This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
User Feed Service, Media Counter Service) read the actions from the streaming data store and performs their specific tasks. media search index, locations search index, and so forth) in future. When a user requests for feed then there will be two parallel threads involved in fetching the user feeds to optimize for latency.
By Xiaomei Liu , Rosanna Lee , Cyril Concolato Introduction Behind the scenes of the beloved Netflix streaming service and content, there are many technology innovations in media processing. Packaging has always been an important step in media processing. Uploading and downloading data always come with a penalty, namely latency.
by Varun Sekhri , Meenakshi Jindal , Burak Bacioglu Introduction At Netflix, to promote and recommend the content to users in the best possible way there are many Media Algorithm teams which work hand in hand with content creators and editors. But we cannot search or present low latency retrievals from files Etc.
It provides a good read on the availability and latency ranges under different production conditions. The upstream service calls the existing and new replacement services concurrently to minimize any latency increase on the production path. For instance, envision a response payload that delivers media streams for a playback session.
Berg , Romain Cledat , Kayla Seeley , Shashank Srikanth , Chaoying Wang , Darin Yu Netflix uses data science and machine learning across all facets of the company, powering a wide range of business applications from our internal infrastructure and content demand modeling to media understanding.
To further exacerbate the problem, the 302 response has a Cache-Control: must-revalidate, private. header , meaning that we will always make an outgoing request for this resource regardless of whether or not we’re hitting the site from a cold or a warm cache. com , which introduces yet more latency for the connection setup.
This enables customers to serve content to their end users with low latency, giving them the best application experience. In 2008, AWS opened a point of presence (PoP) in Hong Kong to enable customers to serve content to their end users with low latency. Since then, AWS has added two more PoPs in Hong Kong, the latest in 2016.
Assuming you want to load a social media layout, you might add a loading spinner or a skeleton loader to ensure that you don’t load an incomplete site. Active Memory Caching. When you want to get data that you already had quickly, you need to do caching — caching stores data that a user recently retrieved.
About the most complex part are some social media buttons for people to share the page. Redirects are often pretty light in terms of the latency that they add to a website, but they are an easy first thing to check, and they can generally be removed with little effort. Here’s the thing: performance is more than a one-off task.
webcam access via getUserMedia() or the Media Session API ) may attend deceptively small expansions in exposed API surface. Audio Worklets are a fundamental enabler for rich media and games on the web. Media Recorder. Media Source API (a.k.a. "MSE"). Meanwhile, truly transformative features (e.g. Audio Worklets.
The file size of your images of course is very important, but SEO and social media also play an important part in helping your website perform and convert better. How to optimize images for social media for better engagement and CTR. KeyCDN’s Cache Enabler plugin is fully compatible the HTML attributes that make images responsive.
Redis's microsecond latency has made it a de facto choice for caching. Four years ago, as part of our AWS fast data journey, we introduced Amazon ElastiCache for Redis , a fully managed, in-memory data store that operates at microsecond latency. TB of in-memory capacity in a single cluster.
ChatGPT: The InnoDB buffer pool is used by MySQL to cache frequently accessed data in memory. If we expand the cache concept more, the buffer pool could be even less if the working set (hot data) is smaller. The answer does not consider the queue or latency of the sample, which could indicate a disk with issues.
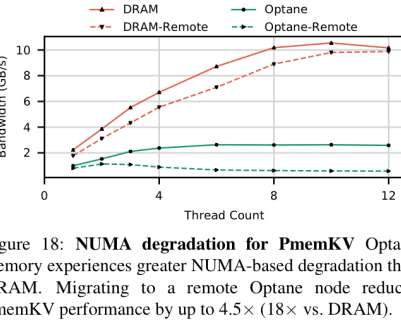
higher latency and lower bandwidth)… We have found the actual behavior of Optane DIMMs to be more complicated and nuanced than the "slower, persistent DRAM" label would suggest. The physical media is accessed in chunks of 256 bytes (an XPLine). The read latency for Optane is 2x-3x higher than DRAM.
Static content represents fixed web elements like HTML, CSS, JavaScript files, images, and media assets. They cache static content and enable lightning-fast delivery around the globe.This symbiosis reduces server load, boosts loading times, and ensures efficient content distribution. How Can You Boost Website Performance?To
You need to watch out for complex design elements, large media files, or slow browser rendering can delay the time it takes for the largest contentful element to render. It also opens up the possibility for more effective use of caching strategies, potentially enhancing load times further.
Static content represents fixed web elements like HTML, CSS, JavaScript files, images, and media assets. They cache static content and enable lightning-fast delivery around the globe.This symbiosis reduces server load, boosts loading times, and ensures efficient content distribution.
Hosted repositories also have an upper limit of ~2GB, so you may need to use a 3rd party service for media if you have many assets. When we talk about static site generators, incremental regeneration, or instant cache invalidation, it’s enough to make the layman’s eyes glaze over. Large preview ).
Using CDN for the whole website, you can offload most of the website traffic to your CDN which will handle not only large traffic spikes but also reduce the latency of content delivery. Secondly, having a CDN in front of origin (static site or APIs) reduces the global and regional latency. Eventually, we decided to move them to Jekyll.
So this November Shahin and I went to SC22 in Dallas TX together, as analysts, and started out in the media briefing event where the latest Top500 Report was revealed and discussed. Many HPC workloads synchronize work on a barrier, and work much better if there’s a consistently narrow latency distribution without a long tail.
media="(min-width: 990px)"> <source srcset="img@tablet.png, img@tablet-2x.png 2x". media="(min-width: 750px)"> <img srcset="img@mobile.png, img@mobile-2x.png 2x". It simulates a link with a 400ms RTT and 400-600Kbps of throughput (plus latency variability and simulated packet loss). alt="I don't know why.
The starting point is a set of three asumptions for an NVM-based programming model: Compared to traditional persistent media, NVM is fast. Therefore any programming abstraction must be low latency and the kernel needs to be kept off the path of persistent data access as much as possible. in front of that memory , as we saw last week).
Briefly, WAL requires that all the transaction log records associated with a particular data page be flushed to stable media before the data page itself can be flushed to stable media. Stable Media Stable media is often confused with physical storage.
Optimize media content for quality and/or bandwidth. Each of these categories opens up challenging problems in AI/visual algorithms, high-density computing, bandwidth/latency, distributed systems. Generate interactive and immersive content. Orchestrate the processing flow across an end-to-end infrastructure.
Mounting object storage in Netflix’s media processing platform By Barak Alon (on behalf of Netflix’s Media Cloud Engineering team) MezzFS (short for “Mezzanine File System”) is a tool we’ve developed at Netflix that mounts cloud objects as local files via FUSE. Disk Caching? — ? Regional caching? —?Netflix Replays? —?More
It’s widely accepted that self-hosted fonts are the fastest option: same origin means reduced network negotiation, predictable URLs mean we can preload , self-hosted means we can set our own cache-control. This is the danger of the print media hack. On a high-latency connection, this spells bad news. Enter preload.
Read Retry When a read from stable media returns an error, the read operation is tried again. Under certain conditions, issuing the same read returns the correct data.
The solution for this specific problem is that the user should optimize media by reducing the size of the images without lowering their quality. Moreover, caching utility may decrease the waiting time. Empty Cache (First View): The user access the website for the first time and has no cached data. Waiting time.
The solution for this specific problem is that the user should optimize media by reducing the size of the images without lowering their quality. Moreover, caching utility may decrease the waiting time. Empty Cache (First View): The user access the website for the first time and has no cached data. Waiting time.
Using an image CDN, such as KeyCDN, can significantly reduce the latency of your image delivery. Developers often focus on improving scripting performance, but they need to realize that the bulk of their performance woes come from media content… - Una Kravets Image optimization. For example, the query string ?width=600&quality=70
Assets Optimizations Brotli, AVIF, WebP, responsive images, AV1, adaptive media loding, video compression, web fonts, Google fonts. Estimated Input Latency tells us if we are hitting that threshold, and ideally, it should be below 50ms. This improves page load time and caching during navigations. Large preview ).
Estimated Input Latency tells us if we are hitting that threshold, and ideally, it should be below 50ms. Designed for the modern web, it responds to actual congestion, rather than packet loss like TCP does, it is significantly faster , with higher throughput and lower latency — and the algorithm works differently.
Estimated Input Latency tells us if we are hitting that threshold, and ideally, it should be below 50ms. PRPL stands for Pushing critical resource, Rendering initial route, Pre-caching remaining routes and Lazy-loading remaining routes on demand. An application shell is the minimal HTML, CSS, and JavaScript powering a user interface.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




































Let's personalize your content