This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
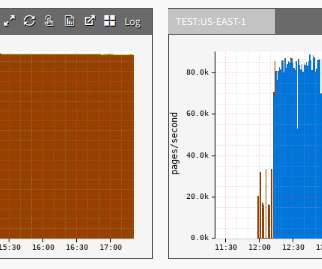
We decided to move one of our Java microservices?—?let’s A quick canary test was free of errors and showed lower latency, which is expected given that our standard canary setup routes an equal amount of traffic to both the baseline running on 4xl and the canary on 12xl. The problem It started off as a routine migration.
Spring Boot, on the other hand, is a Java framework for building cloud-native Java applications. It exports any pre-instrumented metrics for JVM, CPU Usage, Spring MVC, and WebFlux request latencies, cache utilization, data source utilization as well as custom metrics to the Dynatrace Metrics API v2. of Micrometer.
A single API team maintained both the Java implementation of the Falcor framework and the API Server. And we definitely couldn’t replay test non-functional requirements like caching and logging user interaction. To determine customer impact, we could compare various metrics such as error rates, latencies, and time to render.
This allows the app to query a list of “paths” in each HTTP request, and get specially formatted JSON (jsonGraph) that we use to cache the data and hydrate the UI. service with a composable JavaScript API that made downstream microservice calls, replacing the old Java API. Java…Script? It was a Node.js
Spring Boot, on the other hand, is a Java framework for building cloud-native Java applications. It exports any pre-instrumented metrics for JVM, CPU Usage, Spring MVC, and WebFlux request latencies, cache utilization, data source utilization as well as custom metrics to the Dynatrace Metrics API v2. of Micrometer.
Spring Boot, on the other hand, is a Java framework for building cloud-native Java applications. It exports any pre-instrumented metrics for JVM, CPU Usage, Spring MVC, and WebFlux request latencies, cache utilization, data source utilization as well as custom metrics to the Dynatrace Metrics API v2. of Micrometer.
That means multiple data indirections mean multiple cache misses. Mark LaPedus : MRAM, a next-generation memory type, is being touted as a replacement for embedded flash and cache applications. crabbone : This is the prism through which Java programmers view the world. They are very expensive. They never question this belief.
Today, I'm excited to announce the general availability of Amazon DynamoDB Accelerator (DAX) , a fully managed, highly available, in-memory cache that can speed up DynamoDB response times from milliseconds to microseconds, even at millions of requests per second. Adding caching when your app is already experiencing load is not easy.
Streams provide you with the underlying infrastructure to create new applications, such as continuously updated free-text search indexes, caches, or other creative extensions requiring up-to-date table changes. DynamoDB Streams enables your application to get real-time notifications of your tables’ item-level changes.
The most obvious and common way this happens is when companies try to evolve their caches into a data platform that can, for example, be used as highly available enterprise key-value stores for volatile data. Let’s look at a typical scenario involving the javax cache API, also known as JSR107. How hard can it be?
Reads usually have apps waiting on them; writes may not (write-back caching). biolatency From [bcc], this eBPF tool shows a latency histogram of disk I/O. total used free shared buff/cache available Mem: 64414 15421 349 5 48643 48409 Swap: 0 0 0. This is a 64-Gbyte memory system, and 48 Gbytes is in the page cache.
One which: interleaves log with dump events so that both can make progress allows to trigger dumps at any time does not use table locks uses commonly available database features DBLog Framework DBLog is a Java-based framework, able to capture changes in real-time and to take dumps.
One which: interleaves log with dump events so that both can make progress allows to trigger dumps at any time does not use table locks uses standardized database features DBLog Framework DBLog is a Java-based framework, able to capture changes in real-time and to take dumps.
The suite is built using popular OSS applications and representative technologies, deliberately using a mix of languages (C/C++, Java, Javascript, node.js, Python, Ruby, Go, Scala, …) and both RESTful and RPC (Thrift, gRPC) style service interfaces. The bottom line shows the tail latency impact in the microservices-based applications.
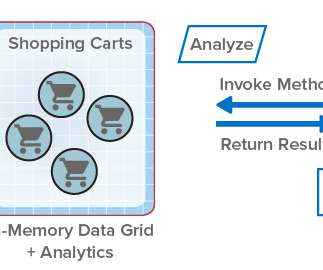
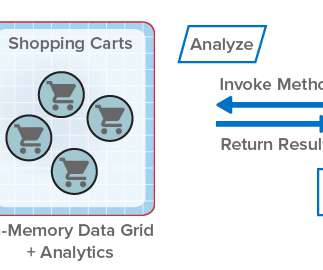
For more than fifteen years, ScaleOut StateServer® has demonstrated technology leadership as an in-memory data grid (IMDG) and distributed cache. Java applications use a similar mechanism.). In-Memory Data Grids for Fast-Changing Data. The Challenges with Parallel Queries.
For more than fifteen years, ScaleOut StateServer® has demonstrated technology leadership as an in-memory data grid (IMDG) and distributed cache. Java applications use a similar mechanism.). In-Memory Data Grids for Fast-Changing Data. The Challenges with Parallel Queries.
Reads usually have apps waiting on them; writes may not (write-back caching). biolatency From [bcc], this eBPF tool shows a latency histogram of disk I/O. This is a 64-Gbyte memory system, and 48 Gbytes is in the page cache (the file system cache). This shows many cache misses, with a hit ratio varying between 6.5
A pipeline breaker occurs when the output of one operator must be materialized to disk or transferred over the network, as opposed to being directly communicated from operator to operator via CPU cache, or, in the worst case, via RAM. The RDBMS was slower than TensorFlow for GPU-based implementations of neural networks, however.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





















Let's personalize your content