This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
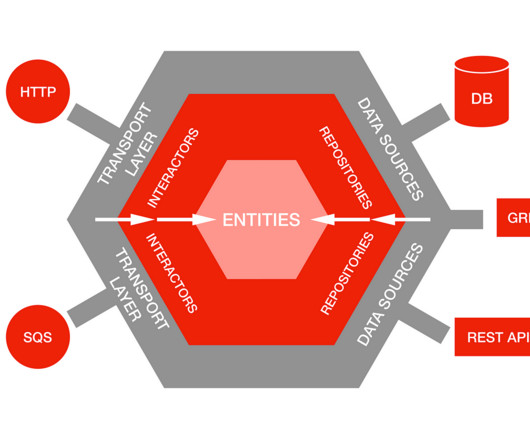
By: Rajiv Shringi , Oleksii Tkachuk , Kartik Sathyanarayanan Introduction In our previous blog post, we introduced Netflix’s TimeSeries Abstraction , a distributed service designed to store and query large volumes of temporal event data with low millisecond latencies. Today, we’re excited to present the Distributed Counter Abstraction.
We introduce a caching mechanism in the API gateway layer, allowing us to offload processing from singleton leader elected controllers without giving up strict data consistency and guarantees clients observe. The cache is kept in sync with the current leader process. How do I know that my cache is up to date? of the data.
How To Design For High-Traffic Events And Prevent Your Website From Crashing How To Design For High-Traffic Events And Prevent Your Website From Crashing Saad Khan 2025-01-07T14:00:00+00:00 2025-01-07T22:04:48+00:00 This article is sponsored by Cloudways Product launches and sales typically attract large volumes of traffic.
Data-driven applications span a wide breadth of complexity, from simple microservices to real-time event-driven systems under significant load. Guest post by Ben Hagan from PolyScale.ai However, as any development and/or DevOps team tasked with performance improvements will attest, making data-driven apps fast globally is “non-trivial”.
We turned to JVM-specific profiling, starting with the basic hotspot stats, and then switching to more detailed JFR (Java Flight Recorder) captures to compare the distribution of the events. We also see much higher L1 cache activity combined with 4x higher count of MACHINE_CLEARS. Cache line is a concept similar to memory page?—?
To harness this data effectively, we employ a process of interaction tokenization, ensuring meaningful events are identified and redundancies are minimized. Even with such strategies, interaction histories from active users can span thousands of events, exceeding the capacity of transformer models with standard self attention layers.
Because microprocessors are so fast, computer architecture design has evolved towards adding various levels of caching between compute units and the main memory, in order to hide the latency of bringing the bits to the brains. This avoids thrashing caches too much for B and evens out the pressure on the L3 caches of the machine.
Honestly, in this scenario, my advice is almost always: don’t bother trying to retrofit Critical CSS—just hash-n-cache 1 2 the living daylights out of your existing CSS bundles until you replatform and do it differently next time. In effect, CSS is applied around the DOMContentLoaded event. How do we automate it? That’s kinda late.
Performance Game Changer: Browser Back/Forward Cache. Performance Game Changer: Browser Back/Forward Cache. With that caveat out of the way, let’s get to the guts of the article: What is the Back/Forward Cache and why does it matter so much? Didn’t The HTTP Cache Do All That Anyway? Barry Pollard.
For instance, you can use a Config to define a default value for a parameter which can be overridden by a real-time event as a run is triggered. this could take a few minutes) All packages already cached in s3. All environments already cached in s3. training.mP4eIStG.yaml run --prediction_date20241006 Metaflow 2.12.39+nflxfastdata(2.13.5);nflx(2.13.5);metaboost(0.0.27)
“Latency” is the duration from the execution of a load instruction (to an address that misses in all the caches), and the completion of that load instruction when the data is returned from memory. GB/s peak DRAM bandwidth, requiring 6 concurrent 64-byte cache line accesses to be pending at all times to maintain full bandwidth.
Of the organizations in the Kubernetes survey, 71% run databases and caches in Kubernetes, representing a +48% year-over-year increase. Together with messaging systems (+36% growth), organizations are increasingly using databases and caches to persist application workload states.
Depending on how it is configured, Redis can act like a database, a cache or a message broker. Session Cache: Many websites leverage Redis Strings to create a session cache to speed up their website experience by caching HTML fragments or pages. It’s important to note that Redis is a NoSQL database system. Redis Sets.
Amazon compute solutions are designed to streamline resource provisioning and container management with two services: AWS Lambda : Lambda provides serverless compute infrastructure that lets you run code in response to predetermined events or conditions and automatically manage all compute resources required for these processes. Data Store.
Moreover, common database optimizations like caching recently queried data don’t really work for alerting queries because, generally speaking, the last received datapoint is required for correctness. It became clear to us that we needed to solve the scalability problem with a fundamentally different approach.
The entity C denotes the event where a user likes a post and entity D denotes the action when a user follows another user. We will use a cache having an LRU based eviction policy for caching user feeds of active users. Subsequently, the data entities C and D denote the different actions which users may take. Optimization.
The Tech Hollow , an OSS technology we released a few years ago, has been best described as a total high-density near cache : Total : The entire dataset is cached on each node?—?there there is no eviction policy, and there are no cache misses. Near : the cache exists in RAM on any instance which requires access to the dataset.
The GraphQL shim enabled client engineers to move quickly onto GraphQL, figure out client-side concerns like cache normalization, experiment with different GraphQL clients, and investigate client performance without being blocked by server-side migrations. To launch Phase 1 safely, we used AB Testing.
Building on these foundational abstractions, we developed the TimeSeries Abstraction — a versatile and scalable solution designed to efficiently store and query large volumes of temporal event data with low millisecond latencies, all in a cost-effective manner across various use cases. For example: {“device_type”: “ios”}.
Streams provide you with the underlying infrastructure to create new applications, such as continuously updated free-text search indexes, caches, or other creative extensions requiring up-to-date table changes. Triggers are powerful mechanisms that react to events dynamically and in real time.
Browsers will cache tools popular among vocal, leading-edge developers. There's plenty of space for caching most popular frameworks. The best available proxy data also suggests that shared caches would have a minimal positive effect on performance. Browsers now understand the classic shared HTTP cache behaviour as a privacy bug.
The RAG process begins by summarizing and converting user prompts into queries that are sent to a search platform that uses semantic similarities to find relevant data in vector databases, semantic caches, or other online data sources.
While you can look at what's in cache through the DMVs to see the queries there, you don't get any real history and you don't get any detail of when the executions occurred. If you really want a detailed analysis of which query used the most CPU, you need to first set up an Extended Events session and then consume that data.
Interestingly, 304 responses are still a form of redirect: the server is redirecting your visitor back to their HTTP cache. Ensure you aren’t wastefully revalidating still-fresh resources : These files were revalidated for a repeat page view as they all carried Cache-Control: public, max-age=0, must-revalidate.
Best of all, our page can load much faster since everything is cached in Elasticsearch. Luckily, we have Kafka events that are emitted each time a piece of data changes. The first step is to listen to those events and act accordingly. Keeping Everything Up To Date Indexing the data once isn’t enough.
HashMap<String, SortedMap<Bytes, Bytes>> For complex data models such as structured Records or time-ordered Events, this two-level approach handles hierarchical structures effectively, allowing related data to be retrieved together. This model supports both simple and complex data models, balancing flexibility and efficiency.
TenantCache: a cache to store tenant information and API token information and semi-permanent data to avoid unnecessary roundtrips. ? These API tokens are then stored in a local cache (the TenantCache using Redis), alongside with other rather static information of the environments: ? tenant-token the current API token to use.
After identifying about 100 idle host instances to be shut down, they learned that these hosts were provisioned in anticipation of upscaling to support an upcoming major sales event. Implement appropriate caching layers (for example, read-only cache for static data). Reduce inter-process communications overhead.
The other main use case was RENO, the Rapid Event Notification System mentioned above. This also enables things like subscribing to device events to know when another device comes online and when they’re available to pair or send a message to. A basic order of events for a device to device message.
To do so Netflix’s design required: An event based mechanism that could ingest information about application autoscaling groups. Over time, each node caches a subset of subproblems to support a distributed cache, reduce the datastore load, and achieve SpiceDB’s horizontal scalability.
Think of a session replay like a movie based on real events. These changes are known as “events,” and they occur any time a user interacts with your site or application, such as when they swipe the screen, move the mouse or input text. Streamlined asset caching: Asset caching is critical for creating accurate replays.
Explainer flow is event-triggered by an upstream flow, such Model A, B, C flows in the illustration. A hugely important detail that often goes overlooked is event-triggering : it allows a team to integrate their Metaflow flows to surrounding systems upstream (e.g. ETL workflows), as well as downstream (e.g.
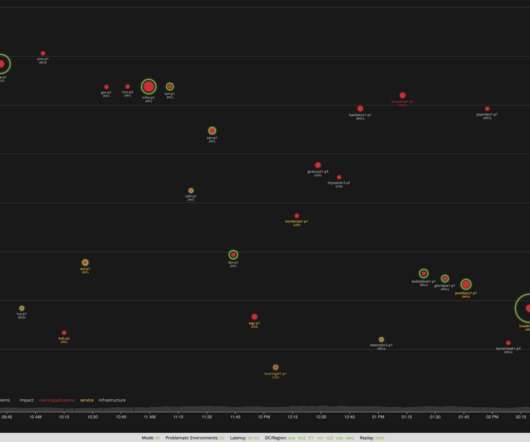
And while these events are a great opportunity for us Dynatracers to share our thoughts with our users, it’s also an amazing opportunity to for us to learn from our users about how they use Dynatrace to optimize digital experiences and digital operations in both the public and private sector. Dynatrace news. APAC Series.
The browser receives a JavaScript bundle and static HTML in a payload, then it will render the DOM and add the listeners and events triggers for reactiveness. Active Memory Caching. When you want to get data that you already had quickly, you need to do caching — caching stores data that a user recently retrieved.
Improving each of these should hopefully chip away at the timings of more granular events that precede the LCP milestone, but whenever we’re making these kinds of indirect optimisation, we need to think much more carefully about how we measure and benchmark ourselves as we work.
Lambda then takes a snapshot of the memory and disk state of the initialized execution environment, persists the encrypted snapshot, and caches it for low-latency access. Saving your cloud operations and site reliability engineering teams hours of guesswork and manual tagging, the Davis AI engine analyzes billions of events in real time.
Often the data is held in memory by consumers and used as a “total cache”, where it is accessed at runtime by client code and atomically swapped out under the hood. for example Open Connect Appliance cache configuration, supported device type IDs, supported payment method metadata, and A/B test configuration.
Dynatrace AutomationEngine workflows automate release validation using AWS Well-Architected pillars With Dynatrace, you can create workflows that automate various tasks based on events, schedules or Davis problem triggers. Workflows are powered by a core platform technology of Dynatrace called the AutomationEngine.
In the unlikely event that you don’t have access to the CSS file that contains the @import. We’re bound to an inefficient caching strategy: a change to, say, the background colour of the currently-selected day on a date picker used on only one page, would require that we cache-bust the entirety of app.css. in your HTML.
The benefits of modeling data as events as a mechanism to evolve our software systems. Enter streams of events, specifically the kinds of streams that technology like Kafka makes possible. Continue reading Microservices, events, and upside-down databases. The concepts may well seem odd at first, but stick with them.
In databases like MySQL and PostgreSQL, transaction logs are the source of CDC events. Some of DBLog’s features are: Processes captured log events in-order. Interleaves log with dump events, by taking dumps in chunks. Hence, downstream consumers have confidence to receive change events as they occur on a source.
To fix this, we've improved support for React Server Components (RSC) and added prefetch helpers to make it easier to utilize the power of RSCs running exclusively on the server, in combination with the highly dynamic client-side cache of React Query. query (() => '.' ), }, // Equivalent of: nested2: router ({ proc: publicProcedure.
The service workers enable the offline usage of the PWA by fetching cached data or informing the user about the absence of an Internet connection. When developing a PWA, you can cache the application shell’s resources and assets in the browser. Cached content with IndexedDB. Cache first, then network. Service Workers.
When Davis detects deviations from this baseline (for example, a sudden dip in usage or a user action that lasts longer than expected), it generates a problem event , identifies the root cause of the problem, and sends notifications based on the configured alerting profile. User actions in Dynatrace are more than just simple events.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content