This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Caching them at the other end: How long should we cache files on a user’s device? Plotted on the same horizontal axis of 1.6s, the waterfalls speak for themselves: 201ms of cumulative latency; 109ms of cumulative download. 4,362ms of cumulative latency; 240ms of cumulative download. Cache This is the easy one.
Teams often consider external caches when the existing database cannot meet the required service-level agreement (SLA). However, external caches are not as simple as they are often made out to be. This is a clear performance-oriented decision.
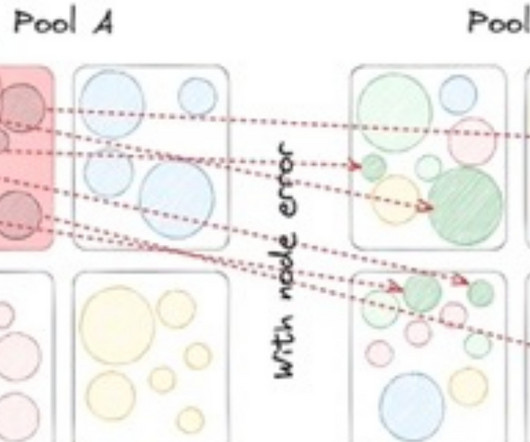
By: Rajiv Shringi , Oleksii Tkachuk , Kartik Sathyanarayanan Introduction In our previous blog post, we introduced Netflix’s TimeSeries Abstraction , a distributed service designed to store and query large volumes of temporal event data with low millisecond latencies. Today, we’re excited to present the Distributed Counter Abstraction.
This gives fascinating insights into the network topography of our visitors, and how much we might be impacted by high latency regions. Round-trip-time (RTT) is basically a measure of latency—how long did it take to get from one endpoint to another and back again? What is RTT? RTT isn’t a you-thing, it’s a them-thing.
We introduce a caching mechanism in the API gateway layer, allowing us to offload processing from singleton leader elected controllers without giving up strict data consistency and guarantees clients observe. We started seeing increased response latencies and leader servers running at dangerously high utilization.
“Latency” is the duration from the execution of a load instruction (to an address that misses in all the caches), and the completion of that load instruction when the data is returned from memory. . The example below is for a 2005-era processor with 60 ns memory latency and 6.4
Caching is the process of storing frequently accessed data or resources in a temporary storage location, such as memory or disk, to improve retrieval speed and reduce the need for repetitive processing. Bandwidth optimization: Caching reduces the amount of data transferred over the network, minimizing bandwidth usage and improving efficiency.
Caching is a critical technique for optimizing application performance by temporarily storing frequently accessed data, allowing for faster retrieval during subsequent requests. Multi-layered caching involves using multiple levels of cache to store and retrieve data.
Caches are very useful software components that all engineers must know. In this article, we are going to describe what is a cache and explain specific use cases focusing on the frontend and client side. In this article, we are going to describe what is a cache and explain specific use cases focusing on the frontend and client side.
We note that for MongoDB update latency is really very low (low is better) compared to other dbs, however the read latency is on the higher side. The latency table shows that 99th percentile latency for Yugabyte is quite high compared to others (lower is better). Again Yugabyte latency is quite high. Conclusion.
Users might already have the file cached. If website-a.com links to [link] , and a user goes from there to website-b.com who also links to [link] , then the user will already have that file in their cache. On a slower, higher-latency connection, the story is much, mush worse. Penalty: Caching. Myth: Cross-Domain Caching.
Because microprocessors are so fast, computer architecture design has evolved towards adding various levels of caching between compute units and the main memory, in order to hide the latency of bringing the bits to the brains. This avoids thrashing caches too much for B and evens out the pressure on the L3 caches of the machine.
These include challenges with tail latency and idempotency, managing “wide” partitions with many rows, handling single large “fat” columns, and slow response pagination. It also serves as central configuration of access patterns such as consistency or latency targets. Useful for keeping “n-newest” or prefix path deletion.
The GraphQL shim enabled client engineers to move quickly onto GraphQL, figure out client-side concerns like cache normalization, experiment with different GraphQL clients, and investigate client performance without being blocked by server-side migrations. To launch Phase 1 safely, we used AB Testing.
Yet, many are confined to a brief temporal window due to constraints in serving latency or training costs. In recommendation systems, context windows during inference are often limited to hundreds of eventsnot due to model capability but because these services typically require millisecond-level latency.
Your team celebrates a success story where a trace identified a pesky latency issue in your application's authentication service. It turns out that the fix we made did improve performance at one point but created a situation in which key information was never cached. But the celebrations are short-lived.
In this article, well discuss six ways to design websites for high-traffic events like product drops and sales: Compress and optimize images , Choose a scalable web host , Use a CDN , Leverage caching , Stress test websites , Refine the backend. You can also find optimization plugins or caching solutions that give you access to a CDN.
The new Amazon capability enables customers to improve the startup latency of their functions from several seconds to as low as sub-second (up to 10 times faster) at P99 (the 99th latency percentile). This can cause latency outliers and may lead to a poor end-user experience for latency-sensitive applications.
What Network Latency Means For Time To First Byte Lets add up all the network round trips in the example above: 2 server connections: 6 round trips. Thats where network latency comes in, or network round trip time (RTT) if we look at the time it takes to send data to a server and receive a response in the browser.
Spring Boot 2 uses Micrometer as its default application metrics collector and automatically registers metrics for a wide variety of technologies, like JVM, CPU Usage, Spring MVC, and WebFlux request latencies, cache utilization, data source utilization, Rabbit MQ connection factories, and more. That’s a large amount of data to handle.
The RAG process begins by summarizing and converting user prompts into queries that are sent to a search platform that uses semantic similarities to find relevant data in vector databases, semantic caches, or other online data sources.
When a user requests for feed then there will be two parallel threads involved in fetching the user feeds to optimize for latency. We will use a cache having an LRU based eviction policy for caching user feeds of active users. After that, the post gets added to the feed of all the followers in the columnar data storage.
Dynomite is a Netflix open source wrapper around Redis that provides a few additional features like auto-sharding and cross-region replication, and it provided Pushy with low latency and easy record expiry, both of which are critical for Pushy’s workload. As Pushy’s portfolio grew, we experienced some pain points with Dynomite.
Uploading and downloading data always come with a penalty, namely latency. Figure 3: Video Processing with Index and Virtual Assembly Using virtual assembly greatly improves the latency performance of the ProRes 422 HQ proxy generation by removing one round trip of cloud downloading and cloud uploading by the physical assembler.
This allows the app to query a list of “paths” in each HTTP request, and get specially formatted JSON (jsonGraph) that we use to cache the data and hydrate the UI. Being able to canary a new route let us verify latency and error rates were within acceptable limits. This meant that data that was static (e.g.
The first—and often most surprising for people to learn—thing that I want to draw your attention to is that TTFB counts one whole round trip of latency. The reason is because mobile networks are, as a rule, high latency connections. only to find that the resource they’re requesting isn’t in that PoP ’s cache.
It provides a good read on the availability and latency ranges under different production conditions. The upstream service calls the existing and new replacement services concurrently to minimize any latency increase on the production path. It helps expose memory leaks, deadlocks, caching issues, and other system issues.
With the Dynatrace Data Explorer, you can easily analyze metrics, such as client read/write latency by Cassandra nodes and disk space usage by keyspaces. You can also analyze table metrics, such as cache hits and misses. Provide a foundation for calculating metrics in dashboard charts.
Rajiv Shringi Vinay Chella Kaidan Fullerton Oleksii Tkachuk Joey Lynch Introduction As Netflix continues to expand and diversify into various sectors like Video on Demand and Gaming , the ability to ingest and store vast amounts of temporal data — often reaching petabytes — with millisecond access latency has become increasingly vital.
By monitoring metrics such as error rates, response times, and network latency, developers can identify trends and potential issues, so they don’t become critical. Load time and network latency metrics. Minimizing the number of network requests that your app makes can improve performance by reducing latency and improving load times.
Uber’s interactive analytics team shares how they integrated Alluxio’s data caching into Presto, the SQL query engine powering thousands of daily active users on petabyte scale at Uber, to dramatically reduce data scan latencies through leveraging Presto on local disks.
Moreover, common database optimizations like caching recently queried data don’t really work for alerting queries because, generally speaking, the last received datapoint is required for correctness. The fundamental idea behind Telltale is to detect anomalies on SLI metrics (for example, latency, error rates, etc).
Redis is a great caching solution for highly demanding applications, and there are […]. In fact, it is the number one key value store and eighth most popular database in the world. It has high throughput and runs from memory, but also has the ability to persist data on disk.
The Tech Hollow , an OSS technology we released a few years ago, has been best described as a total high-density near cache : Total : The entire dataset is cached on each node?—?there there is no eviction policy, and there are no cache misses. Near : the cache exists in RAM on any instance which requires access to the dataset.
RevenueCat extensively uses caching to improve the availability and performance of its product API while ensuring consistency. The company shared its techniques to deliver the platform, which can handle over 1.2 billion daily API requests. The team at RevenueCat created an open-source memcache client that provides several advanced features.
Key Takeaways Critical performance indicators such as latency, CPU usage, memory utilization, hit rate, and number of connected clients/slaves/evictions must be monitored to maintain Redis’s high throughput and low latency capabilities. It can achieve impressive performance, handling up to 50 million operations per second.
But we cannot search or present low latency retrievals from files Etc. We store all OperationIDs which are in STARTED state in a distributed cache (EVCache) for fast access during searches. Using memcache allows us to keep latencies for our search low (most of our queries are less than 100ms). This is obviously very expensive.
Deployment: Cache To produce business value, all our Metaflow projects are deployed to work with other production systems. In other cases, it is more convenient to share the results via a low-latency API. Metaflow Hosting caches the response, so Amber can fetch it after a while.
The Site Reliability Guardian helps automate release validation based on SLOs and important signals that define the expected behavior of your applications in terms of availability, performance errors, throughput, latency, etc. A study by Amazon found that increasing page load time by just 100 milliseconds costs 1% in sales.
Amazon ElastiCache is a fully managed, in-memory caching service for customers to optimize the latency, performance and cost of their read workloads. We allow customers to provision the number of input and output operations (IOPS) they require by using Amazon RDS with Provisioned IOPS.
To further exacerbate the problem, the 302 response has a Cache-Control: must-revalidate, private. header , meaning that we will always make an outgoing request for this resource regardless of whether or not we’re hitting the site from a cold or a warm cache. com , which introduces yet more latency for the connection setup.
Disk Caching? — ? MezzFS can be configured to cache objects on the local disk. Regional caching? —?Netflix If an application in region A is using MezzFS to read from an object stored in region B, MezzFS will cache the object in region A. we only pay the transfer costs for one worker, and the rest use the cached object.
The fact that this shows up as CPU time suggests that the reads were all hitting in the system cache and the CPU time was the kernel overhead (note ntoskrnl.exe on the first sampled call stack) of grabbing data from the cache. This means that there is no caching between RuntimeBroker.exe and this file.
For example, when monitoring a database, you’ll want to know about any latency when writing data to a disk or average query response time. Examples include a spike in memory utilization, a decrease in cache hit ratio, or an increase in CPU utilization.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content