other Availability Zones and provide inexpensive, low latency network connectivity to other Availability Zones in the same region.
Broadly, these can be categorized as: reporting and dashboarding, embedded statistics in pages, time-series monitoring, and ad-hoc analysis. That’s hard for many reasons, including the differing trade-offs between throughput and latency that need to be made across the use cases. Cache all the things. Procella system overview.
ChatGPT: The InnoDB buffer pool is used by MySQL to cache frequently accessed data in memory. It is also important to monitor your server’s memory usage regularly to ensure that it is not being exhausted by the buffer pool. 16) and monitoring the server’s performance. How large my InnoDB buffer pool needs to be?
Prediction serving latency matters. Lesson 4: prediction serving latency matters. In a experiment introducing synthetic latency, Booking.com found that an increase of about 30% in latency cost about 0.5% Even mathematically simple models have the potential of introducing relevant latency.
Jump to table of contents ↬ Analyzing User Data To effectively monitor and respond to our website’s performance, we need a robust process for collecting and analyzing this data. By transforming our raw data into interactive dashboards and reports , we can easily identify trends, pinpoint issues, and monitor improvements over time.
Integration with AWS CloudWatch, AWS CloudTrail, and AWS Config enables support for monitoring, audit, and configuration management. Performant – DynamoDB consistently delivers single-digit millisecond latencies even as your traffic volume increases.
A cloud-wide monitoring tool, Atlas, showed a high rate of paging for the larger file uploads: The blue is pageins (page ins). Reads usually have apps waiting on them; writes may not (write-back caching). biolatency From [bcc], this eBPF tool shows a latency histogram of disk I/O. Counting cache functions. 17 48011 [.].
And when discussing the two types of data, we’re actually talking about what is called real-user monitoring , or RUM for short. For example, the data is pretty slow to update, refreshing every 28 days, meaning it is not the same as real-time monitoring. But it comes with caveats. Does Lighthouse Use RUM Data, Too?
This article is from my friend Ben who runs Calibre , a tool for monitoring the performance of websites. Cache-Headers missing? Estimated Input Latency. Estimated Input Latency. Service workers that will cache the bytecode result of a parsed and compiled script. After that, it’ll be mitigated by cache.
Reading time 4 min It’s important for both technical and business teams to understand the different web performance monitoring options that are available as well as their various use cases and the benefits of each. Understanding Web Performance Monitoring Methodologies. Synthetic Monitoring. Real User Monitoring (RUM).
It also lacks more advanced monitoring and management features like custom alerting, automation, and deeper insights into database performance that are part of MongoDB Enterprise. Redis can handle a high volume of operations per second, making it useful for running applications that require low latency. Couchbase — No.
For example, iostat(1), or a monitoring agent, may tell you your average disk latency, but not the distribution of this latency. For smaller environments, it can be of more use helping eliminate latency outliers. Block I/O latency as a histogram. This traces block I/O, and shows latency as a power-of-2 histogram.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content