This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Because microprocessors are so fast, computer architecture design has evolved towards adding various levels of caching between compute units and the main memory, in order to hide the latency of bringing the bits to the brains. This avoids thrashing caches too much for B and evens out the pressure on the L3 caches of the machine.
Reducing CPU Utilization to now only consume 15% of initially provisioned hardware. Missing Cache Settings – Make sure you cache resources that don’t change often on the browser or use a CDN. Too many fine-grained services leading to network and communication overhead. N+1 Query Pattern. Infrastructure Optimization.
But it’s not easy: to pull this off, VFX studios need to build and operate serious technical infrastructure (compute, storage, networking, and software licensing), otherwise known as a “ render farm.” Many shows have needs that exceed 100,000 frames, so aggregate rendering time can impact the timely delivery of a show on Netflix.
The reason is because mobile networks are, as a rule, high latency connections. only to find that the resource they’re requesting isn’t in that PoP ’s cache. Armed with this knowledge, we can soon understand why TTFB can often increase so dramatically on mobile. Routing: If you are using a CDN—and you should be!—a
This is why our BYOC pricing is less than our Dedicated Hosting pricing, as the costs listed for BYOC are only what you pay for ScaleGrid and don’t include your hardware costs. A vast majority of the features are the same, outside of these advanced features available through the BYOC model: Virtual Private Clouds / Virtual Networks.
Photo by Freepik Part of the answer is this: You have a lot of control over the design and code for the pages on your site, plus a decent amount of control over the first and middle mile of the network your pages travel over. For a myriad of reasons, older hardware can't always accommodate faster speeds. but couldn't find anything.
Effective management of memory stores with policies like LRU/LFU proactive monitoring of the replication process and advanced metrics such as cache hit ratio and persistence indicators are crucial for ensuring data integrity and optimizing Redis’s performance. Cache Hit Ratio The cache hit ratio represents the efficiency of cache usage.
The Solution: Distributed Caching. A widely used technology called distributed caching meets this need by storing frequently accessed data in memory on a server farm instead of within a database. It’s not enough simply to lash together a set of servers hosting a collection of in-memory caches.
The Solution: Distributed Caching. A widely used technology called distributed caching meets this need by storing frequently accessed data in memory on a server farm instead of within a database. It’s not enough simply to lash together a set of servers hosting a collection of in-memory caches.
Key Takeaways Distributed storage systems benefit organizations by enhancing data availability, fault tolerance, and system scalability, leading to cost savings from reduced hardware needs, energy consumption, and personnel. They maintain fault tolerance and redundancy by replicating this information throughout various nodes in the system.
The first 5G networks are now deployed and operational. The study is based on one of the world’s first commercial 5G network deployments (launched in April 2019), a 0.5 The 5G network is operating at 3.5GHz). The maximum physical layer bit-rate for the 5G network is 1200.98 The short answer is no.
Krste Asanovic from UC Berkeley kicked off the main program sharing his experience on “ Rejuvenating Computer Architecture Research with Open-Source Hardware ”. He ended the keynote with a call to action for open hardware and tools to start the next wave of computing innovation. This year’s MICRO had three inspiring keynote talks.
This paper presents Snowflake design and implementation along with a discussion on how recent changes in cloud infrastructure (emerging hardware, fine-grained billing, etc.) The caching use case may be the most familiar, but in fact it’s not the primary purpose of the ephemeral storage service. joins) during query processing.
This includes metrics such as query execution time, the number of queries executed per second, and the utilization of query cache and adaptive hash index. query cache: Disable (query_cache_size: 0, query_cache_type:OFF) innodb_adaptive_hash_index: Check adaptive hash index usage to determine its efficiency.
Defining high availability In general terms, high availability refers to the continuous operation of a system with little to no interruption to end users in the event of hardware or software failures, power outages, or other disruptions. Without enough infrastructure (physical or virtualized servers, networking, etc.),
This includes latency, which is a major determinant in evaluating the reliability and performance of your Redis instance, CPU usage to assess how much time it spends on tasks, operations such as reading/writing data from disk or network I/O, and memory utilization (also known as memory metrics).
This blog post gives a glimpse of the computer systems research papers presented at the USENIX Annual Technical Conference (ATC) 2019, with an emphasis on systems that use new hardware architectures. GAIA proposed to expand the OS page cache into accelerator memory. Heterogeneous ISA. Programmable I/O Devices.
There’s another emerging option that we didn’t talk about there: the use of far-memory , memory attached to the network that can be remotely accessed without mediation by a local processor. Processor caches can help to hide local accesses too, but not remote accesses. Clients cache the entire tree, but not the hash tables.
This includes latency, which is a major determinant in evaluating the reliability and performance of your Redis® instance, CPU usage to assess how much time it spends on tasks, operations such as reading/writing data from disk or network I/O, and memory utilization (also known as memory metrics).
ChatGPT: The InnoDB buffer pool is used by MySQL to cache frequently accessed data in memory. If we expand the cache concept more, the buffer pool could be even less if the working set (hot data) is smaller. Questions Q: I have a MySQL server with 500 GB of RAM; my data set is 100 GB. How large my InnoDB buffer pool needs to be?
The rationale behind these methods is that frontend should be able to fetch transient information very efficiently and separately from fetching of heavy-weight domain entities because this information cannot be cached. So, the only way was to cache all necessary data to minimize interaction with RDBMS. Entity Gateway.
Hardware error. We focus on software so much that we forget about the hardware failures. If the hardware gets disconnected or stops working then we cannot expect correct output from the software. Example: Printers and other hardware devices return bits of information that something is not right. Hardware issues.
Real-time network protocols for enabling videoconferencing, desktop sharing, and game streaming applications. Modern, asynchronous network APIs that dramatically improve performance in some situations. An extension to Service Workers that enables browsers to present users with cached content when offline. Delayed five years.
Make sure your system can handle next-generation DRAM,” [link] Nov 2011 - [Hruska 12] Joel Hruska, “The future of CPU scaling: Exploring options on the cutting edge,” [link] Feb 2012 - [Gregg 13] Brendan Gregg, “Blazing Performance with Flame Graphs,” [link] 2013 - [Shimpi 13] Anand Lal Shimpi, “Seagate to Ship 5TB HDD in 2014 using Shingled Magnetic (..)
Types of DBMS DBMS can be classified into hierarchical, network, relational, and object-oriented types. These can be mitigated through the implementation of: efficient query optimization caching of database queries utilization of database indexes implementation of session storage employing database read replication and sharding.
” This contains updated and new material that reflects the latest C++ standards and compilers, with a focus to using modern C++11/14/17 effectively on modern hardware and memory architectures. On April 25-27, I’ll be in Stockholm (Kista) giving a three-day seminar on “High-Performance and Low-Latency C++.”
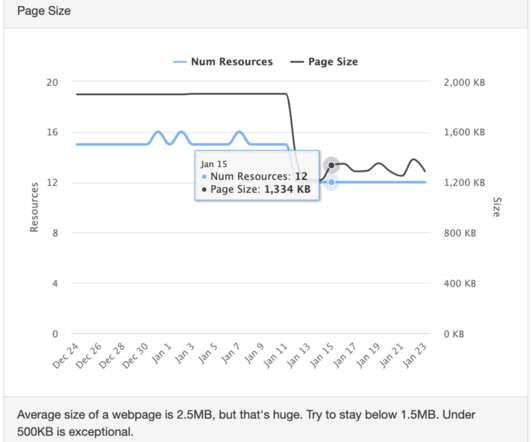
Cache-Headers missing? Lighthouse uses Chrome’s Remote Debugging Protocol to read network request information, measure JavaScript performance, observe accessibility standards and measure user-focused timing metrics like First Contentful Paint , Time to Interactive or Speed Index. After that, it’ll be mitigated by cache.
This removes the burden of purchasing and maintaining your hardware, storage and networking infrastructure, while still giving you a very familiar experience with Windows and SQL Server itself. BTW, the "i" in the Standard_E64is_v3 naming means that the instance is isolated to hardware dedicated to a single customer.
We constrain ourselves to a real-world baseline device + network configuration to measure progress. Budgets are scaled to a benchmark network & device. JavaScript is the single most expensive part of any page in ways that are a function of both network capacity and device speed. The median user is on a slow network.
The paper sets out what we can do in software given today’s hardware, and along the way also highlights areas where cooperation from hardware will be needed in the future. There are also stateless interconnects including buses and on-chip networks. Microarchitectural channels. Threat scenarios.
Gen 5 is the primary hardware option now for most regions since Gen 4 is aging out. Hyperscale achieves high performance from each compute node having SSD-based caches which helps minimize the network round trips to fetch data. New Hardware Configuration for Provisioned Compute Tier. GB per vCore.
As database performance is heavily influenced by the performance of storage, network, memory, and processors, we must understand the upper limit of these key components. For the network, we can use Iperf to assess the network bandwidth between the client and the database server to ensure it will be enough to meet our peak requirement.
Lazy-load offscreen images (reduce network contention for key resources). For low impact to First Input Delay : Avoid images causing network contention with other critical resources like CSS and JS. Device Pixel Ratio (DPR) represents how a CSS pixel is translated to physical pixels on a hardware screen. Large preview ).
According to Dr. Bandwidth, performance analysis has two recurring themes: How fast should this code (or “simple” variations on this code) run on this hardware? The user environment defines the mapping of MPI ranks to hardware resources (cores, sockets, nodes). The MPI runtime library. in ways that are seldom transparent.
According to Dr. Bandwidth, performance analysis has two recurring themes: How fast should this code (or “simple” variations on this code) run on this hardware? The user environment defines the mapping of MPI ranks to hardware resources (cores, sockets, nodes). The MPI runtime library. in ways that are seldom transparent.
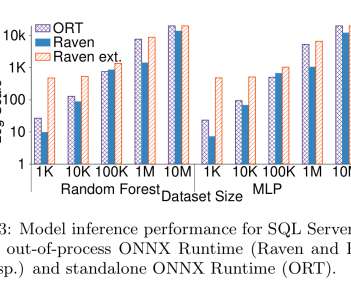
NN translation optimisations replace classical ML operators and data ‘featurizers’ with neural networks that can be executed directly in e.g. ONNX Runtime, PyTorch, or TensorFlow. " For single or very small numbers of predictions, Raven is faster due to SQL Server’s caching. " Query execution. The last word.
We wanted to have control of the hardware that runs our tests and deliver consistent results. For example, if you implement a caching plugin into your WordPress site, many of your resources will be cached, drastically improving the load time for someone coming back to your site.
When a QoS violation is predicted to occur and a culprit microservice located, Seer uses a lower level tracing infrastructure with hardware monitoring primitives to identify the reason behind the QoS violation. E.g., in memcached there are five main internal stages, each of which has a hardware or software queue associated with it.
Byte-addressable non-volatile memory,) NVM will fundamentally change the way hardware interacts, the way operating systems are designed, and the way applications operate on data. The beauty of persistent memory is that we can use memory layouts for persistent data (with some considerations for volatile caches etc. What about security?
RUM can tell you where that time is being spent, whether its network related or due to CDN or origin issues. Page was restored from back-forward cache – The bfcache essentially stores the full page in memory when navigating away from the page. We will periodically update these profiles as web performance trends change.
Apache Arrow's in-memory columnar layout is specifically optimized for data locality for better performance on modern hardware like CPUs and GPUs. In contrast, Alluxio a middleware for data access - think Alluxio storage layer as fast cache. Leveraging the recent hardware advances.
The whole point of this section is that all the algorithms above can be naturally implemented using a message passing architectural style i.e. the query execution engine can be considered as a distributed network of nodes connected by the messaging queues. It is conceptually similar to the in-stream processing pipelines. Pipelining.
Looking beyond distributed caching, it’s their ability to perform data-parallel analysis that gives IMDGs such exciting capabilities. Application developers often deploy IMDGs as a distributed cache that sits between an application and its database; the IMDG offloads ephemeral data from the database.
Looking beyond distributed caching, it’s their ability to perform data-parallel analysis that gives IMDGs such exciting capabilities. Application developers often deploy IMDGs as a distributed cache that sits between an application and its database; the IMDG offloads ephemeral data from the database.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content