This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
After selecting a mode, users can interact with APIs without needing to worry about the underlying storage mechanisms and counting methods. Best Effort Regional Counter This type of counter is powered by EVCache , Netflix’s distributed caching solution built on the widely popular Memcached.
Caching is the process of storing frequently accessed data or resources in a temporary storage location, such as memory or disk, to improve retrieval speed and reduce the need for repetitive processing.
Mounting object storage in Netflix’s media processing platform By Barak Alon (on behalf of Netflix’s Media Cloud Engineering team) MezzFS (short for “Mezzanine File System”) is a tool we’ve developed at Netflix that mounts cloud objects as local files via FUSE. Our object storage service splits objects into many parts and stores them in S3.
A shared characteristic in most (if not all) databases, be them traditional relational databases like Oracle, MySQL, and PostgreSQL or some kind of NoSQL-style database like MongoDB, is the use of a caching mechanism to keep (a copy of) part of the data in memory. How do you know if your MySQL database caching is operating efficiently?
Our goal was to build a versatile and efficient data storage solution that could handle a wide variety of use cases, ranging from the simplest hashmaps to more complex data structures, all while ensuring high availability, tunable consistency, and low latency. Developers just provide their data problem rather than a database solution!
Figure 1: A Simplified Video Processing Pipeline With this architecture, chunk encoding is very efficient and processed in distributed cloud computing instances. From chunk encoding to assembly and packaging, the result of each previous processing step must be uploaded to cloud storage and then downloaded by the next processing step.
This means you no longer have to provision, scale, and maintain servers to run your applications, databases, and storage systems. Speed is next; serverless solutions are quick to spin up or down as needed, and there are no delays due to limited storage or resource access. AWS offers four serverless offerings for storage.
Interestingly, our partner RedHat reported in 2021 that around 80% of deployed workloads are databases or data caches, storing data in persistent volume claims (PVCs). You quickly realize that it will take ages to fill up the overprovisioned database storage. Two days later, your database runs out of storage in the middle of the night.
MongoDB offers several storage engines that cater to various use cases. The default storage engine in earlier versions was MMAPv1, which utilized memory-mapped files and document-level locking. The newer, pluggable storage engine, WiredTiger, addresses this by using prefix compression, collection-level locking, and row-based storage.
Enhanced data security, better data integrity, and efficient access to information. Despite initial investment costs, DBMS presents long-term savings and improved efficiency through automated processes, efficient query optimizations, and scalability, contributing to enhanced decision-making and end-user productivity.
They could need a GPU when doing graphics-intensive work or extra large storage to handle file management. Instead, we created a service to take the most popular configurations and cache them. We rely on our internal partner teams to support components installed on the workstation, such as storage and artist tools.
A distributed storage system is foundational in today’s data-driven landscape, ensuring data spread over multiple servers is reliable, accessible, and manageable. Understanding distributed storage is imperative as data volumes and the need for robust storage solutions rise.
Building on these foundational abstractions, we developed the TimeSeries Abstraction — a versatile and scalable solution designed to efficiently store and query large volumes of temporal event data with low millisecond latencies, all in a cost-effective manner across various use cases. Let’s dive into the various aspects of this abstraction.
While data lakes and data warehousing architectures are commonly used modes for storing and analyzing data, a data lakehouse is an efficient third way to store and analyze data that unifies the two architectures while preserving the benefits of both. Unlike data warehouses, however, data is not transformed before landing in storage.
Building an elastic query engine on disaggregated storage , Vuppalapati, NSDI’20. Snowflake is a data warehouse designed to overcome these limitations, and the fundamental mechanism by which it achieves this is the decoupling (disaggregation) of compute and storage. joins) during query processing. Disaggregation (or not).
This is a set of best practices and guidelines that help you design and operate reliable, secure, efficient, cost-effective, and sustainable systems in the cloud. The framework comprises six pillars: Operational Excellence, Security, Reliability, Performance Efficiency, Cost Optimization, and Sustainability.
are stored in secure storage layers. Amsterdam is built on top of three storage layers. To avoid the ES query for the list of indices for every indexing request, we keep the list of indices in a distributed cache. It is also responsible for asset discovery, validation, sharing, and for triggering workflows.
With these clear benefits, we continued to build out this functionality for more devices, enabling the same efficiency wins. It was very efficient, but it had a set job size, requiring manual intervention if we wanted to horizontally scale it, and it required manual intervention when rolling out a new version.
Key Takeaways Redis offers complex data structures and additional features for versatile data handling, while Memcached excels in simplicity with a fast, multi-threaded architecture for basic caching needs. Redis is better suited for complex data models, and Memcached is better suited for high-throughput, string-based caching scenarios.
The more indexes, the more the requirement of memory for effective caching. Indexes need more cache than tables Due to random writes and reads, indexes need more pages to be in the cache. Cache requirements for indexes are generally much higher than associated tables.
This post will look at using The Oversized-Attribute Storage Technique (TOAST) to improve performance and scalability. Therefore, TOAST is a storage technique used in PostgreSQL to handle large data objects such as images, videos, and audio files.
A bloom filter is a space-efficient way of storing information about a list of keys. For good performance, the filter blocks are cached in the RocksDB block cache and normally stay there since they are accessed frequently. Bloom filter is an important feature improving performance of LSM storage engines.
Active Memory Caching. When you want to get data that you already had quickly, you need to do caching — caching stores data that a user recently retrieved. Caching partially stores your data and is not used as permanent storage. Caching partially stores your data and is not used as permanent storage.
Effective management of memory stores with policies like LRU/LFU proactive monitoring of the replication process and advanced metrics such as cache hit ratio and persistence indicators are crucial for ensuring data integrity and optimizing Redis’s performance. Cache Hit Ratio The cache hit ratio represents the efficiency of cache usage.
We will also discuss related configuration variables to consider that can impact these KPIs, helping you gain a comprehensive understanding of your MySQL server’s performance and efficiency. Query performance Query performance is a key performance indicator (KPI) in MySQL, as it measures the efficiency and speed of query execution.
File systems unfit as distributed storage backends: lessons from 10 years of Ceph evolution Aghayev et al., In this case, the assumption that a distributed storage backend should clearly be layered on top of a local file system. What is a distributed storage backend? SOSP’19. This is not surprising in hindsight.
To monitor Redis instances effectively, collect Redis metrics focusing on cache hit ratio, memory allocated, and latency threshold. This ensures each Redis instance optimally uses the in-memory data store and aligns with the operating system’s efficiency.
To monitor Redis® instances effectively, collect Redis metrics focusing on cache hit ratio, memory allocated, and latency threshold. This ensures each Redis® instance optimally uses the in-memory data store and aligns with the operating system’s efficiency.
Last week we looked at a function shipping solution to the problem; Cloudburst uses the more common data shipping to bring data to caches next to function runtimes (though you could also make a case that the scheduling algorithm placing function execution in locations where the data is cached a flavour of function-shipping too).
Categories can contain thousands of products and user cannot efficiently search though this array without powerful tools. The rationale behind these methods is that frontend should be able to fetch transient information very efficiently and separately from fetching of heavy-weight domain entities because this information cannot be cached.
These developments gradually highlight a system of relevant database building blocks with proven practical efficiency. We use term ReadOne-WriteOne for combination of techniques A, B, C and D – they all do not provide strict consistency guarantees, but are efficient enough to be used in practice as an self-contained approach. (E,
Benefits of Power BI The advantages of Power BI are manifold, from its intuitive interface to its ability to handle large datasets efficiently. By utilizing query folding effectively, you can ensure that Power BI sends optimized queries to MySQL, which can take advantage of the database’s indexing, caching, and processing capabilities.
In response, we began to develop a collection of storage and database technologies to address the demanding scalability and reliability requirements of the Amazon.com ecommerce platform. s pricing is simple and predictable: Storage is $1 per GB per month. The growth of Amazonâ??s Domain scaling limitations. Amazon DynamoDBâ??s
After the “data dictionary” (DD) engine and DD cache are initialized on a server, the Storage Engines can ask for a table definition. Initializing a DD engine and the cache adds complexity and other server dependencies. Essentially LRU cache is disabled by loading the tables as non-evictable. ibd > t1.sdi
For example, the IMDG must be able to efficiently create millions of objects in each server to make use of its huge storage capacity. During load-balancing, the client gets the following exception when accessing the cache: ErrorCode<ERRCA0017>:SubStatus<ES0006>:There is a temporary failure. Please retry later.
This consistent performance is a big part of why the Snapchat Stories feature , which includes Snapchat's largest storage write workload, moved to DynamoDB. Tinder is one example of a customer that is using the flexible schema model of DynamoDB to achieve developer efficiency.
Amazon ElastiCache customers will see their prices drop by up to 10%, depending on their cache node types. We continuously apply all our innovative skills to the design of datacenters, servers, storage, network, etc. to drive new efficiencies and higher reliability.
PostgreSQL performance optimization aims to improve the efficiency of a PostgreSQL database system by adjusting configurations and implementing best practices to identify and resolve bottlenecks, improve query speed, and maximize database throughput and responsiveness. What is PostgreSQL performance tuning?
While caching continues to be a dominant use of ElastiCache for Redis, we see customers increasingly use it as an in-memory NoSQL database. ElastiCache for Redis Multi-AZ capability is built to handle any failover case for Redis Cluster with robustness and efficiency. This does not happen with ElastiCache for Redis.
When each of those use cases is powered by a dedicated back-end, investments in better performance, improved scalability and efficiency etc. Cache all the things. Procella achieves high scalability and efficiency by segregating storage (in Colossus) from compute (on Borg). are divided. Making Procella fast.
Using genomics and deep learning as two motivating examples, he highlighted the importance of algorithm-architecture co-design to improve end-to-end efficiency. The best paper runner-up was “ Dynamic Multi-Resolution Data Storage ”. . Albonesi.
The principle of locality While the principle of locality is usually related to processors and cache access patterns, it also applies to data access in general. If your data is organized following the principle of locality, data access will be more efficient. This type of fragmentation can improve performance and efficiency.
Nx is an open-source build framework that helps you architect, test, and build at any scale — integrating seamlessly with modern technologies and libraries, while providing a robust command-line interface (CLI), caching, and dependency management. Nx uses distributed graph-based task execution and computation caching to speed up tasks.
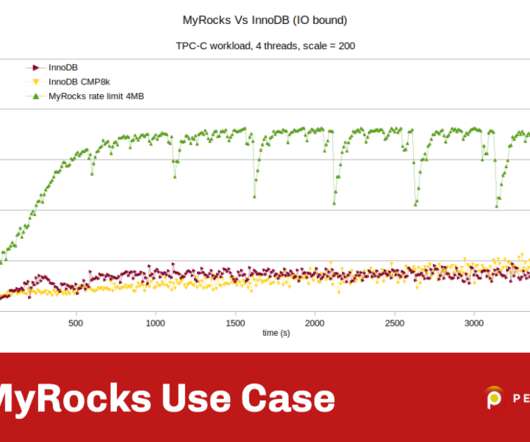
I wrote this post on MyRocks because I believe it is the most interesting new MySQL storage engine to have appeared over the last few years. Although MyRocks is very efficient for writes, I chose a more generic workload that will provide a different MyRocks use case. RocksDB is a very efficient key-value store based on LSM trees.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content