This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Caching them at the other end: How long should we cache files on a user’s device? Plotted on the same horizontal axis of 1.6s, the waterfalls speak for themselves: 201ms of cumulative latency; 109ms of cumulative download. 4,362ms of cumulative latency; 240ms of cumulative download. Cache This is the easy one.
This gives fascinating insights into the network topography of our visitors, and how much we might be impacted by high latency regions. Round-trip-time (RTT) is basically a measure of latency—how long did it take to get from one endpoint to another and back again? RTT data should be seen as an insight and not a metric.
Micrometer is used for instrumenting both out-of-the-box and custom metrics from Spring Boot applications. Davis topology-aware anomaly detection and alerting for your Micrometer metrics. Topology-related custom metrics for seamless reports and alerts. Micrometer uses a registry to export metrics to monitoring systems.
A quick canary test was free of errors and showed lower latency, which is expected given that our standard canary setup routes an equal amount of traffic to both the baseline running on 4xl and the canary on 12xl. What’s worse, average latency degraded by more than 50%, with both CPU and latency patterns becoming more “choppy.”
As a result, organizations need to monitor mobile app performance metrics that are meaningful and actionable by gaining adequate observability of mobile app performance. There are many common mobile app performance metrics that are used to measure key performance indicators (KPIs) related to user experience and satisfaction.
The GraphQL shim enabled client engineers to move quickly onto GraphQL, figure out client-side concerns like cache normalization, experiment with different GraphQL clients, and investigate client performance without being blocked by server-side migrations. So, we relied on higher-level metrics-based testing: AB Testing and Sticky Canaries.
The second phase involves migrating the traffic over to the new systems in a manner that mitigates the risk of incidents while continually monitoring and confirming that we are meeting crucial metrics tracked at multiple levels. It provides a good read on the availability and latency ranges under different production conditions.
Thats why the Time to First Byte (TTFB) metric is important: it measures how soon after navigation the browser starts receiving the HTML response. But actually, theres a lot more to optimizing this metric. What Components Make Up The Time To First Byte Metric? TTFB stands for Time to First Byte. But where does it measure from ?
You will need to know which monitoring metrics for Redis to watch and a tool to monitor these critical server metrics to ensure its health. Redis returns a big list of database metrics when you run the info command on the Redis shell. You can pick a smart selection of relevant metrics from these.
The new Amazon capability enables customers to improve the startup latency of their functions from several seconds to as low as sub-second (up to 10 times faster) at P99 (the 99th latency percentile). This can cause latency outliers and may lead to a poor end-user experience for latency-sensitive applications.
The RAG process begins by summarizing and converting user prompts into queries that are sent to a search platform that uses semantic similarities to find relevant data in vector databases, semantic caches, or other online data sources.
Once you deploy the Dynatrace extension, Dynatrace ingests your Cassandra metrics and analyzes them in context with the entire stack. From there, you can dive deeper into infrastructure metrics (cluster, datacenter, racks, and nodes) and data metrics (keyspaces and tables). Seeing the value.
A few years ago, we were paged by our SRE team due to our Metrics Alerting System falling behind — critical application health alerts reached engineers 45 minutes late! Hence, we started down the path of alert evaluation via real-time streaming metrics. This has proven to be valuable towards reducing Mean Time to Recover (MTTR).
This allows the app to query a list of “paths” in each HTTP request, and get specially formatted JSON (jsonGraph) that we use to cache the data and hydrate the UI. To prepare ourselves for a big change in the tech stack of our endpoint, we decided to track metrics around the time taken to respond to queries.
However, one metric I feel that front-end developers overlook all too quickly is Time to First Byte (TTFB). The first—and often most surprising for people to learn—thing that I want to draw your attention to is that TTFB counts one whole round trip of latency. can all provide valuable insights. But what else is TTFB?
Monitoring focuses on watching specific metrics. Observability is the ability to understand a system’s internal state by analyzing the data it generates, such as logs, metrics, and traces. For example, we can actively watch a single metric for changes that indicate a problem — this is monitoring.
Micrometer is used for instrumenting both out-of-the-box and custom metrics from Spring Boot applications. Davis topology-aware anomaly detection and alerting for your Micrometer metrics. Topology-related custom metrics for seamless reports and alerts. Micrometer uses a registry to export metrics to monitoring systems.
Micrometer is used for instrumenting both out-of-the-box and custom metrics from Spring Boot applications. Davis topology-aware anomaly detection and alerting for your Micrometer metrics. Topology-related custom metrics for seamless reports and alerts. Micrometer uses a registry to export metrics to monitoring systems.
Dynomite is a Netflix open source wrapper around Redis that provides a few additional features like auto-sharding and cross-region replication, and it provided Pushy with low latency and easy record expiry, both of which are critical for Pushy’s workload. As Pushy’s portfolio grew, we experienced some pain points with Dynomite.
The Site Reliability Guardian helps automate release validation based on SLOs and important signals that define the expected behavior of your applications in terms of availability, performance errors, throughput, latency, etc. A study by Amazon found that increasing page load time by just 100 milliseconds costs 1% in sales.
Annie leads the Chrome Speed Metrics team at Google, which has arguably had the most significant impact on web performance of the past decade. It's really important to acknowledge that none of this would have been possible without the great work from Annie and her small-but-mighty Speed Metrics team at Google. Nice job, everyone!
Rajiv Shringi Vinay Chella Kaidan Fullerton Oleksii Tkachuk Joey Lynch Introduction As Netflix continues to expand and diversify into various sectors like Video on Demand and Gaming , the ability to ingest and store vast amounts of temporal data — often reaching petabytes — with millisecond access latency has become increasingly vital.
Deployment: Cache To produce business value, all our Metaflow projects are deployed to work with other production systems. In other cases, it is more convenient to share the results via a low-latency API. Metaflow Hosting caches the response, so Amber can fetch it after a while.
Buckle up as we delve into the world of Redis monitoring, exploring the most important Redis metrics, discussing essential tools, and even peering into the future of Redis performance management. Identifying key Redis metrics such as latency, CPU usage, and memory metrics is crucial for effective Redis monitoring.
Buckle up as we delve into the world of Redis® monitoring, exploring the most important Redis® metrics, discussing essential tools, and even peering into the future of Redis® performance management. Identifying key Redis® metrics such as latency, CPU usage, and memory metrics is crucial for effective Redis monitoring.
Amazon ElastiCache is a fully managed, in-memory caching service for customers to optimize the latency, performance and cost of their read workloads. Integration with Amazon CloudWatch gives customers visibility into key performance metrics, further simplifying system management.
Historically, NoSQL paid a lot of attention to tradeoffs between consistency, fault-tolerance and performance to serve geographically distributed systems, low-latency or highly available applications. Read/Write latency. Read/Write requests are processes with a minimal latency. Data Placement. Read/Write scalability.
Last week we looked at a function shipping solution to the problem; Cloudburst uses the more common data shipping to bring data to caches next to function runtimes (though you could also make a case that the scheduling algorithm placing function execution in locations where the data is cached a flavour of function-shipping too).
Deploying your application and database on the same VPC also provides the lowest possible latency path. This becomes really important for cache solutions like Redis™. Discover the current NoSQL vs. SQL usage, most popular databases, important metrics to track, and their most time-consuming database management tasks. Learn more.
Use cases such as gaming, ad tech, and IoT lend themselves particularly well to the key-value data model where the access patterns require low-latency Gets/Puts for known key values. The purpose of DynamoDB is to provide consistent single-digit millisecond latency for any scale of workloads.
This includes metrics such as query execution time, the number of queries executed per second, and the utilization of query cache and adaptive hash index. query cache: Disable (query_cache_size: 0, query_cache_type:OFF) innodb_adaptive_hash_index: Check adaptive hash index usage to determine its efficiency.
Here’s how the same test performed when running Percona Distribution for PostgreSQL 14 on these same servers: Queries: reads Queries: writes Queries: other Queries: total Transactions Latency (95th) MySQL (A) 1584986 1645000 245322 3475308 122277 20137.61 MySQL (B) 2517529 2610323 389048 5516900 194140 11523.48
In-Memory Storage Engine, as the name suggests, stores data in memory for faster performance and lower latencies. It uses a filesystem cache and write-ahead log for crash recovery. MongoDB makes use of both the filesystem cache and the WiredTiger internal cache. Compaction operation defragments data files & indexes.
The header is constructed via a name with an optional description and/or metric value. Web browsers expose a global Performance Timeline API to inspect details about specific metrics/events that have happened during the page lifecycle. Any server or proxy can add this header to the request to provide inspectable data.
Amazon DynamoDB offers low, predictable latencies at any scale. This is not just predictability of median performance and latency, but also at the end of the distribution (the 99.9th percentile), so we could provide acceptable performance for virtually every customer. s read latency, particularly as dataset sizes grow.
The primary metric for memory bandwidth in multicore processors is that maximum sustained performance when using many cores. This metric is interesting because we don’t always have the luxury of parallelizing every application we run, and our operating systems almost always process each call (e.g.,
Prediction serving latency matters. Booking.com estimate the value delivered by a model through randomized controlled trials which measure the impact on business metrics. clicks) that fails to convert into the desired business metric (e.g. clicks) that fails to convert into the desired business metric (e.g.
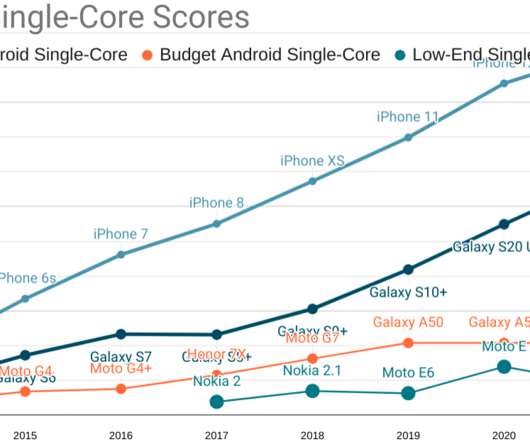
The scale of the effect can be deeply situational or hard to suss out without solid metrics. A then-representative $200USD device had 4-8 slow (in-order, low-cache) cores, ~2GiB of RAM, and relatively slow MLC NAND flash storage. The Moto G4 , for example. Don't pay a lot for an Android-shaped muffler.
Site performance is potentially the most important metric. Having a slow site might leave you on page 452 of search results, regardless of any other metric. I’m going to update my referenced URL to the new site to help decrease latency that adds drag to the initial page load. Compressing, minifying and caching assets.
These devices feature: Eight slow, big.LITTLE ARM cores (A75+A55, or A73+A53) built on last-generation processes with very little cache. Since at least 2017, I've grown increasingly frustrated at the way we collectively think about the tradeoffs in frontend metrics. 4GiB of RAM. Qualcomm has some 'splainin to do.
Google’s Core Web Vitals is a set of performance metrics that site owners can use to evaluate performance and diagnose performance issues. These metrics provide a different perspective on user experience: Largest Contentful Paint (LCP) Measures the time it takes for the main content on a webpage to load. One of the key Next.js
That’s hard for many reasons, including the differing trade-offs between throughput and latency that need to be made across the use cases. to understand YouTube video performance) drive tens of thousands of canned (known in advance) queries per second, that need to be served with latency in the tens of milliseconds.
About 5 years ago, I introduced you to AWS Availability Zones, which are distinct locations within a Region that are engineered to be insulated from failures in other Availability Zones and provide inexpensive, low latency network connectivity to other Availability Zones in the same region.
But do you know how Lighthouse calculates performance metrics like First Contentful Paint (FCP), Total Blocking Time (TBT), and Cumulative Layout Shift (CLS)? Still, there’s nothing in there to tell us about the data Lighthouse is using to evaluate metrics. But it comes with caveats. So why use lab data at all?
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content