This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Dynatrace is proud to be an AWS launch partner in support of Amazon Lambda SnapStart. For AWS Lambda, the largest contributor to startup latency is the time spent initializing an execution environment, which includes loading function code and initializing dependencies. What is Lambda? What is Lambda SnapStart?
Dynatrace is proud to partner with AWS to support AWS Lambda functions powered by x86-based processors and Graviton2 Arm-based processors announced earlier this year. According to the official AWS announcement, Graviton2-based Lambda functions offer up to 34% better price-performance improvement. Dynatrace Data explorer.
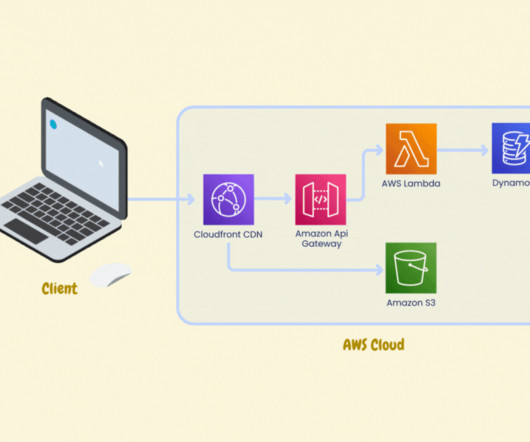
Amazon compute solutions are designed to streamline resource provisioning and container management with two services: AWS Lambda : Lambda provides serverless compute infrastructure that lets you run code in response to predetermined events or conditions and automatically manage all compute resources required for these processes.
Streams provide you with the underlying infrastructure to create new applications, such as continuously updated free-text search indexes, caches, or other creative extensions requiring up-to-date table changes. An AWS Lambda function is a simpler option that you can use, as it only requires you to code the logic, set it, and forget it.
Last week we looked at a function shipping solution to the problem; Cloudburst uses the more common data shipping to bring data to caches next to function runtimes (though you could also make a case that the scheduling algorithm placing function execution in locations where the data is cached a flavour of function-shipping too).
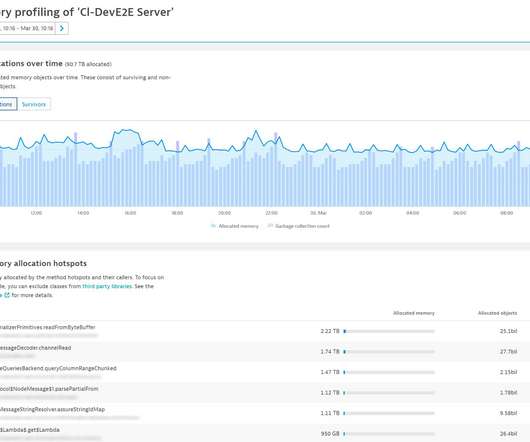
Somewhere within the lambda call, the code allocated about 80 GB and 1.27 You should also be careful when adding any sort of cache or object reuse strategy. You can even reduce the analysis timeframe to get a more accurate picture of what’s going on (see below). . So what’s going on here?
REDIS for caching. With the existing notification integrations for tools such as Slack, xMatters, ServiceNow, Lambda, JIRA, you can also pro-actively notify people in case there’s a problem: Dynatrace auto detected a problem with 3 kube proxies. Their technology stack looks like this: Spring Boot-based Microservices.
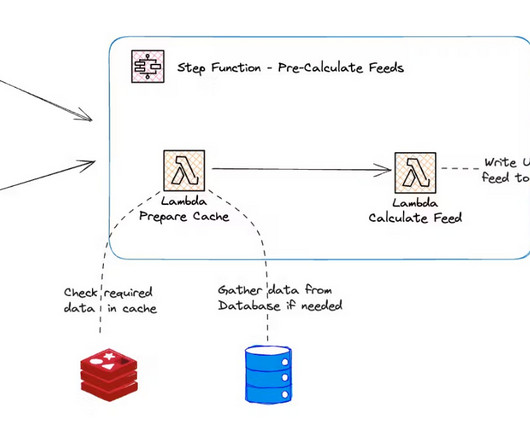
The company used serverless services on AWS, including Lambda, Step Functions, EventBridge, and Redis Cache. Hashnode created a scalable event-driven architecture (EDA) for composing feed data for thousands of users. The solution leverages Step Functions' distributed maps feature that enables high-concurrency processing.
Powered by `php-fpm` (soon as a Lambda layer directly). ? To learn how to speed up your WordPress installation using Redis Caching, check out our Using Redis Object Cache to Speed Up Your WordPress Installation post. Leave your comments: [link]. now/wordpress summary: ? ? size = 13mb. ? Just needs `wp-config.php`. ?
> system.time(wait1 <- normalmixEM(waiting, mu=c(50,80), lambda=.5, > system.time(wait1 <- normalmixEM(waiting, mu=c(50,80), lambda=.5, Changes in behavior of the system from minute to minute is going to change the height of each peak, as the workload mix and cache hit rates change.
By breaking an application such as Expedia.com into multiple components that have specific jobs (such as microservices, containers, and AWS Lambda functions), developers can be more productive by increasing scale and performance, reducing operations, increasing deployment agility, and enabling different components to evolve independently.
Since then we’ve introduced Amazon Kinesis for real-time streaming data, AWS Lambda for serverless processing, Apache Spark analytics on EMR, and Amazon QuickSight for high performance Business Intelligence. Team Internet AG is an ad tech company with a focus on domain monetization and real-time bidding.
Generally to cache data (including non-persistent data that never sees a backing store), to share non-persistent data across application services (e.g. ” Even re-reading that today, the letter of the law there is surprisingly strict to me: you can use the local memory space or filesystem as a brief single transaction cache, but no more.
Which I’m quite happy to see as my most recent data pipeline is based around Lambda, S3, and Athena, and it’s been working great for my use case. For query executors that can be frequently started and stopped the authors explore performance with cold and warm caches (where applicable), and also the horizontal and vertical scaling performance.
In many cases join is performed on a finite time window or other type of buffer e.g. LFU cache that contains most frequent tuples in the stream. Moreover, techniques like Lambda Architecture [6, 7] were developed and adopted to combine these solutions efficiently. Marz, “Big Data Lambda Architecture”. Jacobsen and R.
Serverless functions are stateless , but can opportunistically reuse cached state across invocations to speed up start times. Lambda operational semantics. But actually it all boils down to how you define the relation: two program states can be specified to be equivalent even when their cache state is different. Don’t do that!
Smaller microservices demonstrated much better instruction-cache locality than their monolithic counterparts. In section 7, the authors evaluate the performance and cost of running each of the five microservices systems on AWS Lambda instead of EC2. The most prominent source of misses, especially in the kernel, was Thrift.
Lastly, the whole website was very slow to load - CDN caching was not effective as a large number of pages were personalised for pricing and availability depending on suburb and postcode. This is achieved by caching content (static HTML page, assets, APIs) at a large number of geographically distributed edge locations.
For example, Lambda@Edge request pricing is $0.6 Split and Separate Static and Dynamic TrafficStatic traffic is traffic that is cached close to the user and stored and served to them by the nearest server. For example, the first 10TB to South America cost $0.11.Source: per one million requests.
I was a little restricted in my thinking the first time around and I’ve come to see FaaS as something not quite stateless, since caching state in a Lambda instance that might stick around for 5 hours is a perfectly reasonable idea. Lambda has configuration now and it has reserved capacity to help you avoid DoS’ing yourself.
CloudFront makes a simple choice here as it offers direct integration with all these services to let you cache responses across its global edge locations. And on top of that, you're doing computation at the edge using Lambda@Edge, where you've deployed thousands of lines of JavaScript code at the edge.
For example, Lambda@Edge request pricing is $0.6 Split and Separate Static and Dynamic TrafficStatic traffic is traffic that is cached close to the user and stored and served to them by the nearest server. For example, the first 10TB to South America cost $0.11.Source: per one million requests.
So it is convenient for all to use irrespective of internet speed and it works offline using cached data. IBM OpenWhisk, Microsoft Azure, AWS Lambda, and Google Cloud Functions are famous names that provide server-less services. Serverless Computing – AWS Lambda – Amazon Web Services. Image Source.
CloudFront makes a simple choice here as it offers direct integration with all these services to let you cache responses across its global edge locations. But since they don't rely much on dynamic content, but rely more upon static content that can be cached at the edge.
â€Businesses can adjust configurations to manage everything from basic distribution settings to intricate geo-targeted content caching and delivery strategies, all with the same ease.â€â€2. Easy MaintenanceWhen we say “easy maintenance,†it’s not a vague promise. Different providers have different plugins and configurations.
You can use various different sizes of build host (small, medium, large); you can use one of the predefined images as your build environment, or you can define your own docker image to use; and you can, if you want, cache data across build runs. An example of using AWS CodePipeline CodePipeline is a CD pipeline orchestrator.
Businesses can adjust configurations to manage everything from basic distribution settings to intricate geo-targeted content caching and delivery strategies, all with the same ease.2. Easy MaintenanceWhen we say “easy maintenance,” it’s not a vague promise. Migrating isn't as simple as 'copy-paste'.Even
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




























Let's personalize your content