This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Instead of worrying about infrastructure management functions, such as capacity provisioning and hardware maintenance, teams can focus on application design, deployment, and delivery. Scalability. Finally, there’s scalability. Serverless architecture offers several benefits for enterprises. Simplicity. Data Store.
Through effortless provisioning, a larger number of small hosts provide a cost-effective and scalable platform. On-premises data centers invest in higher capacity servers since they provide more flexibility in the long run, while the procurement price of hardware is only one of many cost factors.
In this article, we explain why you should pay attention to when building a scalable application. What Is Application Scalability? Application scalability is the potential of an application to grow in time, being able to efficiently handle more and more requests per minute (RPM).
Werner Vogels weblog on building scalable and robust distributed systems. a Fast and Scalable NoSQL Database Service Designed for Internet Scale Applications. The original Dynamo design was based on a core set of strong distributed systems principles resulting in an ultra-scalable and highly reliable database system.
The percentage in degradation will vary depending on many factors {hardware, workload, number of tables, configuration, etc.}. having to open each table.frm (and in which my test runs, I have purposely read a very high number of tables compared to “Table-open-cache” variable). Results for Percona Server for MySQL 8.0
Hardware Memory The amount of RAM to be provisioned for database servers can vary greatly depending on the size of the database and the specific requirements of the company. By caching hot datasets, indexes, and ongoing changes, InnoDB can provide faster response times and utilize disk IO in a much more optimal way. I hope this helps!
Streams provide you with the underlying infrastructure to create new applications, such as continuously updated free-text search indexes, caches, or other creative extensions requiring up-to-date table changes. DynamoDB Streams enables your application to get real-time notifications of your tables’ item-level changes.
Scalability is one of the main drivers of the NoSQL movement. A database should accommodate itself to different data distributions, cluster topologies and hardware configurations. Read/Write scalability. This makes master a bottleneck, so it becomes crucial to partition data into independent shards to be scalable. (H,
Key Takeaways Distributed storage systems benefit organizations by enhancing data availability, fault tolerance, and system scalability, leading to cost savings from reduced hardware needs, energy consumption, and personnel. Variations within these storage systems are called distributed file systems.
The Solution: Distributed Caching. The solution to this challenge is to use scalable, memory-based data storage for fast-changing data so that web sites can keep up with exploding workloads. It’s not enough simply to lash together a set of servers hosting a collection of in-memory caches.
The Solution: Distributed Caching. The solution to this challenge is to use scalable, memory-based data storage for fast-changing data so that web sites can keep up with exploding workloads. It’s not enough simply to lash together a set of servers hosting a collection of in-memory caches.
Despite initial investment costs, DBMS presents long-term savings and improved efficiency through automated processes, efficient query optimizations, and scalability, contributing to enhanced decision-making and end-user productivity. Practical Applications of DBMS DBMS finds practical applications in various fields.
To monitor Redis instances effectively, collect Redis metrics focusing on cache hit ratio, memory allocated, and latency threshold. Advanced monitoring techniques enable you to identify potential issues, such as high latency, CPU utilization, command throughput, and cache hit rate before they become major problems.
Defining high availability In general terms, high availability refers to the continuous operation of a system with little to no interruption to end users in the event of hardware or software failures, power outages, or other disruptions. It also supports the flexibility and scalability of the database infrastructure.
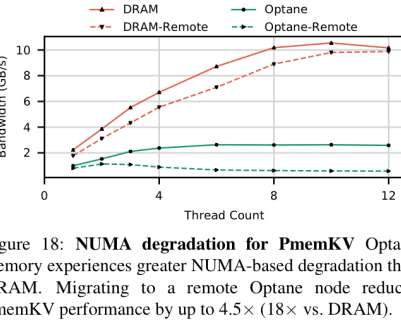
An empirical guide to the behavior and use of scalable persistent memory , Yang et al., The Optane DIMM is the first scalable, commercially available NVDIMM. Use non-temporal stores for large transfers, and control cache evictions. FAST’20. most recently ‘ Efficient lock-free durable sets ‘). to 0.98.
To monitor Redis® instances effectively, collect Redis metrics focusing on cache hit ratio, memory allocated, and latency threshold. Advanced monitoring techniques enable you to identify potential issues, such as high latency, CPU utilization, command throughput, and cache hit rate before they become major problems.
This paper is all about the design of efficient data structures for far-memory, which turns out to have consequences reaching all the way down to the hardware. A far memory data structure has: far data in far memory, containing the core content of the data structure data caches at clients algorithms for operations. Refreshable vectors.
The rationale behind these methods is that frontend should be able to fetch transient information very efficiently and separately from fetching of heavy-weight domain entities because this information cannot be cached. So, the only way was to cache all necessary data to minimize interaction with RDBMS.
This blog post gives a glimpse of the computer systems research papers presented at the USENIX Annual Technical Conference (ATC) 2019, with an emphasis on systems that use new hardware architectures. GAIA proposed to expand the OS page cache into accelerator memory. ATC ’19 was refreshingly different. Heterogeneous ISA.
Hosted on commodity clusters or cloud infrastructures, IMDGs harness the power of distributed computing to deliver scalable storage capacity and access throughput, along with integrated high availability. Looking beyond distributed caching, it’s their ability to perform data-parallel analysis that gives IMDGs such exciting capabilities.
Hosted on commodity clusters or cloud infrastructures, IMDGs harness the power of distributed computing to deliver scalable storage capacity and access throughput, along with integrated high availability. Looking beyond distributed caching, it’s their ability to perform data-parallel analysis that gives IMDGs such exciting capabilities.
Most Intel microprocessors support “HyperThreading” (Intel’s trademark for their implementation of “simultaneous multithreading”) — which allows the hardware to support (typically) two “Logical Processors” for each physical core. leaving half of the Logical Processors idle).
Most Intel microprocessors support “HyperThreading” (Intel’s trademark for their implementation of “simultaneous multithreading”) — which allows the hardware to support (typically) two “Logical Processors” for each physical core. leaving half of the Logical Processors idle).
It enables the user to measure database performance and make comparative judgements about database hardware and software. These factors meant that often when looking for database performance information, the results for a particular combination of software and hardware were not available. Cached vs Scaled Workloads.
This results in expedited query execution, reduced resource utilization, and more efficient exploitation of the available hardware resources. This not only enhances performance but also enables you to make more efficient use of your hardware resources, potentially resulting in cost savings on infrastructure.
Breaking that assumption allowed Ceph to introduce a new storage backend called BlueStore with much better performance and predictability, and the ability to support the changing storage hardware landscape. It should offer high bandwidth, horizontal scalability, fault tolerance, and strong consistency. Supporting new storage hardware.
There are three common mechanisms to access remote memory: modifying applications, modifying virtual memory, and hardware-level cache coherence support. The memory bandwidth will be a key player because the traditional method to add memory bandwidth by adding memory channels is not scalable. About application transparency.
A wide range of users with different operating systems, browsers, hardware configurations and other variables provides a wide sample size that helps developers discover as many issues as possible. Teams can measure the performance of all application dependencies, including databases, web services, caching, and more. Usage performance.
GHz 4th Generation Intel Xeon Scalable processors (code-named Sapphire Rapids) Up to 20% higher compute performance than z1d instances Up to 50 Gbps of networking speed Up to 40 Gbps of bandwidth to the Amazon Elastic Block Store (EBS) We can also verify these capabilities by running some simple benchmarks on the different subsystems.
Key areas include: Configuration parameter tuning : This tuning involves altering variables such as memory allocation, disk I/O settings, and concurrent connections based on specific hardware and requirements. Scalability: As an application expands and needs to handle more data and user loads, the database must scale accordingly.
My development collogues and I are starting a regular blog series, outlining the vast range of scalability improvements, allowing SQL Server 2016 to run across a wide array of hardware configurations, faster and better than previous releases of SQL Server. The following table is taken from an ASP.NET, session state cache, stress test.
Could it be Analyzing efficient stream processing on modern hardware ? On one of the themes that captures my imagination, how changing hardware platform influence system design: Rethinking database high availability with RDMA networks. What’s their secret??? What if the network was no longer the bottleneck?
In many cases join is performed on a finite time window or other type of buffer e.g. LFU cache that contains most frequent tuples in the stream. Kafka messaging queue is well known implementation of such a buffer that also supports scalable distributed deployments, fault-tolerance, and provides high performance.
This is crucial due to mobile devices requiring additional optimizations because they typically have less powerful hardware and a slower network connection when compared to desktop devices. width=600&quality=70 Combine this with our WebP caching to automatically deliver the highest performing image format. Mbps ( Opensignal ).
On the other hand, we have hardware constraints on memory and CPU due to JavaScript parsing times (we’ll talk about them in detail later). Gatsby (React), Vuepress (Vue) Preact CLI , and PWA Starter Kit provide reasonable defaults for fast loading out of the box on average mobile hardware. ??Also,
On the other hand, we have hardware constraints on memory and CPU due to JavaScript parsing times (we’ll talk about them in detail later). Gatsby.js (React), Preact CLI , and PWA Starter Kit provide reasonable defaults for fast loading out of the box on average mobile hardware. Image credit: Addy Osmani ) ( Large preview ).
Edge caching. In general, Egnyte connect architecture shards and caches data at different levels based on: Amount of data. Nginx for disk based caching. We use different types of caching techniques depending on the problem statements. Disk based caching. Hybrid Sync. On prem data processing. Offline access.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content