This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
“Latency” is the duration from the execution of a load instruction (to an address that misses in all the caches), and the completion of that load instruction when the data is returned from memory. GB/s peak DRAM bandwidth, requiring 6 concurrent 64-byte cache line accesses to be pending at all times to maintain full bandwidth.
Because microprocessors are so fast, computer architecture design has evolved towards adding various levels of caching between compute units and the main memory, in order to hide the latency of bringing the bits to the brains. This avoids thrashing caches too much for B and evens out the pressure on the L3 caches of the machine.
On-premises data centers invest in higher capacity servers since they provide more flexibility in the long run, while the procurement price of hardware is only one of many cost factors. Of the organizations in the Kubernetes survey, 71% run databases and caches in Kubernetes, representing a +48% year-over-year increase.
Instead of worrying about infrastructure management functions, such as capacity provisioning and hardware maintenance, teams can focus on application design, deployment, and delivery. Enhancing event ingestion. Serverless architecture offers several benefits for enterprises. Simplicity. The first benefit is simplicity. Data Store.
And while these events are a great opportunity for us Dynatracers to share our thoughts with our users, it’s also an amazing opportunity to for us to learn from our users about how they use Dynatrace to optimize digital experiences and digital operations in both the public and private sector. Dynatrace news. APAC Series.
Streams provide you with the underlying infrastructure to create new applications, such as continuously updated free-text search indexes, caches, or other creative extensions requiring up-to-date table changes. Triggers are powerful mechanisms that react to events dynamically and in real time.
The percentage in degradation will vary depending on many factors {hardware, workload, number of tables, configuration, etc.}. having to open each table.frm (and in which my test runs, I have purposely read a very high number of tables compared to “Table-open-cache” variable).
Only in extreme circumstances does the cost (in processor time and I-cache footprint) translate to a tangible benefit - circumstances which usually resort to hand-coded assembly anyway. It shouldn't be 10%, unless it's cache effects. And for leaf routines (which never establish a frame), this is a non-issue.
Defining high availability In general terms, high availability refers to the continuous operation of a system with little to no interruption to end users in the event of hardware or software failures, power outages, or other disruptions. Redundancy is also critical for disaster recovery.
At Grid Dynamics, we recently faced a necessity to build an in-stream data processing system that aimed to crunch about 8 billion events daily providing fault-tolerance and strict transactioanlity i.e. none of these events can be lost or duplicated. The signature is initially initialized by the event ID. Lineage Tracking.
This paper is all about the design of efficient data structures for far-memory, which turns out to have consequences reaching all the way down to the hardware. A far memory data structure has: far data in far memory, containing the core content of the data structure data caches at clients algorithms for operations. Refreshable vectors.
Most Intel microprocessors support “HyperThreading” (Intel’s trademark for their implementation of “simultaneous multithreading”) — which allows the hardware to support (typically) two “Logical Processors” for each physical core. leaving half of the Logical Processors idle).
Most Intel microprocessors support “HyperThreading” (Intel’s trademark for their implementation of “simultaneous multithreading”) — which allows the hardware to support (typically) two “Logical Processors” for each physical core. leaving half of the Logical Processors idle).
Pointer Events. An extension to Service Workers that enables browsers to present users with cached content when offline. is access to hardware devices. This allows customisation and use of specialised features without custom, proprietary software for niche hardware. It was delayed by iOS for five years. Content Indexing.
Data backup and recovery in a DBMS encompass a series of procedures that enable users to generate data backups as a precautionary measure and restore data in the event of data loss, corruption, or system failures. By implementing data abstraction techniques, these challenges can be addressed more effectively.
“Latency” is the duration from the execution of a load instruction (to an address that misses in all the caches), and the completion of that load instruction when the data is returned from memory. GB/s peak DRAM bandwidth, requiring 6 concurrent 64-byte cache line accesses to be pending at all times to maintain full bandwidth.
I don’t get to Europe very often apart from ISO C++ standards meetings, but this spring I’ve been able to accept invitations for two English-language European events in the last week of April. If you’re interested in attending, please check out the links, and I look forward to meeting and re-meeting many of you there.
It enables the user to measure database performance and make comparative judgements about database hardware and software. These factors meant that often when looking for database performance information, the results for a particular combination of software and hardware were not available. Cached vs Scaled Workloads.
Apache Arrow's in-memory columnar layout is specifically optimized for data locality for better performance on modern hardware like CPUs and GPUs. In contrast, Alluxio a middleware for data access - think Alluxio storage layer as fast cache. Event-driven data flow architecture. Leveraging the recent hardware advances.
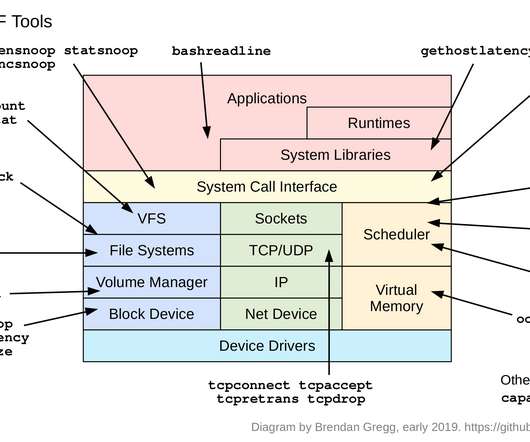
bpftrace is suited for this kind of analysis: decomposing metrics into distributions or per-event logs, and creating new metrics for visibility into blind spots. This example instrumented one of many thousands of available events. software Kernel software-based events. hardwareHardware counter-based instrumentation.
The modifications persist even in the event of a system failure. Stable media is commonly physical disk storage, but other devices and certain caching facilities qualify as well. Many high-end disk subsystems provide high-speed cache facilities to reduce the latency of read and write operations.
When a QoS violation is predicted to occur and a culprit microservice located, Seer uses a lower level tracing infrastructure with hardware monitoring primitives to identify the reason behind the QoS violation. E.g., in memcached there are five main internal stages, each of which has a hardware or software queue associated with it.
When a Windows program stops pumping messages there will be ETW events emitted to indicate exactly where this happened , so those types of hangs are trivial to find. The CFG memory block is best thought of a cache with bounded size. I loaded it into Windows Performance Analyzer (WPA), but I couldn’t definitively find the hang.
Could it be Analyzing efficient stream processing on modern hardware ? On one of the themes that captures my imagination, how changing hardware platform influence system design: Rethinking database high availability with RDMA networks. What’s their secret??? What if the network was no longer the bottleneck?
For this page to be done loading it needs to be responsive to user input — the “interactive” in “Time to Interactive” Browsers process user input by generating DOM events that application code listens to. This input processing happens on document’s main thread , where JavaScript runs.
An example of a specification is the correct operation of the hardware of a microprocessor. An SDC is the worst possible outcome of a fault, as it can have an arbitrary impact on the correctness of software running on the hardware. Background A fault is a condition that causes the inability to meet a specification.
If you need greater precision, use the query_thread_profile extended event, which reports in microseconds. The output from this event for the execution plan shown above is: This shows elapsed time for the join (node 2) is 701,465µs (truncated to 701ms in showplan). Total elapsed time is 933ms with 6,673ms of CPU time with a warm cache.
We turned to JVM-specific profiling, starting with the basic hotspot stats, and then switching to more detailed JFR (Java Flight Recorder) captures to compare the distribution of the events. We also see much higher L1 cache activity combined with 4x higher count of MACHINE_CLEARS. Cache line is a concept similar to memory page?—?
Device level flushing may have an impact on your I/O caching, read ahead or other behaviors of the storage system. FILE_FLAG_NO_BUFFERING is the Win32, CreateFile API flags and attributes setting to bypass file system cache. FILE_FLAG_NO_BUFFERING is the Win32, CreateFile API flags and attributes setting to bypass file system cache.
An open-source benchmark suite for microservices and their hardware-software implications for cloud & edge systems Gan et al., The paper examines the implications of microservices at the hardware, OS and networking stack, cluster management, and application framework levels, as well as the impact of tail latency. ASPLOS’19.
Are caches large enough for this code? Can we do something to optimize giant event loops running bytecode interpreters at the architecture level (perhaps by revisiting ideas from long ago)? There’s some work on hardware proposals for these systems, like Zhu et al., What about branch prediction tables?
Plus a service worker that caches all static assets and serves them for repeat views, along with cached versions of articles that a reader has already visited. The reasons for it are numerous, but the most important one is a huge difference in network conditions and device hardware across the world. KB, Brotlified).
The vast majority of climate scientists attribute the increasing ferocity and frequency of extreme weather events around the world to climate change, which they largely attribute to human activity. how much data does the browser have to download to display your website) and resource usage of the hardware serving and receiving the website.
Build Optimizations JavaScript modules, module/nomodule pattern, tree-shaking, code-splitting, scope-hoisting, Webpack, differential serving, web worker, WebAssembly, JavaScript bundles, React, SPA, partial hydration, import on interaction, 3rd-parties, cache. This knowledge will give you the best optimization target for ongoing efforts.
In the end, it’s not the load events or server response times that define the experience, but the perception of how snappy the interface feels. Custom metrics measure a particular, custom event for the user, e.g. Twitter’s Time To First Tweet and Pinterest’s PinnerWaitTime. What does it mean?
Custom metrics measure a particular, custom event for the user, e.g. Twitter’s Time To First Tweet and Pinterest’s PinnerWaitTime. For that one, you can monitor Hero Rendering Times , or use Performance API , marking particular timestaps for events that are important for your business. Image credit: Addy Osmani ) ( Large preview ).
Edge caching. In general, Egnyte connect architecture shards and caches data at different levels based on: Amount of data. Nginx for disk based caching. CFS(cloud file system), EOS (Egnyte object store), Content Security, Event Sync, Search Service, User behavior based recommendation service form major parts of the system.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




































Let's personalize your content