This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
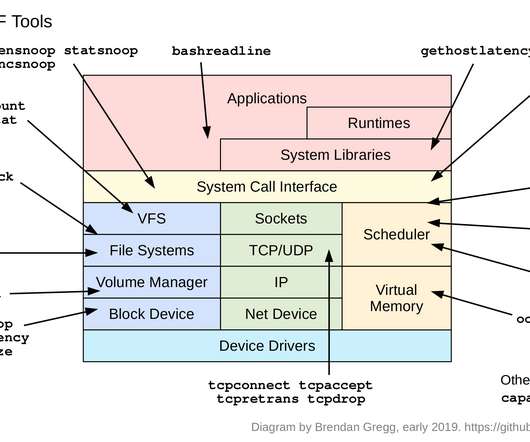
“Latency” is the duration from the execution of a load instruction (to an address that misses in all the caches), and the completion of that load instruction when the data is returned from memory. . The example below is for a 2005-era processor with 60 ns memory latency and 6.4
Because microprocessors are so fast, computer architecture design has evolved towards adding various levels of caching between compute units and the main memory, in order to hide the latency of bringing the bits to the brains. This avoids thrashing caches too much for B and evens out the pressure on the L3 caches of the machine.
The first—and often most surprising for people to learn—thing that I want to draw your attention to is that TTFB counts one whole round trip of latency. The reason is because mobile networks are, as a rule, high latency connections. only to find that the resource they’re requesting isn’t in that PoP ’s cache.
Key Takeaways Critical performance indicators such as latency, CPU usage, memory utilization, hit rate, and number of connected clients/slaves/evictions must be monitored to maintain Redis’s high throughput and low latency capabilities. It can achieve impressive performance, handling up to 50 million operations per second.
This is why our BYOC pricing is less than our Dedicated Hosting pricing, as the costs listed for BYOC are only what you pay for ScaleGrid and don’t include your hardware costs. Deploying your application and database on the same VPC also provides the lowest possible latency path. Where to host your cloud database?
Identifying key Redis metrics such as latency, CPU usage, and memory metrics is crucial for effective Redis monitoring. To monitor Redis instances effectively, collect Redis metrics focusing on cache hit ratio, memory allocated, and latency threshold.
Hardware Memory The amount of RAM to be provisioned for database servers can vary greatly depending on the size of the database and the specific requirements of the company. By caching hot datasets, indexes, and ongoing changes, InnoDB can provide faster response times and utilize disk IO in a much more optimal way. I hope this helps!
“Latency” is the duration from the execution of a load instruction (to an address that misses in all the caches), and the completion of that load instruction when the data is returned from memory. . The example below is for a 2005-era processor with 60 ns memory latency and 6.4
We are standing on the eve of the 5G era… 5G, as a monumental shift in cellular communication technology, holds tremendous potential for spurring innovations across many vertical industries, with its promised multi-Gbps speed, sub-10 ms low latency, and massive connectivity. Throughput and latency. energy consumption).
Identifying key Redis® metrics such as latency, CPU usage, and memory metrics is crucial for effective Redis monitoring. To monitor Redis® instances effectively, collect Redis metrics focusing on cache hit ratio, memory allocated, and latency threshold.
Amazon DynamoDB offers low, predictable latencies at any scale. This is not just predictability of median performance and latency, but also at the end of the distribution (the 99.9th percentile), so we could provide acceptable performance for virtually every customer. s read latency, particularly as dataset sizes grow.
Tue-Thu Apr 25-27: High-Performance and Low-Latency C++ (Stockholm). On April 25-27, I’ll be in Stockholm (Kista) giving a three-day seminar on “High-Performance and Low-Latency C++.”
Streams provide you with the underlying infrastructure to create new applications, such as continuously updated free-text search indexes, caches, or other creative extensions requiring up-to-date table changes. DynamoDB Streams enables your application to get real-time notifications of your tables’ item-level changes.
This includes metrics such as query execution time, the number of queries executed per second, and the utilization of query cache and adaptive hash index. query cache: Disable (query_cache_size: 0, query_cache_type:OFF) innodb_adaptive_hash_index: Check adaptive hash index usage to determine its efficiency.
My personal opinion is that I don't see a widespread need for more capacity given horizontal scaling and servers that can already exceed 1 Tbyte of DRAM; bandwidth is also helpful, but I'd be concerned about the increased latency for adding a hop to more memory. Ford, et al., “TCP
ChatGPT: The InnoDB buffer pool is used by MySQL to cache frequently accessed data in memory. If we expand the cache concept more, the buffer pool could be even less if the working set (hot data) is smaller. The answer does not consider the queue or latency of the sample, which could indicate a disk with issues.
The Xeon Phi x200 (Knights Landing) has a lot of modes of operation (selected at boot time), and the latency and bandwidth characteristics are slightly different for each mode. In “Cache” mode, MCDRAM memory is used as an L3 cache for the main DDR4 memory. numactl).
For most high-end processors these values have remained in the range of 75% to 85% of the peak DRAM bandwidth of the system over the past 15-20 years — an amazing accomplishment given the increase in core count (with its associated cache coherence issues), number of DRAM channels, and ever-increasing pipelining of the DRAMs themselves.
Key Takeaways Distributed storage systems benefit organizations by enhancing data availability, fault tolerance, and system scalability, leading to cost savings from reduced hardware needs, energy consumption, and personnel. By implementing data replication strategies, distributed storage systems achieve greater.
Cache-Headers missing? Estimated Input Latency. Estimated Input Latency. Service workers that will cache the bytecode result of a parsed and compiled script. After that, it’ll be mitigated by cache. It’s time to come to terms that your customers aren’t using the same powerful hardware as you. Speed Index.
There are three common mechanisms to access remote memory: modifying applications, modifying virtual memory, and hardware-level cache coherence support. even lowered the latency by introducing a multi-headed device that collapses switches and memory controllers. The recently announced CXL3.0
Gen 5 is the primary hardware option now for most regions since Gen 4 is aging out. Hyperscale achieves high performance from each compute node having SSD-based caches which helps minimize the network round trips to fetch data. New Hardware Configuration for Provisioned Compute Tier. GB per vCore.
For example, iostat(1), or a monitoring agent, may tell you your average disk latency, but not the distribution of this latency. For smaller environments, it can be of more use helping eliminate latency outliers. hardwareHardware counter-based instrumentation. Block I/O latency as a histogram.
For heavily latency-sensitive use-cases like WebXR, this is a critical component in delivering a good experience. An extension to Service Workers that enables browsers to present users with cached content when offline. is access to hardware devices. Some commenters appear to confuse unlike hardware for differences in software.
Breaking that assumption allowed Ceph to introduce a new storage backend called BlueStore with much better performance and predictability, and the ability to support the changing storage hardware landscape. But let’s take a quick look at the changing hardware landscape before we go on… The changing hardware landscape.
The paper sets out what we can do in software given today’s hardware, and along the way also highlights areas where cooperation from hardware will be needed in the future. cache) can be partitioned across domains; for those that are instead time-multiplexed, we have to flush them during domain switches. Threat scenarios.
This results in expedited query execution, reduced resource utilization, and more efficient exploitation of the available hardware resources. This reduction in latency ensures that applications and websites provide a more rapid and responsive user experience. Another highly beneficial caching method is key-value caching.
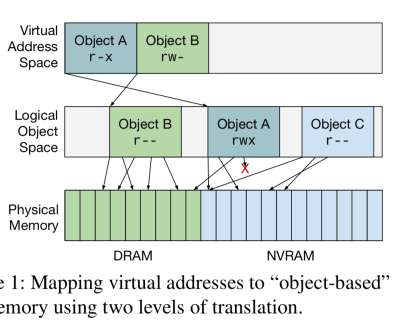
. …software operating on persistent data structures requires "global" pointers that remain valid after a process terminates, while hardware requires that a diverse set of devices all have the same mappings they need for bulk transfers to and from memory, and that they be able to do so for a potentially heterogeneous memory system.
According to Dr. Bandwidth, performance analysis has two recurring themes: How fast should this code (or “simple” variations on this code) run on this hardware? The user environment defines the mapping of MPI ranks to hardware resources (cores, sockets, nodes). The MPI runtime library. in ways that are seldom transparent.
According to Dr. Bandwidth, performance analysis has two recurring themes: How fast should this code (or “simple” variations on this code) run on this hardware? The user environment defines the mapping of MPI ranks to hardware resources (cores, sockets, nodes). The MPI runtime library. in ways that are seldom transparent.
Last time around we looked at the DeathStarBench suite of microservices-based benchmark applications and learned that microservices systems can be especially latency sensitive, and that hotspots can propagate through a microservices architecture in interesting ways. on end-to-end latency) and less than 0.15% on throughput.
Byte-addressable non-volatile memory,) NVM will fundamentally change the way hardware interacts, the way operating systems are designed, and the way applications operate on data. Therefore any programming abstraction must be low latency and the kernel needs to be kept off the path of persistent data access as much as possible.
It offers reliability and performance of a data warehouse, real-time and low-latency characteristics of a streaming system, and scale and cost-efficiency of a data lake. Apache Arrow's in-memory columnar layout is specifically optimized for data locality for better performance on modern hardware like CPUs and GPUs.
It simulates a link with a 400ms RTT and 400-600Kbps of throughput (plus latency variability and simulated packet loss). Simulated packet loss and variable latency, however, can make benchmarking extremely difficult and slow. Our baseline, then, should probably trade lower throughput/higher-latency for packet loss.
My personal opinion is that I don't see a widespread need for more capacity given horizontal scaling and servers that can already exceed 1 Tbyte of DRAM; bandwidth is also helpful, but I'd be concerned about the increased latency for adding a hop to more memory. Ford, et al., “TCP
These cores have 2 functional units supporting Vector Fused Multiply-Add instructions, with 5-cycle latency on Haswell/Broadwell and 4-cycle latency on Skylake processors (ref: [link] ). With 2 FMA units that have 5-cycle latency, the code must implement at least 2*5=10 independent accumulators in order to avoid stalls.
The ability of a datacenter to handle traffic changes over time as capacity is added or removed, and hardware upgraded The routing needs to be able to tolerate failures without making the situation worse. Sharing is caring caching. For example, balance utilisation across all data centers, or optimise for network latency.
Stable media is commonly physical disk storage, but other devices and certain caching facilities qualify as well. Many high-end disk subsystems provide high-speed cache facilities to reduce the latency of read and write operations. This cache is often supported by a battery-powered backup facility.
Using an image CDN, such as KeyCDN, can significantly reduce the latency of your image delivery. This is crucial due to mobile devices requiring additional optimizations because they typically have less powerful hardware and a slower network connection when compared to desktop devices. Mbps ( Opensignal ).
This system has been designed to supplement and succeed the existing Hadoop-based system that had too high latency of data processing and too high maintenance costs. In many cases join is performed on a finite time window or other type of buffer e.g. LFU cache that contains most frequent tuples in the stream.
A quick canary test was free of errors and showed lower latency, which is expected given that our standard canary setup routes an equal amount of traffic to both the baseline running on 4xl and the canary on 12xl. What’s worse, average latency degraded by more than 50%, with both CPU and latency patterns becoming more “choppy.”
For most high-end processors these values have remained in the range of 75% to 85% of the peak DRAM bandwidth of the system over the past 15-20 years — an amazing accomplishment given the increase in core count (with its associated cache coherence issues), number of DRAM channels, and ever-increasing pipelining of the DRAMs themselves.
The first effect is that the FP4 model weights are 4bits rather than 8bits, so they are half the size, and that means they load twice as fast, with better cache hit rates for the same number of model parameters. These line up much better with what Id expect from the hardware capabilities. The comparisons Ive labeled are 5.3x
The CFQ works well for many general use cases but lacks latency guarantees. The deadline excels at latency-sensitive use cases ( like databases ), and noop is closer to no schedule at all. Make sure the drives are mounted with noatime and also if the drives are behind a RAID controller with appropriate battery-backed cache.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content