This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Instead of worrying about infrastructure management functions, such as capacity provisioning and hardware maintenance, teams can focus on application design, deployment, and delivery. Speed is next; serverless solutions are quick to spin up or down as needed, and there are no delays due to limited storage or resource access.
Rendering is the final step in the VFX creation process, and processing on a render farm often can take several hours to complete just a single frame of a show, even when this process runs on the latest high-end hardware. Rendering on AWS provides the flexibility to control how quickly a project is completed.
Reducing CPU Utilization to now only consume 15% of initially provisioned hardware. Missing Cache Settings – Make sure you cache resources that don’t change often on the browser or use a CDN. Missing caching layers, e.g. provide a read-only cache for static data. Missing retry and failover implementations.
Have you ever looked at the page speed metrics – such as Start Render and Largest Contentful Paint – for your site in both your synthetic and real user monitoring tools and wondered "Why are these numbers so different?" End-user connection speed If you live in an urban centre, you may enjoy connection speeds of 150 Mbps or more.
A trip from a device in London to a server in New York has a theoretical best-case speed of 28ms over fibre, but this makes lots of very optimistic assumptions. only to find that the resource they’re requesting isn’t in that PoP ’s cache. Expect closer to 75ms. Routing: If you are using a CDN—and you should be!—a
Hardware Memory The amount of RAM to be provisioned for database servers can vary greatly depending on the size of the database and the specific requirements of the company. By caching hot datasets, indexes, and ongoing changes, InnoDB can provide faster response times and utilize disk IO in a much more optimal way. I hope this helps!
Effective management of memory stores with policies like LRU/LFU proactive monitoring of the replication process and advanced metrics such as cache hit ratio and persistence indicators are crucial for ensuring data integrity and optimizing Redis’s performance. Cache Hit Ratio The cache hit ratio represents the efficiency of cache usage.
You run a speed test on a website, and the results don’t match what you personally experience. Perhaps you feel like your site loads fairly quickly, but the speed test results are sub-optimal. We wanted to have control of the hardware that runs our tests and deliver consistent results. Don’t stress over a score.
The Solution: Distributed Caching. A widely used technology called distributed caching meets this need by storing frequently accessed data in memory on a server farm instead of within a database. This speeds up accesses and updates while offloading back-end database servers. Let’s take a look at some of these capabilities.
The Solution: Distributed Caching. A widely used technology called distributed caching meets this need by storing frequently accessed data in memory on a server farm instead of within a database. This speeds up accesses and updates while offloading back-end database servers. Let’s take a look at some of these capabilities.
Streams provide you with the underlying infrastructure to create new applications, such as continuously updated free-text search indexes, caches, or other creative extensions requiring up-to-date table changes. Cross-region replication allows us to distribute data across the world for redundancy and speed. ” DynamoDB Triggers.
Query performance Query performance is a key performance indicator (KPI) in MySQL, as it measures the efficiency and speed of query execution. This includes metrics such as query execution time, the number of queries executed per second, and the utilization of query cache and adaptive hash index.
To monitor Redis instances effectively, collect Redis metrics focusing on cache hit ratio, memory allocated, and latency threshold. Such as INFO which gives statistics about the server, LATENCY LATEST which provides latency measurements in real time and MONITOR which allows observation of the clients transmitted command at live speed.
To monitor Redis® instances effectively, collect Redis metrics focusing on cache hit ratio, memory allocated, and latency threshold. Such as INFO which gives statistics about the server, LATENCY LATEST which provides latency measurements in real time and MONITOR which allows observation of the client’s transmitted command at live speed.
## References I've reproduced the references from my SREcon22 keynote below, so you can click on links: - [Gregg 08] Brendan Gregg, “ZFS L2ARC,” [link] Jul 2008 - [Gregg 10] Brendan Gregg, “Visualizations for Performance Analysis (and More),” [link] 2010 - [Greenberg 11] Marc Greenberg, “DDR4: Double the speed, double the latency?
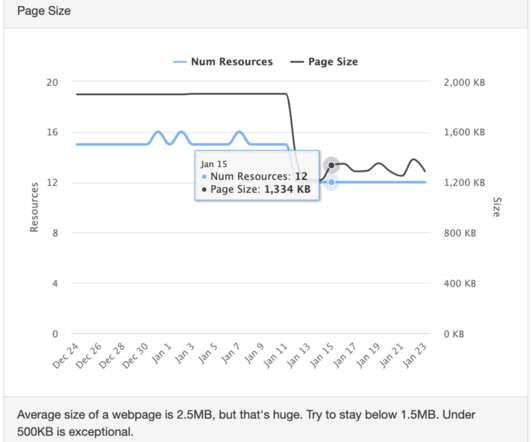
In this article, we uncover how PageSpeed calculates it’s critical speed score. It’s no secret that speed has become a crucial factor in increasing revenue and lowering abandonment rates. Now that Google uses page speed as a ranking factor, many organizations have become laser-focused on performance. Cache-Headers missing?
This is crucial due to mobile devices requiring additional optimizations because they typically have less powerful hardware and a slower network connection when compared to desktop devices. For example, while the average mobile download speed on 4G in Switzerland is fast at 35.2 Mbps ( Opensignal ). For example, the query string ?width=600&quality=70
We are standing on the eve of the 5G era… 5G, as a monumental shift in cellular communication technology, holds tremendous potential for spurring innovations across many vertical industries, with its promised multi-Gbps speed, sub-10 ms low latency, and massive connectivity. Throughput and latency. Application performance.
By utilizing query folding effectively, you can ensure that Power BI sends optimized queries to MySQL, which can take advantage of the database’s indexing, caching, and processing capabilities. It involves pushing as much of the data transformation and filtering operations back to the data source (e.g.,
This blog post gives a glimpse of the computer systems research papers presented at the USENIX Annual Technical Conference (ATC) 2019, with an emphasis on systems that use new hardware architectures. GAIA proposed to expand the OS page cache into accelerator memory. ATC ’19 was refreshingly different. Heterogeneous ISA.
These can be mitigated through the implementation of: efficient query optimization caching of database queries utilization of database indexes implementation of session storage employing database read replication and sharding. By implementing data abstraction techniques, these challenges can be addressed more effectively.
This results in expedited query execution, reduced resource utilization, and more efficient exploitation of the available hardware resources. This not only enhances performance but also enables you to make more efficient use of your hardware resources, potentially resulting in cost savings on infrastructure.
The paper sets out what we can do in software given today’s hardware, and along the way also highlights areas where cooperation from hardware will be needed in the future. Microarchitectural channels. There are also stateless interconnects including buses and on-chip networks. Threat scenarios. The five requirements of Time Protection.
Gen 5 is the primary hardware option now for most regions since Gen 4 is aging out. Hyperscale achieves high performance from each compute node having SSD-based caches which helps minimize the network round trips to fetch data. New Hardware Configuration for Provisioned Compute Tier. GB per vCore.
This removes the burden of purchasing and maintaining your hardware, storage and networking infrastructure, while still giving you a very familiar experience with Windows and SQL Server itself. BTW, the "i" in the Standard_E64is_v3 naming means that the instance is isolated to hardware dedicated to a single customer.
There's work in progress to make incremental builds possible for 11ty, but until then, the speed of a full build is the speed at which changes are visible. Eleventy is I/O heavy, and for correctness sake, it didn't do much caching. Details about build hardware, OS, and template configuration are particularly useful.
This post is targeted towards the questions most often asked by non-technical management who want to get up to speed on what HammerDB is (what it isn’t) and how it can benefit their organization. It enables the user to measure database performance and make comparative judgements about database hardware and software.
” This contains updated and new material that reflects the latest C++ standards and compilers, with a focus to using modern C++11/14/17 effectively on modern hardware and memory architectures. On April 25-27, I’ll be in Stockholm (Kista) giving a three-day seminar on “High-Performance and Low-Latency C++.”
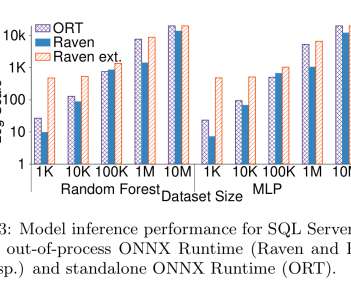
" This is very important performance-wise: unlike most traditional ML frameworks, NN engines support out-of-the-box hardware acceleration through GPUs/FPGAs/NPUs as well as code generation." This speed-up came through SQL Server automatically parallelising the scan and predict operators, as compared to the ORT sequential execution.
PostgreSQL performance optimization aims to improve the efficiency of a PostgreSQL database system by adjusting configurations and implementing best practices to identify and resolve bottlenecks, improve query speed, and maximize database throughput and responsiveness.
In this particular investigation, which spanned twenty months, we suspected hardware failure, compiler bugs, linker bugs, and other possibilities. Jumping too quickly to blaming hardware or build tools is a classic mistake, but in this case the mistake was that we weren’t thinking big enough.
In our experiment we deliberately size the active working-set to NOT fit into the metadata cache. On the same hardware with AES enabled – the time is cut in half. Additionally AES reduces the need to cache metadata in DRAM since local access is so fast. For large datasets (e.g.
Apache Arrow's in-memory columnar layout is specifically optimized for data locality for better performance on modern hardware like CPUs and GPUs. In contrast, Alluxio a middleware for data access - think Alluxio storage layer as fast cache. Leveraging the recent hardware advances.
Could it be Analyzing efficient stream processing on modern hardware ? On one of the themes that captures my imagination, how changing hardware platform influence system design: Rethinking database high availability with RDMA networks. Some cool algorithms: Pigeonring speeds up thresholded similarity searches. Do we want that?
Stable media is commonly physical disk storage, but other devices and certain caching facilities qualify as well. Many high-end disk subsystems provide high-speedcache facilities to reduce the latency of read and write operations. This cache is often supported by a battery-powered backup facility.
GHz 4th Generation Intel Xeon Scalable processors (code-named Sapphire Rapids) Up to 20% higher compute performance than z1d instances Up to 50 Gbps of networking speed Up to 40 Gbps of bandwidth to the Amazon Elastic Block Store (EBS) We can also verify these capabilities by running some simple benchmarks on the different subsystems.
JavaScript is the single most expensive part of any page in ways that are a function of both network capacity and device speed. Add onto that the yawning chasm between low-end and high-end device performance thanks to chip design factors like cache sizes, and it can be difficult to know where to set a device baseline.
Page was restored from back-forward cache – The bfcache essentially stores the full page in memory when navigating away from the page. These browser profiles don't reference specific emulated hardware or a particular browser. Delivery type The delivery type of a page indicates how it was delivered to the browser.
References I've reproduced the references from my SREcon22 keynote below, so you can click on links: [Gregg 08] Brendan Gregg, “ZFS L2ARC,” [link] , Jul 2008 [Gregg 10] Brendan Gregg, “Visualizations for Performance Analysis (and More),” [link] , 2010 [Greenberg 11] Marc Greenberg, “DDR4: Double the speed, double the latency?
The censorship and monitoring of internet have evolved from anti-virus-like and firewall software to hardware security patches for all devices that uses internet. Websites and apps that are allowed to be used in China can be accessed at a very fast speed, up to the recent 5G (20Gbps) upgrade.
More importantly, if this works out well, this could lead to a radical improvement in performance by leveraging hardware trends such as GPUs and TPUs. They demonstrated that neural nets based learned index outperforms cache-optimized B-Tree index by up to 70% in speed while saving an order-of-magnitude in memory.
The core does not have enough load bandwidth to perform all of these extra load operations at full speed. E.g., on Haswell you can execute two loads per cycle of any size or alignment as long as neither crosses a cache-line boundary.
While hardware such as intelligent SANs, Solid State Disk, and other advancements have helped speed things up, wasted space in index can translate to wasted space in the buffer pool as well as wasting more I/O. If you have big physical hardware with defaults, then you should look at optimizing MAXDOP. SQL Server Agent Alerts.
For a benchmark configuration of eight networked 8xH100+2xCPU vs a shared memory 64xGH200 cluster there is some speedup due to the lower overhead and higher speed of the memory interconnect, and the extra capacity of 64 Grace CPUs vs. 16 IntelCPUs. These line up much better with what Id expect from the hardware capabilities.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content