This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
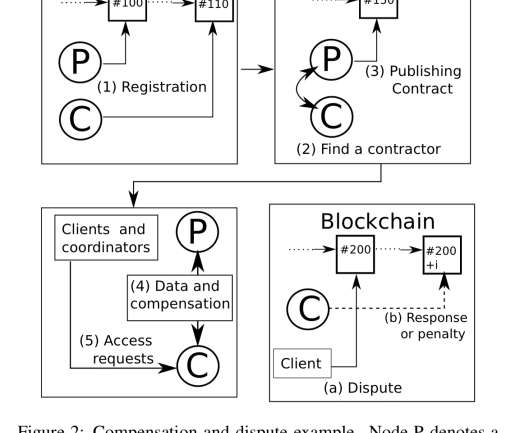
However, this category requires near-immediate access to the current count at low latencies, all while keeping infrastructure costs to a minimum. Eventually Consistent : This category needs accurate and durable counts, and is willing to tolerate a slight delay in accuracy and a slightly higher infrastructure cost as a trade-off.
Caching is the process of storing frequently accessed data or resources in a temporary storage location, such as memory or disk, to improve retrieval speed and reduce the need for repetitive processing.
Findings provide insights into Kubernetes practitioners’ infrastructure preferences and how they use advanced Kubernetes platform technologies. Kubernetes infrastructure models differ between cloud and on-premises. Kubernetes infrastructure models differ between cloud and on-premises. Kubernetes moved to the cloud in 2022.
Vidhya Arvind , Rajasekhar Ummadisetty , Joey Lynch , Vinay Chella Introduction At Netflix our ability to deliver seamless, high-quality, streaming experiences to millions of users hinges on robust, global backend infrastructure. The KV data can be visualized at a high level, as shown in the diagram below, where three records are shown.
This means you no longer have to provision, scale, and maintain servers to run your applications, databases, and storage systems. Instead of worrying about infrastructure management functions, such as capacity provisioning and hardware maintenance, teams can focus on application design, deployment, and delivery. Reliability.
FUN FACT : In this talk , Rodrigo Schmidt, director of engineering at Instagram talks about the different challenges they have faced in scaling the data infrastructure at Instagram. After that, the post gets added to the feed of all the followers in the columnar data storage. System Components. Fetching User Feed. Optimization.
To meet this need, the Studio Infrastructure team has created Netflix Workstations. They could need a GPU when doing graphics-intensive work or extra large storage to handle file management. Instead, we created a service to take the most popular configurations and cache them. Artists need many components to be customized.
The Key-Value Abstraction offers a flexible, scalable solution for storing and accessing structured key-value data, while the Data Gateway Platform provides essential infrastructure for protecting, configuring, and deploying the data tier. Let’s dive into the various aspects of this abstraction.
But it’s not easy: to pull this off, VFX studios need to build and operate serious technical infrastructure (compute, storage, networking, and software licensing), otherwise known as a “ render farm.” VFX studios of varying sizes and locations can leverage these solutions to meet the unique rendering needs of their productions.
Data warehouses offer a single storage repository for structured data and provide a source of truth for organizations. Unlike data warehouses, however, data is not transformed before landing in storage. A data lakehouse provides a cost-effective storage layer for both structured and unstructured data. Data management.
Building an elastic query engine on disaggregated storage , Vuppalapati, NSDI’20. This paper presents Snowflake design and implementation along with a discussion on how recent changes in cloud infrastructure (emerging hardware, fine-grained billing, etc.) But the ephemeral storage service for intermediate data is not based on S3.
A distributed storage system is foundational in today’s data-driven landscape, ensuring data spread over multiple servers is reliable, accessible, and manageable. Understanding distributed storage is imperative as data volumes and the need for robust storage solutions rise.
are stored in secure storage layers. Amsterdam is built on top of three storage layers. To avoid the ES query for the list of indices for every indexing request, we keep the list of indices in a distributed cache. It is also responsible for asset discovery, validation, sharing, and for triggering workflows.
This includes how quickly the application loads, how much load it is putting on the device, how much storage is being used, and how frequently it crashes. By analyzing trends in resource consumption and performance metrics, developers can predict future needs and plan for capacity upgrades or infrastructure changes. Issue remediation.
This is particularly important as we build out new functionality that relies on Pushy; a strong, stable infrastructure foundation allows our partners to continue to build on top of Pushy with confidence. KeyValue is an abstraction over the storage engine itself, which allows us to choose the best storage engine that meets our SLO needs.
Streamlined asset caching: Asset caching is critical for creating accurate replays. Minimal infrastructure impact: The way your session replay tool compresses, stores, and processes video data can have an impact on system performance. Make sure you know what assets your replay tool is recording and how you can access them.
Combined, these integration points cover the full application stack from infrastructure monitoring to end-user experience. This enriches the data by providing cloud infrastructure metrics, metadata exposed by Azure combined with the data captured by Dynatrace OneAgent. How does Dynatrace fit in?
Storing frequently accessed data in faster storage, usually in-memory caching, improves data retrieval speed and overall system performance. Beyond A study by Amazon found that increasing page load time by just 100 milliseconds costs 1% in sales. Beyond efficiency, validating performance thresholds is also crucial for revenues.
Today AWS has launched Amazon ElastiCache , a new service that makes it easy to add distributed in-memory caching to any application. Amazon ElastiCache handles the complexity of creating, scaling and managing an in-memory cache to free up brainpower for more differentiating activities. Driving Storage Costs Down for AWS Customers.
Capturing data is critical to understanding how your applications and infrastructure are performing at any given time. The data is incredibly plentiful and difficult to store over long periods due to capacity limitations — a reason why private and public cloud storage services have been a boon to DevOps teams. What is telemetry data?
Last week we looked at a function shipping solution to the problem; Cloudburst uses the more common data shipping to bring data to caches next to function runtimes (though you could also make a case that the scheduling algorithm placing function execution in locations where the data is cached a flavour of function-shipping too).
DNS is an absolutely critical piece of the internet infrastructure. There are two main types of DNS servers: authoritative servers and caching resolvers. But the real robustness of the DNS system comes through the way lookups are handled, which is what caching resolvers do. Driving Storage Costs Down for AWS Customers.
As some of you may remember I was pretty excited when Amazon Simple Storage Service (S3) released its website feature such that I could serve this weblog completely from S3. My templates and blog posts are now located in DropBox and thus locally cached at each machine I use. Driving Storage Costs Down for AWS Customers.
That means multiple data indirections mean multiple cache misses. Mark LaPedus : MRAM, a next-generation memory type, is being touted as a replacement for embedded flash and cache applications. The third wing of the architecture piece is the “domain specific system-on-chip.” They are very expensive.
To monitor Redis instances effectively, collect Redis metrics focusing on cache hit ratio, memory allocated, and latency threshold. Advanced monitoring techniques enable you to identify potential issues, such as high latency, CPU utilization, command throughput, and cache hit rate before they become major problems.
Common Infrastructure ExpensesYour first step in optimizing CDN expenses isn’t to look for the best-priced solution but to remember that a cheaper price isn’t always the best deal. For example, if you’re deploying the infrastructure for an e-commerce website, security becomes a fundamental requirement.
While caching continues to be a dominant use of ElastiCache for Redis, we see customers increasingly use it as an in-memory NoSQL database. Each shard can include up to five read replicas to ensure high availability so that both planned and unforeseen outages of the infrastructure do not cause application outages. Building upon Redis.
In response, we began to develop a collection of storage and database technologies to address the demanding scalability and reliability requirements of the Amazon.com ecommerce platform. These services also require the ability to scale infrastructure incrementally to accommodate growth in request rates or dataset sizes.
To monitor Redis® instances effectively, collect Redis metrics focusing on cache hit ratio, memory allocated, and latency threshold. Advanced monitoring techniques enable you to identify potential issues, such as high latency, CPU utilization, command throughput, and cache hit rate before they become major problems.
For example, the IMDG must be able to efficiently create millions of objects in each server to make use of its huge storage capacity. Given all this, we thought it would be a good opportunity to see how we are doing relative to the competition, and in particular, relative to Microsoft’s AppFabric caching for Windows on-premise servers.
Our straining database infrastructure on Oracle led us to evaluate if we could develop a purpose-built database that would support our business needs for the long term. All of this is done for you automatically and with zero downtime so that you can focus on your customers, your applications, and your business.
The best paper runner-up was “ Dynamic Multi-Resolution Data Storage ”. . Goodman, and “Speculative Cache Ways: On-Demand Cache Resource Allocation” published at MICRO 1999 by David H.
Typically, organizations build specialized infrastructure for each of these use cases. This, however, creates silos of data and processing, and results in a complex, expensive, and harder to maintain infrastructure. Cache all the things. Procella employs multiple caches to mitigate this networking penalty. are divided.
Amazon ElastiCache customers will see their prices drop by up to 10%, depending on their cache node types. We continuously apply all our innovative skills to the design of datacenters, servers, storage, network, etc. Similarly, Amazon RDS will cut its On-Demand prices by up to 10% and Reserved Instance prices by up to 42%.
Common Infrastructure ExpensesYour first step in optimizing CDN expenses isn’t to look for the best-priced solution but to remember that a cheaper price isn’t always the best deal. For example, if you’re deploying the infrastructure for an e-commerce website, security becomes a fundamental requirement.
As such, fault tolerance is more expensive to implement because it requires dedicated infrastructure that completely mirrors the primary system. Components of high availability infrastructure Multiple copies of data Data redundancy helps prevent data loss due to hardware or software failures.
Today, we’ll address storing and serving files for both single-server and scalable deployments while considering factors like compression, caching, and availability. We’ll also discuss the costs and benefits of CDNs and dedicated file storage solutions. First, you’ll need to install the libraries boto3 and django-storages.
One initial, easy step to moving your SQL Server on-premises workloads to the cloud is using Azure VMs to run your SQL Server workloads in an infrastructure as a service (IaaS) scenario. There are also large differences in storage capacity and throughput between these extremes. GHz, 128MB of L3 cache, 128 PCIe 4.0
You should expect one-time implementation cost (depending CMS and business requirements it can cost 200,000 USD to 3M USD) and yearly hosting infrastructure cost (proportional to load and traffic but typically 30,000 USD - 300,000 USD per year). Most of cloud object/blob storage services have native support for static site hosting.
Three different 5G phones are used, including a ZTE Axon10 Pro with powerful communication (SDX 50 5G modem) and compute (Qualcomm Snapdragon TM855) capabilities together with 256GB of storage. Emerging architectures that shorten the path length, e.g. edge caching and computing, may also confine the latency. Application performance.
Our approach differs substantially by (1) providing economic incentives for data to be contributed and integrated into existing schemas, (2) offering a SQL interface instead of graph based approaches, (3) including the computational and storageinfrastructure in the architectural vision.
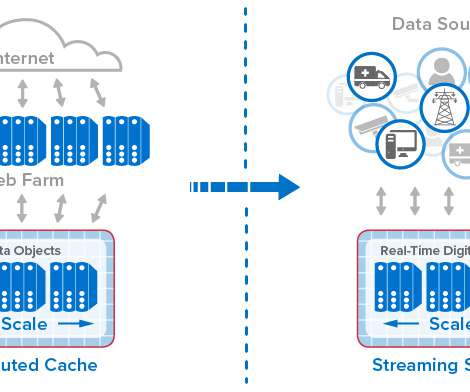
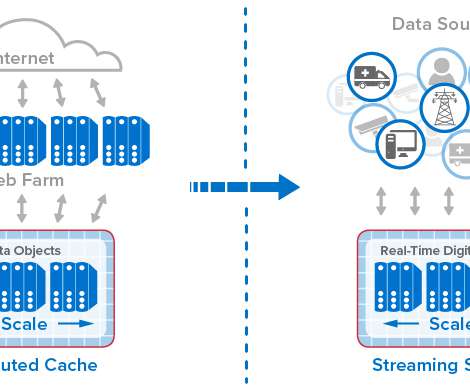
From Distributed Caches to Real-Time Digital Twins. The pace of these changes has made it challenging for server-based infrastructures to manage fast-growing populations of users and data sources while maintaining fast response times.
From Distributed Caches to Real-Time Digital Twins. The pace of these changes has made it challenging for server-based infrastructures to manage fast-growing populations of users and data sources while maintaining fast response times.
This meant a lot of time was spent on things like cycle time analysis, build pipeline design, test automation, and infrastructure automation. One of the most intriguing is the idea of “turning the database inside out” where the internal sub-components of a database—storage, log, cache and view—are broken into parts and deployed separately.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content