This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The report also reveals the leading programming languages practitioners use for application workloads. are the top 3 programming languages for Kubernetes application workloads. Of the organizations in the Kubernetes survey, 71% run databases and caches in Kubernetes, representing a +48% year-over-year increase.
Because microprocessors are so fast, computer architecture design has evolved towards adding various levels of caching between compute units and the main memory, in order to hide the latency of bringing the bits to the brains. This avoids thrashing caches too much for B and evens out the pressure on the L3 caches of the machine.
To create a CPU core that can execute a large number of instructions in parallel, it is necessary to improve both the architecturewhich includes the overall CPU design and the instruction set architecture (ISA) designand the microarchitecture, which refers to the hardware design that optimizes instruction execution.
Rendering is the final step in the VFX creation process, and processing on a render farm often can take several hours to complete just a single frame of a show, even when this process runs on the latest high-end hardware. This program is just one example of the many ways Netflix strives to entertain the world.
This is why our BYOC pricing is less than our Dedicated Hosting pricing, as the costs listed for BYOC are only what you pay for ScaleGrid and don’t include your hardware costs. This becomes really important for cache solutions like Redis™. Where to host your cloud database?
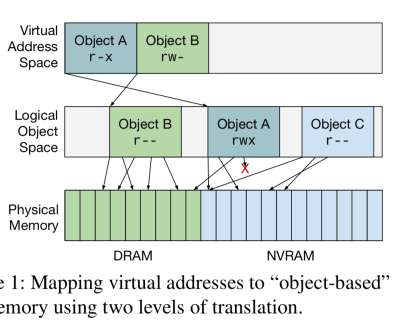
Compress objects, not cache lines: an object-based compressed memory hierarchy Tsai & Sanchez, ASPLOS’19. Existing cache and main memory compression techniques compress data in small fixed-size blocks, typically cache lines. These techniques work well for scientific programs that are dominated by arrays.
The technical program, put together by program chairs Tor Aamodt and Reetuparna Das , showcased key innovations across a wide range of computer architecture topics, from domain-specific accelerators to in/near-memory computing and from security to quantum computing. . This year’s MICRO had three inspiring keynote talks. Conference.
Streams provide you with the underlying infrastructure to create new applications, such as continuously updated free-text search indexes, caches, or other creative extensions requiring up-to-date table changes. For example, you can program home sensors to write the state of temperature, water, gas, and electricity directly to DynamoDB.
Effective management of memory stores with policies like LRU/LFU proactive monitoring of the replication process and advanced metrics such as cache hit ratio and persistence indicators are crucial for ensuring data integrity and optimizing Redis’s performance. Cache Hit Ratio The cache hit ratio represents the efficiency of cache usage.
It occurs when the arithmetic calculation results in a value that is way too large for the software program to handle. The impossible values should be identified and removed from the program, otherwise, they will result in error conditions. Hardware error. We focus on software so much that we forget about the hardware failures.
Only in extreme circumstances does the cost (in processor time and I-cache footprint) translate to a tangible benefit - circumstances which usually resort to hand-coded assembly anyway. Having done this before, it reminds me of CSS programming: you make a little change here and everything breaks, and you spend hours chasing your own tail.
An open-source benchmark suite for microservices and their hardware-software implications for cloud & edge systems Gan et al., The paper examines the implications of microservices at the hardware, OS and networking stack, cluster management, and application framework levels, as well as the impact of tail latency. ASPLOS’19.
In fact, according to Stack Overflow’s annual developer survey , JavaScript and Python are now the #1 and #2 most used programming languages, respectively (excluding HTML/CSS and SQL as “programming languages”). Are caches large enough for this code? Is there room for accelerators? MICRO 15 , Gope et al.,
The Solution: Distributed Caching. A widely used technology called distributed caching meets this need by storing frequently accessed data in memory on a server farm instead of within a database. It’s not enough simply to lash together a set of servers hosting a collection of in-memory caches.
The Solution: Distributed Caching. A widely used technology called distributed caching meets this need by storing frequently accessed data in memory on a server farm instead of within a database. It’s not enough simply to lash together a set of servers hosting a collection of in-memory caches.
This blog post gives a glimpse of the computer systems research papers presented at the USENIX Annual Technical Conference (ATC) 2019, with an emphasis on systems that use new hardware architectures. GAIA proposed to expand the OS page cache into accelerator memory. ATC ’19 was refreshingly different. Heterogeneous ISA.
Provides support for "unread counts", e.g. for email and chat programs. An extension to Service Workers that enables browsers to present users with cached content when offline. is access to hardware devices. This allows customisation and use of specialised features without custom, proprietary software for niche hardware.
In this particular investigation, which spanned twenty months, we suspected hardware failure, compiler bugs, linker bugs, and other possibilities. Jumping too quickly to blaming hardware or build tools is a classic mistake, but in this case the mistake was that we weren’t thinking big enough. failure rate.
Cache Merril. Companies can use technology roadmaps to review their internal IT , DevOps, infrastructure, architecture, software, internal system, and hardware procurement policies and procedures with innovation and efficiency in mind. What are the targets, timelines, and accountabilities for individual projects and programs?
I'm now program co-chair for SREcon 2023 APAC, and our 2023 conference is June 14-16 in Singapore. And now, helping bring USENIX conferences to Australia by giving the first keynote: I could not have scripted or expected it. The call for participation ends on March 2nd 23:59 SGT!
Most Intel microprocessors support “HyperThreading” (Intel’s trademark for their implementation of “simultaneous multithreading”) — which allows the hardware to support (typically) two “Logical Processors” for each physical core. leaving half of the Logical Processors idle).
Most Intel microprocessors support “HyperThreading” (Intel’s trademark for their implementation of “simultaneous multithreading”) — which allows the hardware to support (typically) two “Logical Processors” for each physical core. leaving half of the Logical Processors idle).
. …software operating on persistent data structures requires "global" pointers that remain valid after a process terminates, while hardware requires that a diverse set of devices all have the same mappings they need for bulk transfers to and from memory, and that they be able to do so for a potentially heterogeneous memory system.
It enables the user to measure database performance and make comparative judgements about database hardware and software. These factors meant that often when looking for database performance information, the results for a particular combination of software and hardware were not available. Cached vs Scaled Workloads.
using Compute Express Link or CXL), organizing memory components for optimal performance, adapting system software traditionally designed for homogeneous memory systems, and developing memory abstractions and programming constructs for HCM management. About CXL hardware availability with academia. Using emulation (e.g.
Unlike SQL queries which are declarative, such models are expressed as imperative programs heavily dependent on libraries. Maybe in time there will be a more declarative way of specifying the model rather than trying to recover it from an imperative program. ###Cross-optimisation. categorical encoding). " Query execution.
On the last morning of the conference Daniel Bittman presented some of the work being done in the context of the Twizzler OS project to explore new programming models for NVM. The starting point is a set of three asumptions for an NVM-based programming model: Compared to traditional persistent media, NVM is fast.
” This contains updated and new material that reflects the latest C++ standards and compilers, with a focus to using modern C++11/14/17 effectively on modern hardware and memory architectures. On April 25-27, I’ll be in Stockholm (Kista) giving a three-day seminar on “High-Performance and Low-Latency C++.”
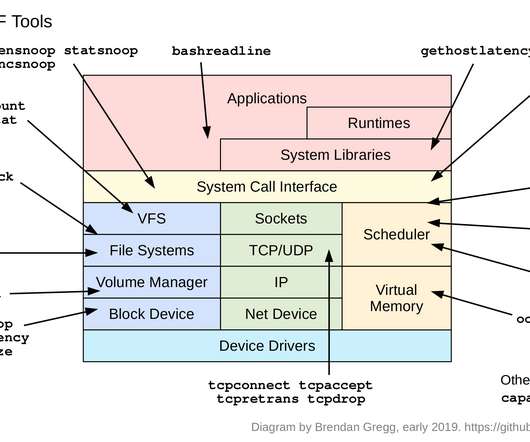
The probe specifies what events to instrument, the filter is optional and can filter down the events based on a boolean expression, and the action is the mini program that runs. The probe is BEGIN , a special probe that runs at the beginning of the program (like awk). hardwareHardware counter-based instrumentation.
According to Dr. Bandwidth, performance analysis has two recurring themes: How fast should this code (or “simple” variations on this code) run on this hardware? MPI is a commonly used standard to implement message-passing programs on computer clusters. The MPI runtime library. in ways that are seldom transparent.
According to Dr. Bandwidth, performance analysis has two recurring themes: How fast should this code (or “simple” variations on this code) run on this hardware? MPI is a commonly used standard to implement message-passing programs on computer clusters. The MPI runtime library. in ways that are seldom transparent.
It is much more difficult to publish truly risky, revolutionary research due to implicit filters in what gets funded and what makes it past a program committee. Hardware engineers design and implement solutions in RTL, while software engineers attempt to solve the problem either at the OS or application level. Discounting the Past.
When a Windows program stops pumping messages there will be ETW events emitted to indicate exactly where this happened , so those types of hangs are trivial to find. Normally running every 6 ms is enough to make a program responsive, but for some reason it wasn’t making any progress. But apparently Chrome kept on pumping messages.
A wide range of users with different operating systems, browsers, hardware configurations and other variables provides a wide sample size that helps developers discover as many issues as possible. These are often referred to as profilers and are available for all types of programming languages. What is real user monitoring (RUM)?
Stable media is commonly physical disk storage, but other devices and certain caching facilities qualify as well. Many high-end disk subsystems provide high-speed cache facilities to reduce the latency of read and write operations. This cache is often supported by a battery-powered backup facility.
In this context it means there are no external dependencies on e.g. secrets, trusted hardware modules, or special instructions (e.g. known good state of a trustworthy program). A d -degree polynomial can be evaluated in d steps in a Horner-rule program. carefully chosen computation over M and R and the nonce.
In the latest (October 2016) revision of Intel’s Instruction Extensions Programming Reference , Intel has disclosed a fairly dramatic departure from these “traditional” approaches. E.g., on Haswell you can execute two loads per cycle of any size or alignment as long as neither crosses a cache-line boundary.
Looking beyond distributed caching, it’s their ability to perform data-parallel analysis that gives IMDGs such exciting capabilities. Application developers often deploy IMDGs as a distributed cache that sits between an application and its database; the IMDG offloads ephemeral data from the database.
Looking beyond distributed caching, it’s their ability to perform data-parallel analysis that gives IMDGs such exciting capabilities. Application developers often deploy IMDGs as a distributed cache that sits between an application and its database; the IMDG offloads ephemeral data from the database.
I'm now program co-chair for SREcon 2023 APAC, and our 2023 conference is June 14-16 in Singapore. And now, helping bring USENIX conferences to Australia by giving the first keynote: I could not have scripted or expected it. It was a great privilege. The call for participation ends on March 2nd 23:59 SGT!
SQL provides a declarative programming interface, below which the system itself can figure out the most effective execution plans based on data size and statistics, layout, compute hardware etc. Be careful what you ask for (materialize). Recursive learning in SQL.
Device level flushing may have an impact on your I/O caching, read ahead or other behaviors of the storage system. FILE_FLAG_NO_BUFFERING is the Win32, CreateFile API flags and attributes setting to bypass file system cache. FILE_FLAG_NO_BUFFERING is the Win32, CreateFile API flags and attributes setting to bypass file system cache.
Edge caching. In general, Egnyte connect architecture shards and caches data at different levels based on: Amount of data. Nginx for disk based caching. We use different types of caching techniques depending on the problem statements. Disk based caching. Hybrid Sync. On prem data processing. Offline access.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content