This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
A quick canary test was free of errors and showed lower latency, which is expected given that our standard canary setup routes an equal amount of traffic to both the baseline running on 4xl and the canary on 12xl. We also see much higher L1 cache activity combined with 4x higher count of MACHINE_CLEARS.
Because microprocessors are so fast, computer architecture design has evolved towards adding various levels of caching between compute units and the main memory, in order to hide the latency of bringing the bits to the brains. CFS is widely used and therefore well tested and Linux machines around the world run with reasonable performance.
On-premises data centers invest in higher capacity servers since they provide more flexibility in the long run, while the procurement price of hardware is only one of many cost factors. Of the organizations in the Kubernetes survey, 71% run databases and caches in Kubernetes, representing a +48% year-over-year increase.
A lot of useful information can be retrieved from this schema, for example, table metadata and foreign key relations, but trying to query I_S can induce performance degradation if your server is under heavy load, as shown in the following example test. The same tests have been executed in Percona Server for MySQL 5.7
Your synthetic testing tool shows you how your pages perform in a clean lab environment, using variables – such as browser, connection type, even CPU power – that you've selected. For a myriad of reasons, older hardware can't always accommodate faster speeds. Most people use the same hardware for between five to ten years.
These are the errors that also need attention during the testing phase. We can divide the errors during software development into two sections for easy understanding: Software errors Testing errors. These errors are caught during software documentation testing. Hardware error. Testing errors. Software errors.
Hardware Memory The amount of RAM to be provisioned for database servers can vary greatly depending on the size of the database and the specific requirements of the company. By caching hot datasets, indexes, and ongoing changes, InnoDB can provide faster response times and utilize disk IO in a much more optimal way. I hope this helps!
This is why our BYOC pricing is less than our Dedicated Hosting pricing, as the costs listed for BYOC are only what you pay for ScaleGrid and don’t include your hardware costs. This becomes really important for cache solutions like Redis™. Where to host your cloud database? Expert Tip. Security Groups.
” This acts as a step to ensure durability by recovering lost data from the same journal files in case of crashes, power, and hardware failures between the checkpoints (see below) Here’s what the process looks like. The same data, in the form of pages inside the Wiredtiger cache, are also marked dirty. wt and index-*.wt).
Only in extreme circumstances does the cost (in processor time and I-cache footprint) translate to a tangible benefit - circumstances which usually resort to hand-coded assembly anyway. It shouldn't be 10%, unless it's cache effects. And for leaf routines (which never establish a frame), this is a non-issue.
Effective management of memory stores with policies like LRU/LFU proactive monitoring of the replication process and advanced metrics such as cache hit ratio and persistence indicators are crucial for ensuring data integrity and optimizing Redis’s performance. Cache Hit Ratio The cache hit ratio represents the efficiency of cache usage.
This includes metrics such as query execution time, the number of queries executed per second, and the utilization of query cache and adaptive hash index. query cache: Disable (query_cache_size: 0, query_cache_type:OFF) innodb_adaptive_hash_index: Check adaptive hash index usage to determine its efficiency.
Krste Asanovic from UC Berkeley kicked off the main program sharing his experience on “ Rejuvenating Computer Architecture Research with Open-Source Hardware ”. He ended the keynote with a call to action for open hardware and tools to start the next wave of computing innovation. This year’s MICRO had three inspiring keynote talks.
Defining high availability In general terms, high availability refers to the continuous operation of a system with little to no interruption to end users in the event of hardware or software failures, power outages, or other disruptions. If a primary server fails, a backup server can take over and continue to serve requests.
The rationale behind these methods is that frontend should be able to fetch transient information very efficiently and separately from fetching of heavy-weight domain entities because this information cannot be cached. So, the only way was to cache all necessary data to minimize interaction with RDBMS.
It’s not just a simple tweak you can turn on/off; it’s a long-time process that touches almost every single item in your stack, including both hardware and software sides of the system. Application scalability is the potential of an application to grow in time, being able to efficiently handle more and more requests per minute (RPM).
In my case the directory structure of my documents directory was entirely cached in memory so there was zero disk activity required to do the scan, but some users are not so lucky. Is there some RuntimeBroker caching? All of this testing was done on Windows 10, 21H2. Is that a WinRT flaw, or a Voice Recorder flaw?
Thanks to the Web Platform Tests project and wpt.fyi , we have the makings of an answer for the first: Tests that fail only in a given browser. wpt.fyi 's new Compat 2021 dashboard narrows this full range of tests to a subset chosen to represent the most painful compatibility bugs : Stable-channel Compat 2021 results over time.
Key Takeaways Distributed storage systems benefit organizations by enhancing data availability, fault tolerance, and system scalability, leading to cost savings from reduced hardware needs, energy consumption, and personnel. They maintain fault tolerance and redundancy by replicating this information throughout various nodes in the system.
Coverage is assessed with a walk-test (4-5km/h) over all road segments on the campus, monitoring the physical-layer information from both 5G and 4G at each location. Emerging architectures that shorten the path length, e.g. edge caching and computing, may also confine the latency. Let’s jump in! 5G Coverage. What about UHD video?
Cache Merril. Companies can use technology roadmaps to review their internal IT , DevOps, infrastructure, architecture, software, internal system, and hardware procurement policies and procedures with innovation and efficiency in mind. A typical IT roadmap covers everything from requirements to testing and integrations.
A then-representative $200USD device had 4-8 slow (in-order, low-cache) cores, ~2GiB of RAM, and relatively slow MLC NAND flash storage. Hardware Past As Performance Prologue. Regardless, the overall story for hardware progress remains grim, particularly when we recall how long device replacement cycles are: Tap for a larger version.
Cache-Headers missing? During performance tests, Lighthouse records many metrics focused on what a user sees and experiences. Service workers that will cache the bytecode result of a parsed and compiled script. After that, it’ll be mitigated by cache. What changed in PageSpeed 5.0? They are: Time to Interactive ( TTI ).
It enables the user to measure database performance and make comparative judgements about database hardware and software. These factors meant that often when looking for database performance information, the results for a particular combination of software and hardware were not available. Cached vs Scaled Workloads.
For most high-end processors these values have remained in the range of 75% to 85% of the peak DRAM bandwidth of the system over the past 15-20 years — an amazing accomplishment given the increase in core count (with its associated cache coherence issues), number of DRAM channels, and ever-increasing pipelining of the DRAMs themselves.
In this particular investigation, which spanned twenty months, we suspected hardware failure, compiler bugs, linker bugs, and other possibilities. Jumping too quickly to blaming hardware or build tools is a classic mistake, but in this case the mistake was that we weren’t thinking big enough. I decided it was time to try science.
Our biggest achievements this year have centred on making it easier for you to: Gather more meaningful real user monitoring (RUM) data Get actionable insights from Core Web Vitals Simplify your synthetic testing Get expert performance coaching when and how you need it Keep reading to learn more.
It’s one of the things we look at during a health audit, and Kimberly has a great query from her Plan cache and optimizing for adhoc workloads post that’s part of our toolkit. About 1GB of the plan cache is for prepared and procedure plans, and they only take up about 300MB worth of space. DBCC FREEPROCCACHE ; GO. EXEC dbo. [
Eleventy is I/O heavy, and for correctness sake, it didn't do much caching. The caches added by these changes are likely error prone and may bloat build memory for large sites. If you've got a big 11ty project, I'd appreciate help testing them. Details about build hardware, OS, and template configuration are particularly useful.
React Native users need to pay even more attention to that because that framework uses the built-in OS widgets, so you actually need to pay even more attention to how the app looks by testing it extensively on both platforms, without being able to switch between iOS and Material widget on the fly like it’s possible with Flutter. Next Steps.
. …software operating on persistent data structures requires "global" pointers that remain valid after a process terminates, while hardware requires that a diverse set of devices all have the same mappings they need for bulk transfers to and from memory, and that they be able to do so for a potentially heterogeneous memory system.
On multi-core machines – which is the majority of the hardware nowadays – and in the cloud, we have multiple cores available for use. Aurora Parallel Query response time (for queries which can not use indexes) can be 5x-10x better compared to the non-parallel fully cached operations. Test data and versions. row.
Therefore, before we attempt to measure our database performance, we should know the system or cloud instance to be tested in detail. From this data, it can be argued that HammerDB is a better candidate to test MySQL database engine and CPU performance. to MySQL 8.0.32, different test scenarios can give very different conclusions.
A wide range of users with different operating systems, browsers, hardware configurations and other variables provides a wide sample size that helps developers discover as many issues as possible. It’s also important for developers not to confuse real user data with real user testing. What is real user monitoring (RUM)?
Key areas include: Configuration parameter tuning : This tuning involves altering variables such as memory allocation, disk I/O settings, and concurrent connections based on specific hardware and requirements. This not only results in cost savings by minimizing hardware requirements but also has the potential to decrease cloud expenses.
One such challenge has been the emergence of marginal defect-driven faults that are difficult to address solely using best practices in manufacturing test and screening. We then discuss defects observed, the role of test and design to address this problem, and identify research opportunities. Each fault has a root cause.
When a QoS violation is predicted to occur and a culprit microservice located, Seer uses a lower level tracing infrastructure with hardware monitoring primitives to identify the reason behind the QoS violation. E.g., in memcached there are five main internal stages, each of which has a hardware or software queue associated with it.
Stable media is commonly physical disk storage, but other devices and certain caching facilities qualify as well. Many high-end disk subsystems provide high-speed cache facilities to reduce the latency of read and write operations. This cache is often supported by a battery-powered backup facility.
My development collogues and I are starting a regular blog series, outlining the vast range of scalability improvements, allowing SQL Server 2016 to run across a wide array of hardware configurations, faster and better than previous releases of SQL Server. The following table is taken from an ASP.NET, session state cache, stress test.
Automating testing against an objective baseline. Add onto that the yawning chasm between low-end and high-end device performance thanks to chip design factors like cache sizes, and it can be difficult to know where to set a device baseline. What’s going on here? The Affordability Calculation. How long is too long?
Managed Instance sets a max server memory value based on the deployed tier, however when I tested resizing the environment, the max memory value was not dynamically changed. If you have big physical hardware with defaults, then you should look at optimizing MAXDOP. With modern hardware, the cost estimation of 5 is outdated.
The modes that are important are: “Flat” vs “Cache” In “Flat” mode, MCDRAM memory is used as directly accessible memory, occupying the upper 16 GiB of physical address space. In “Cache” mode, MCDRAM memory is used as an L3 cache for the main DDR4 memory. numactl).
The following chart shows the same 1TB database testing. On the same hardware/machine repeat steps 1 thru 3 using an instance of SQL Server 2016 CTP 3.0 Note: You may need to execute the dbcc a second time so buffer cache is hot, eliminating I/O sub-system variants. MultiObjectScanner = Older design. CheckScanner = New design.
The censorship and monitoring of internet have evolved from anti-virus-like and firewall software to hardware security patches for all devices that uses internet. For users and companies doing business in China, it’s critical to continually test and monitor website accessibility and performance.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





















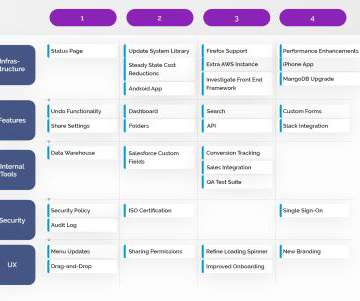







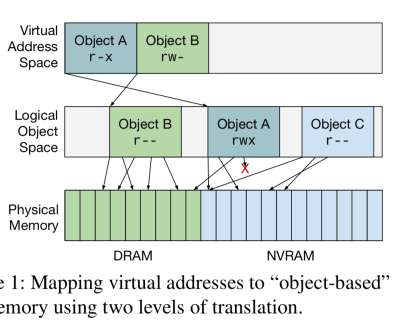


















Let's personalize your content