This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
By: Rajiv Shringi , Oleksii Tkachuk , Kartik Sathyanarayanan Introduction In our previous blog post, we introduced Netflix’s TimeSeries Abstraction , a distributed service designed to store and query large volumes of temporal event data with low millisecond latencies. Today, we’re excited to present the Distributed Counter Abstraction.
We introduce a caching mechanism in the API gateway layer, allowing us to offload processing from singleton leader elected controllers without giving up strict data consistency and guarantees clients observe. When a new leader is elected it loads all data from external storage. The cache is kept in sync with the current leader process.
How To Design For High-Traffic Events And Prevent Your Website From Crashing How To Design For High-Traffic Events And Prevent Your Website From Crashing Saad Khan 2025-01-07T14:00:00+00:00 2025-01-07T22:04:48+00:00 This article is sponsored by Cloudways Product launches and sales typically attract large volumes of traffic.
This means you no longer have to provision, scale, and maintain servers to run your applications, databases, and storage systems. Speed is next; serverless solutions are quick to spin up or down as needed, and there are no delays due to limited storage or resource access. AWS offers four serverless offerings for storage.
Firstly, the synchronous process which is responsible for uploading image content on file storage, persisting the media metadata in graph data-storage, returning the confirmation message to the user and triggering the process to update the user activity. Fetching User Feed. Sample Queries supported by Graph Database. Optimization.
While Atlas is architected around compute & storage separation, and we could theoretically just scale the query layer to meet the increased query demand, every query, regardless of its type, has a data component that needs to be pushed down to the storage layer.
Our goal was to build a versatile and efficient data storage solution that could handle a wide variety of use cases, ranging from the simplest hashmaps to more complex data structures, all while ensuring high availability, tunable consistency, and low latency. For simpler use cases, it also represents flat key-value Maps (e.g.
Building on these foundational abstractions, we developed the TimeSeries Abstraction — a versatile and scalable solution designed to efficiently store and query large volumes of temporal event data with low millisecond latencies, all in a cost-effective manner across various use cases. For example: {“device_type”: “ios”}.
MongoDB offers several storage engines that cater to various use cases. The default storage engine in earlier versions was MMAPv1, which utilized memory-mapped files and document-level locking. The newer, pluggable storage engine, WiredTiger, addresses this by using prefix compression, collection-level locking, and row-based storage.
Of the organizations in the Kubernetes survey, 71% run databases and caches in Kubernetes, representing a +48% year-over-year increase. Together with messaging systems (+36% growth), organizations are increasingly using databases and caches to persist application workload states.
Think of a session replay like a movie based on real events. These changes are known as “events,” and they occur any time a user interacts with your site or application, such as when they swipe the screen, move the mouse or input text. Streamlined asset caching: Asset caching is critical for creating accurate replays.
The other main use case was RENO, the Rapid Event Notification System mentioned above. KeyValue is an abstraction over the storage engine itself, which allows us to choose the best storage engine that meets our SLO needs. These events, sent over a Kafka topic, let the service keep track of the device list for a given account.
Dynatrace AutomationEngine workflows automate release validation using AWS Well-Architected pillars With Dynatrace, you can create workflows that automate various tasks based on events, schedules or Davis problem triggers. Workflows are powered by a core platform technology of Dynatrace called the AutomationEngine.
The more indexes, the more the requirement of memory for effective caching. Indexes need more cache than tables Due to random writes and reads, indexes need more pages to be in the cache. Cache requirements for indexes are generally much higher than associated tables. This helps in crash recovery and replication.
The data is incredibly plentiful and difficult to store over long periods due to capacity limitations — a reason why private and public cloud storage services have been a boon to DevOps teams. Logs are important because you’ll naturally want an event-based record of any notable anomalies across the system.
Key Takeaways Redis offers complex data structures and additional features for versatile data handling, while Memcached excels in simplicity with a fast, multi-threaded architecture for basic caching needs. Redis is better suited for complex data models, and Memcached is better suited for high-throughput, string-based caching scenarios.
In this approach, we record the requests and responses for the service that needs to be updated or replaced to an offline event stream asynchronously. Given the scale of the data being generated using replay traffic, we record the responses from the two sides to a cost-effective cold storage facility using technology like Apache Iceberg.
The benefits of modeling data as events as a mechanism to evolve our software systems. Enter streams of events, specifically the kinds of streams that technology like Kafka makes possible. Continue reading Microservices, events, and upside-down databases. The concepts may well seem odd at first, but stick with them.
The service workers enable the offline usage of the PWA by fetching cached data or informing the user about the absence of an Internet connection. When developing a PWA, you can cache the application shell’s resources and assets in the browser. Cached content with IndexedDB. Cache first, then network. Service Workers.
PostgreSQL & Elastic for data storage. REDIS for caching. In the event that there’s a problem, Dynatrace will automatically highlight the hotspot and root cause in the different Dynatrace views. Their technology stack looks like this: Spring Boot-based Microservices. NGINX as an API Gateway. 3 Log Analytics.
At Grid Dynamics, we recently faced a necessity to build an in-stream data processing system that aimed to crunch about 8 billion events daily providing fault-tolerance and strict transactioanlity i.e. none of these events can be lost or duplicated. The signature is initially initialized by the event ID. Lineage Tracking.
The most obvious and common way this happens is when companies try to evolve their caches into a data platform that can, for example, be used as highly available enterprise key-value stores for volatile data. Let’s look at a typical scenario involving the javax cache API, also known as JSR107. How hard can it be?
The DBMS is key to maintaining these aspects by offering a storage system that allows users to perform operations such as data insertion, deletion, and selection, thereby promoting enhanced data integration across diverse applications and platforms.
While caching continues to be a dominant use of ElastiCache for Redis, we see customers increasingly use it as an in-memory NoSQL database. It enables customers to run their Redis nodes at higher memory utilization without risking swap usage during events such as snapshotting and replica synchronization.
The first signal is the input events. UIforETW contains an integrated input logger (anonymized enough so that I don’t accidentally steal passwords or personal information) so I could just drill down to the MouseUp events with a Button Type of 2, which represents the right mouse button. That is an average read of 68 bytes each time.
As a production system within Microsoft capturing around a quadrillion events and indexing 16 trillion search keys per day it would be interesting in its own right, but there’s a lot more to it than that. On the surface this is a paper about fast data ingestion from high-volume streams, with indexing to support efficient querying.
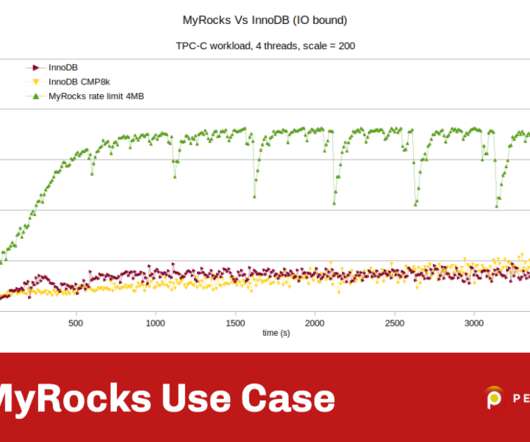
I wrote this post on MyRocks because I believe it is the most interesting new MySQL storage engine to have appeared over the last few years. I decided to use a virtual machine with two CPU cores, four GB of memory, and storage limited to a maximum of 1000 IOPs of 16KB. I emulated these limits using the KVM iotune settings in my lab. <iotune>
Coupled with stateless application servers to execute business logic and a database-like system to provide persistent storage, they form a core component of popular data center service archictectures. Oh, you mean a cache? Yes, a bit like those 2nd-level caches we were talking about earlier, e.g. Ehcache from 2003 onwards.
percent availability in the event of a server, a rack of servers, or an Availability Zone failure. In addition, DynamoDB Accelerator (DAX) a fully managed, highly available, in-memory cache further speeds up DynamoDB response times from milliseconds to microseconds and can continue to do so at millions of requests per second.
Defining high availability In general terms, high availability refers to the continuous operation of a system with little to no interruption to end users in the event of hardware or software failures, power outages, or other disruptions. Redundancy is also critical for disaster recovery. there cannot be high availability.
More importantly, UDM utilizes a single storage backend with benefits of multiple storage systems which avoids moving data across systems hence data duplication, and data consistency issues. Delta implements the unified data management layer by extending the Amazon S3 object storage for ACID transactions and automatic data indexing.
Guest profiles also start with empty caches, empty cookie stores, empty browser storage, etc. These may get populated during testing, but we can clear them at any time via Application > Storage > Clear Site Data in DevTools. Even though I only clicked on the page once, multiple event handlers were invoked.
It assists in identifying where important events happened during the loading process. Waterfall charts within the Dotcom-Monitor platform can help users identify where important events happened during the page load process. Moreover, caching utility may decrease the waiting time. Queued request. What’s the Difference?
We can use 11ty’s new Serverless mode to build them on request using Netlify’s On-Demand Builders to cache each Madlib. For example, an “On-Demand Builder” is a serverless function dedicated to serving a cached file. Netlify then caches that page on its edge CDN for each additional call. Large preview ). More after jump!
It assists in identifying where important events happened during the loading process. Waterfall charts within the Dotcom-Monitor platform can help users identify where important events happened during the page load process. Moreover, caching utility may decrease the waiting time. Queued request. What’s the Difference?
On the contrary, a native application of an e-commerce store can come at 30, 50, or even 100 MB and up, consuming internal device storage. Due to the use of modern frameworks, advanced caching and rendering, and data transmission via API, properly developed PWAs can be a seven-league step up to boost the store’s speed. Large preview ).
Chrome has missed several APIs for 3+ years: Storage Access API. Pointer Events. An extension to Service Workers that enables browsers to present users with cached content when offline. A-series chips have run circles around other ARM parts for more than half a decade, largely through gobsmacking amounts of L2/L3 cache per core.
CLS , or Cumulative Layout Shift, tracks how elements move or shift on the page absent of actions like a keyboard or click event. Lighthouse also caught a cache misconfiguration that prevented some of our static assets from being served from our CDN. A summary of LCP, FID and CLS. The first easy win came from an experimental Next.js
Cached vs Scaled Workloads. A key difference between cached and scaled workloads is the implementation of keying and thinking time to introduce a pause of time between transactions. Note that HammerDB can also implement a scaled workload with a feature called event-driven scaling.
It is entirely built upon various sets of instruments (also can be called event names) each serving different purposes. Stage – Instrument starting with ‘stage’ provides the execution stage of any query like reading data, sending data, altering table, checking query cache for queries, etc. For example stage/sql/altering table.
The Debug channel Extended Event fastloadcontext_enabled can be used to monitor FastLoadContext usage per index partition (rowset). This event does not fire for RowsetBulk loads. GO. -- Clear the plan cache. GO. -- Clear the plan cache. GO. -- Clear the plan cache. Mixed logging. NULL , -- Partition ID. INSERT dbo.
The SQL Server batch mode implementation of a Bloom filter is optimized for modern CPU cache architectures and is known internally as a complex bitmap. The optimization can be monitored with the extended event column_store_expression_filter_bitmap_set. Extended Events and Trace Flags. Bitmap Choice. Final Thoughts.
As a MongoDB user, it’s crucial to ensure that your data is safe and secure in the event of a disaster or system failure. The speed of backup also depends on allocated IOPS and type of storage since lots of read/writes would be happening during this process. Why are MongoDB database backups important? mongodump --host=mongodb1.example.net
The modifications persist even in the event of a system failure. Stable Media Stable media is often confused with physical storage. SQL Server defines stable media as storage that can survive system restart or common failure. This cache is often supported by a battery-powered backup facility.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content