This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This means you no longer have to provision, scale, and maintain servers to run your applications, databases, and storage systems. Instead of worrying about infrastructure management functions, such as capacity provisioning and hardware maintenance, teams can focus on application design, deployment, and delivery. Reliability.
They need specialized hardware, access to petabytes of images, and digital content creation applications with controlled licenses. They could need a GPU when doing graphics-intensive work or extra large storage to handle file management. Instead, we created a service to take the most popular configurations and cache them.
On-premises data centers invest in higher capacity servers since they provide more flexibility in the long run, while the procurement price of hardware is only one of many cost factors. Of the organizations in the Kubernetes survey, 71% run databases and caches in Kubernetes, representing a +48% year-over-year increase.
A distributed storage system is foundational in today’s data-driven landscape, ensuring data spread over multiple servers is reliable, accessible, and manageable. Understanding distributed storage is imperative as data volumes and the need for robust storage solutions rise.
Building an elastic query engine on disaggregated storage , Vuppalapati, NSDI’20. This paper presents Snowflake design and implementation along with a discussion on how recent changes in cloud infrastructure (emerging hardware, fine-grained billing, etc.) But the ephemeral storage service for intermediate data is not based on S3.
But it’s not easy: to pull this off, VFX studios need to build and operate serious technical infrastructure (compute, storage, networking, and software licensing), otherwise known as a “ render farm.” Many shows have needs that exceed 100,000 frames, so aggregate rendering time can impact the timely delivery of a show on Netflix.
Hardware Memory The amount of RAM to be provisioned for database servers can vary greatly depending on the size of the database and the specific requirements of the company. By caching hot datasets, indexes, and ongoing changes, InnoDB can provide faster response times and utilize disk IO in a much more optimal way.
” This acts as a step to ensure durability by recovering lost data from the same journal files in case of crashes, power, and hardware failures between the checkpoints (see below) Here’s what the process looks like. The same data, in the form of pages inside the Wiredtiger cache, are also marked dirty. wt and index-*.wt).
Not everybody agreed that the "N-ary Storage Model" (NSM) was the best approach for all workloads but it stayed dominant until hardware constraints, especially on caches, forced the community to revisit some of the alternatives. A Decomposition Storage Model , George P. Copeland and Setrag N.
File systems unfit as distributed storage backends: lessons from 10 years of Ceph evolution Aghayev et al., In this case, the assumption that a distributed storage backend should clearly be layered on top of a local file system. What is a distributed storage backend? SOSP’19. This is not surprising in hindsight.
The Solution: Distributed Caching. The solution to this challenge is to use scalable, memory-based data storage for fast-changing data so that web sites can keep up with exploding workloads. It’s not enough simply to lash together a set of servers hosting a collection of in-memory caches.
The Solution: Distributed Caching. The solution to this challenge is to use scalable, memory-based data storage for fast-changing data so that web sites can keep up with exploding workloads. It’s not enough simply to lash together a set of servers hosting a collection of in-memory caches.
This includes metrics such as query execution time, the number of queries executed per second, and the utilization of query cache and adaptive hash index. query cache: Disable (query_cache_size: 0, query_cache_type:OFF) innodb_adaptive_hash_index: Check adaptive hash index usage to determine its efficiency.
Krste Asanovic from UC Berkeley kicked off the main program sharing his experience on “ Rejuvenating Computer Architecture Research with Open-Source Hardware ”. He ended the keynote with a call to action for open hardware and tools to start the next wave of computing innovation. This year’s MICRO had three inspiring keynote talks.
The DBMS is key to maintaining these aspects by offering a storage system that allows users to perform operations such as data insertion, deletion, and selection, thereby promoting enhanced data integration across diverse applications and platforms. This is significant for modern business environments. <p>The </p>
Effective management of memory stores with policies like LRU/LFU proactive monitoring of the replication process and advanced metrics such as cache hit ratio and persistence indicators are crucial for ensuring data integrity and optimizing Redis’s performance. Cache Hit Ratio The cache hit ratio represents the efficiency of cache usage.
To monitor Redis instances effectively, collect Redis metrics focusing on cache hit ratio, memory allocated, and latency threshold. Advanced monitoring techniques enable you to identify potential issues, such as high latency, CPU utilization, command throughput, and cache hit rate before they become major problems.
The rationale behind these methods is that frontend should be able to fetch transient information very efficiently and separately from fetching of heavy-weight domain entities because this information cannot be cached. So, the only way was to cache all necessary data to minimize interaction with RDBMS.
To monitor Redis® instances effectively, collect Redis metrics focusing on cache hit ratio, memory allocated, and latency threshold. Advanced monitoring techniques enable you to identify potential issues, such as high latency, CPU utilization, command throughput, and cache hit rate before they become major problems.
This blog post gives a glimpse of the computer systems research papers presented at the USENIX Annual Technical Conference (ATC) 2019, with an emphasis on systems that use new hardware architectures. GAIA proposed to expand the OS page cache into accelerator memory. Heterogeneous ISA. Programmable I/O Devices.
In response, we began to develop a collection of storage and database technologies to address the demanding scalability and reliability requirements of the Amazon.com ecommerce platform. s pricing is simple and predictable: Storage is $1 per GB per month. The growth of Amazonâ??s Domain scaling limitations. Amazon DynamoDBâ??s
More specifically, we’re going to talk about storage and UI differences, which are the ones that most often cause confusion to developers when writing Flutter code that they want to be cross-platform. Example 1: Storage. Secure Storage On Mobile. The situation when it comes to mobile apps is completely different.
By utilizing query folding effectively, you can ensure that Power BI sends optimized queries to MySQL, which can take advantage of the database’s indexing, caching, and processing capabilities. It involves pushing as much of the data transformation and filtering operations back to the data source (e.g.,
Defining high availability In general terms, high availability refers to the continuous operation of a system with little to no interruption to end users in the event of hardware or software failures, power outages, or other disruptions. If a primary server fails, a backup server can take over and continue to serve requests.
This removes the burden of purchasing and maintaining your hardware, storage and networking infrastructure, while still giving you a very familiar experience with Windows and SQL Server itself. There are also large differences in storage capacity and throughput between these extremes. GHz, 128MB of L3 cache, 128 PCIe 4.0
Make sure your system can handle next-generation DRAM,” [link] Nov 2011 - [Hruska 12] Joel Hruska, “The future of CPU scaling: Exploring options on the cutting edge,” [link] Feb 2012 - [Gregg 13] Brendan Gregg, “Blazing Performance with Flame Graphs,” [link] 2013 - [Shimpi 13] Anand Lal Shimpi, “Seagate to Ship 5TB HDD in 2014 using Shingled Magnetic (..)
The basic tier provides up to 5 DTUs with standard storage. The standard tier supports from 10 up to 3000 DTUs with standard storage and the premium tier supports 125 up to 4000 DTUs with premium storage, which is orders of magnitude faster than standard storage. New Hardware Configuration for Provisioned Compute Tier.
Three different 5G phones are used, including a ZTE Axon10 Pro with powerful communication (SDX 50 5G modem) and compute (Qualcomm Snapdragon TM855) capabilities together with 256GB of storage. Emerging architectures that shorten the path length, e.g. edge caching and computing, may also confine the latency. Application performance.
Chrome has missed several APIs for 3+ years: Storage Access API. An extension to Service Workers that enables browsers to present users with cached content when offline. is access to hardware devices. This allows customisation and use of specialised features without custom, proprietary software for niche hardware.
This results in expedited query execution, reduced resource utilization, and more efficient exploitation of the available hardware resources. This not only enhances performance but also enables you to make more efficient use of your hardware resources, potentially resulting in cost savings on infrastructure.
More importantly, UDM utilizes a single storage backend with benefits of multiple storage systems which avoids moving data across systems hence data duplication, and data consistency issues. Delta implements the unified data management layer by extending the Amazon S3 object storage for ACID transactions and automatic data indexing.
It enables the user to measure database performance and make comparative judgements about database hardware and software. These factors meant that often when looking for database performance information, the results for a particular combination of software and hardware were not available. Cached vs Scaled Workloads.
As database performance is heavily influenced by the performance of storage, network, memory, and processors, we must understand the upper limit of these key components. For storage, FIO is generally used. Storage: The system has a SATA drive for the operating system and one NVMe (Intel SSD D7-P5510 (3.84 Database: MySQL 8.0.31
Byte-addressable non-volatile memory,) NVM will fundamentally change the way hardware interacts, the way operating systems are designed, and the way applications operate on data. The beauty of persistent memory is that we can use memory layouts for persistent data (with some considerations for volatile caches etc. What about security?
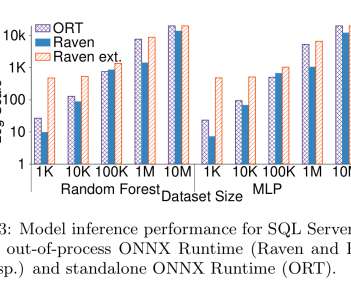
… based on interactions with enterprise customers, we expect that storage and inference of ML models will be subject to the same scrutiny and performance requirements of sensitive/mission-critical operational data. For single or very small numbers of predictions, Raven is faster due to SQL Server’s caching. The last word.
On multi-core machines – which is the majority of the hardware nowadays – and in the cloud, we have multiple cores available for use. now has a version which will support parallelism for SELECT queries (utilizing the read capacity of storage nodes underneath the Aurora cluster). The second and third run used the cached data.
In our experiment we deliberately size the active working-set to NOT fit into the metadata cache. On the same hardware with AES enabled – the time is cut in half. Additionally AES reduces the need to cache metadata in DRAM since local access is so fast. For large datasets (e.g.
Stable Media Stable media is often confused with physical storage. SQL Server defines stable media as storage that can survive system restart or common failure. Stable media is commonly physical disk storage, but other devices and certain caching facilities qualify as well.
Key areas include: Configuration parameter tuning : This tuning involves altering variables such as memory allocation, disk I/O settings, and concurrent connections based on specific hardware and requirements. This not only results in cost savings by minimizing hardware requirements but also has the potential to decrease cloud expenses.
Hosted on commodity clusters or cloud infrastructures, IMDGs harness the power of distributed computing to deliver scalable storage capacity and access throughput, along with integrated high availability. Looking beyond distributed caching, it’s their ability to perform data-parallel analysis that gives IMDGs such exciting capabilities.
Hosted on commodity clusters or cloud infrastructures, IMDGs harness the power of distributed computing to deliver scalable storage capacity and access throughput, along with integrated high availability. Looking beyond distributed caching, it’s their ability to perform data-parallel analysis that gives IMDGs such exciting capabilities.
The pipelines can be stateful and the engine’s middleware should provide a persistent storage to enable state checkpointing. In many cases join is performed on a finite time window or other type of buffer e.g. LFU cache that contains most frequent tuples in the stream. Interoperability with Hadoop.
Autoscaling tiered cloud storage in Anna. Could it be Analyzing efficient stream processing on modern hardware ? On one of the themes that captures my imagination, how changing hardware platform influence system design: Rethinking database high availability with RDMA networks. Research papers. (In In random order!).
Make sure your system can handle next-generation DRAM,” [link] , Nov 2011 [Hruska 12] Joel Hruska, “The future of CPU scaling: Exploring options on the cutting edge,” [link] , Feb 2012 [Gregg 13] Brendan Gregg, “Blazing Performance with Flame Graphs,” [link] , 2013 [Shimpi 13] Anand Lal Shimpi, “Seagate to Ship 5TB HDD in 2014 using Shingled Magnetic (..)
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content