

Netflix’s Distributed Counter Abstraction
The Netflix TechBlog
NOVEMBER 12, 2024
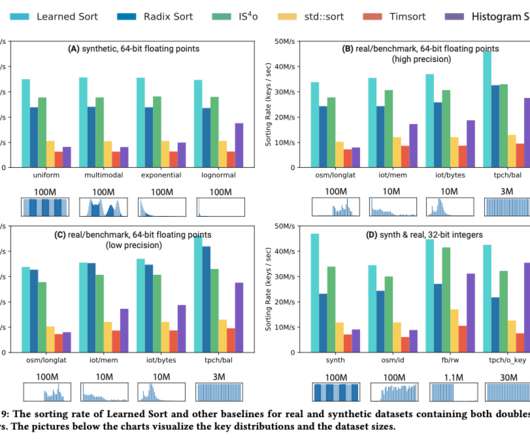
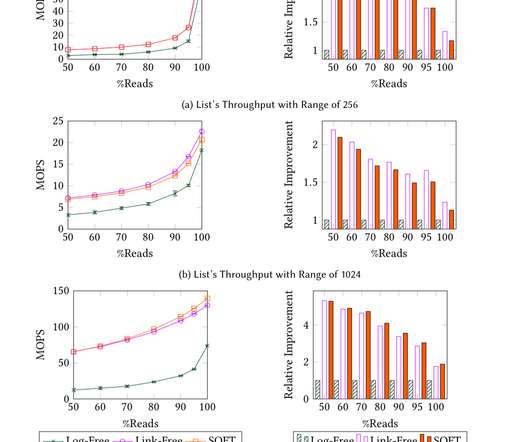
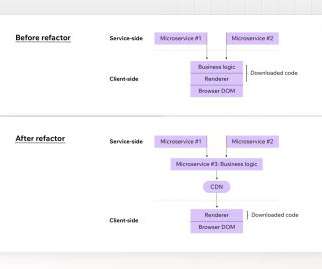
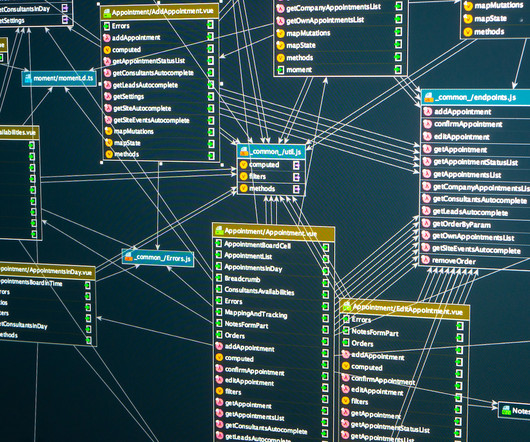
Today, we’re excited to present the Distributed Counter Abstraction. In this context, they refer to a count very close to accurate, presented with minimal delays. Best Effort Regional Counter This type of counter is powered by EVCache , Netflix’s distributed caching solution built on the widely popular Memcached.











































Let's personalize your content