This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Caching is the process of storing frequently accessed data or resources in a temporary storage location, such as memory or disk, to improve retrieval speed and reduce the need for repetitive processing. Bandwidth optimization: Caching reduces the amount of data transferred over the network, minimizing bandwidth usage and improving efficiency.
Bloom filters are probabilistic data structures that allow for efficient testing of an element's membership in a set. Bloom, these data structures have found applications in various fields such as databases, caching, networking, and more. Since their invention in 1970 by Burton H.
Our goal was to build a versatile and efficient data storage solution that could handle a wide variety of use cases, ranging from the simplest hashmaps to more complex data structures, all while ensuring high availability, tunable consistency, and low latency. Developers just provide their data problem rather than a database solution!
Interestingly, our partner RedHat reported in 2021 that around 80% of deployed workloads are databases or data caches, storing data in persistent volume claims (PVCs). For example, let’s say you have an idea for a new social network and decide to use Kubernetes as your container management platform. Coming Soon.
In addition, with 193M members and counting, there is a huge diversity in the networks that stream our content as well as in our members’ bandwidth. It is, thus, imperative that we are sensible in the use of the network and of the bandwidth we require. and thus fall back to less efficient encode families.
This is a set of best practices and guidelines that help you design and operate reliable, secure, efficient, cost-effective, and sustainable systems in the cloud. The framework comprises six pillars: Operational Excellence, Security, Reliability, Performance Efficiency, Cost Optimization, and Sustainability.
Enhanced data security, better data integrity, and efficient access to information. Despite initial investment costs, DBMS presents long-term savings and improved efficiency through automated processes, efficient query optimizations, and scalability, contributing to enhanced decision-making and end-user productivity.
Figure 1: A Simplified Video Processing Pipeline With this architecture, chunk encoding is very efficient and processed in distributed cloud computing instances. It is worth pointing out that cloud processing is always subject to variable network conditions. For write operations, those challenges do not apply.
Because microprocessors are so fast, computer architecture design has evolved towards adding various levels of caching between compute units and the main memory, in order to hide the latency of bringing the bits to the brains. This avoids thrashing caches too much for B and evens out the pressure on the L3 caches of the machine.
This is just one of many use cases that MezzFS supports, but all the use cases share a similar theme: stream the right bits of a remote object efficiently and expose those bits as a file on the filesystem. Disk Caching? — ? MezzFS can be configured to cache objects on the local disk. Regional caching? —?Netflix
Missing Cache Settings – Make sure you cache resources that don’t change often on the browser or use a CDN. Too many fine-grained services leading to network and communication overhead. Missing caching layers, e.g. provide a read-only cache for static data. N+1 Query Pattern. Infrastructure Optimization.
This allows the app to query a list of “paths” in each HTTP request, and get specially formatted JSON (jsonGraph) that we use to cache the data and hydrate the UI. Latencies The old api service was running on the same “machine” that also cached a lot of video metadata (by design). This meant that data that was static (e.g.
With these clear benefits, we continued to build out this functionality for more devices, enabling the same efficiency wins. It was very efficient, but it had a set job size, requiring manual intervention if we wanted to horizontally scale it, and it required manual intervention when rolling out a new version.
Building on these foundational abstractions, we developed the TimeSeries Abstraction — a versatile and scalable solution designed to efficiently store and query large volumes of temporal event data with low millisecond latencies, all in a cost-effective manner across various use cases. Let’s dive into the various aspects of this abstraction.
Performance efficiency. Using a data-driven approach to size Azure resources, Dynatrace OneAgent captures host metrics out-of-the-box to assess CPU, memory, and network utilization on a VM host. Performance Efficiency. Design efficient use of your computing resources as demand changes and technologies evolves.
Key Takeaways Redis offers complex data structures and additional features for versatile data handling, while Memcached excels in simplicity with a fast, multi-threaded architecture for basic caching needs. Redis is better suited for complex data models, and Memcached is better suited for high-throughput, string-based caching scenarios.
the order of the rows on your Netflix home page, issuing content licenses when you click play, finding the Open Connect cache closest to you with the content you requested, and many more). In the Efficiency space, our data teams focus on transparency and optimization.
Effective management of memory stores with policies like LRU/LFU proactive monitoring of the replication process and advanced metrics such as cache hit ratio and persistence indicators are crucial for ensuring data integrity and optimizing Redis’s performance. Cache Hit Ratio The cache hit ratio represents the efficiency of cache usage.
Amazon ElastiCache is a fully managed, in-memory caching service for customers to optimize the latency, performance and cost of their read workloads. The db.cr1.8xlarge has 88 ECUs, 244GB of memory, high-bandwidth network, and the ability to deliver up to 20,000 IOPS for MySQL 5.6,
On top of this foundation, we add layers of caching, prerendering and edge delivery optimizations — not the other way around. Hydrogen fuels dynamic commerce by uniting React Server Components, streaming server-side rendering, and smart caching controls. Large preview ). This is not a debate about dynamic vs. static.
Without build optimizations (incremental builds, caching, we will get to those soon) this will eventually become unmanageable as well — think about going through all images in a website: resizing, deleting, and/or creating new files over and over again. The cache is invalidated on a time basis. Creating an On-Demand builder.
The more indexes, the more the requirement of memory for effective caching. Indexes need more cache than tables Due to random writes and reads, indexes need more pages to be in the cache. Cache requirements for indexes are generally much higher than associated tables.
We will also discuss related configuration variables to consider that can impact these KPIs, helping you gain a comprehensive understanding of your MySQL server’s performance and efficiency. Query performance Query performance is a key performance indicator (KPI) in MySQL, as it measures the efficiency and speed of query execution.
This includes latency, which is a major determinant in evaluating the reliability and performance of your Redis instance, CPU usage to assess how much time it spends on tasks, operations such as reading/writing data from disk or network I/O, and memory utilization (also known as memory metrics).
To be effective, all these images need to be carefully orchestrated to appear on the screen fast — but as it turns out, loading images efficiently at scale isn’t a project for a quiet afternoon. Keeping this efficient helps ensure a good user experience. Optimizing Network Requests with Caching and Preloading. +.
Analysed from the perspective of cloud-native design this presents a number of issues: CPU, memory, storage, and bandwidth resources are all aggregated at each node, and can’t be scaled independently, making it hard to fit a workload efficiently across multiple dimensions. joins) during query processing.
By breaking up large datasets into more manageable pieces, each segment can be assigned to various network nodes for storage and management purposes. It utilizes methodologies like DStore, which takes advantage of underused hard drive space by using it for storing vast amounts of collected datasets while enabling efficient recovery processes.
In order to create change across our entire organization, we needed to get all the relevant employees, partners, and even customers up to speed about performance quickly and efficiently. The results of some of these APIs are also cached in a CDN as appropriate. Creating A Performance Culture. Large preview ).
This includes latency, which is a major determinant in evaluating the reliability and performance of your Redis® instance, CPU usage to assess how much time it spends on tasks, operations such as reading/writing data from disk or network I/O, and memory utilization (also known as memory metrics).
We’ll be learning how to do this with GraphQL Features like Cache Update, Subscriptions, and Optimistic UI. Updating the cache directly using update function on the useMutation. Updating the cache directly using update function on the useMutation. This lets us update our client-side cache immediately with consistent data.
Using a network request inspector, I’m going to see if there’s anything we can remove via the Network panel in DevTools. I like using Fiddler , and when I inspect the network requests I see that there are indeed some old URLs and redirects floating around. Compressing, minifying and caching assets.
Last week we looked at a function shipping solution to the problem; Cloudburst uses the more common data shipping to bring data to caches next to function runtimes (though you could also make a case that the scheduling algorithm placing function execution in locations where the data is cached a flavour of function-shipping too).
To be effective, all these images need to be carefully orchestrated to appear on the screen fast — but as it turns out, loading images efficiently at scale isn’t a project for a quiet afternoon. Keeping this efficient helps ensure a good user experience. Optimizing Network Requests with Caching and Preloading. +.
For example, the IMDG must be able to efficiently create millions of objects in each server to make use of its huge storage capacity. Also, load-balancing after membership changes must be both multi-threaded and pipelined to drive the network at maximum bandwidth. Please retry later.
Failing that, we are usually able to connect to home or public WiFi networks that are on fast broadband connections and have effectively unlimited data. The speed of mobile networks, too, varies considerably between countries. As for mobile network connection type, 84.7% Kyrgyzstan, Kazakhstan and Ukraine follow at $0.27, $0.49
Categories can contain thousands of products and user cannot efficiently search though this array without powerful tools. The rationale behind these methods is that frontend should be able to fetch transient information very efficiently and separately from fetching of heavy-weight domain entities because this information cannot be cached.
Generally to cache data (including non-persistent data that never sees a backing store), to share non-persistent data across application services (e.g. ” Even re-reading that today, the letter of the law there is surprisingly strict to me: you can use the local memory space or filesystem as a brief single transaction cache, but no more.
Importance of Managing and Scaling Distributed SQL Databases Managing and growing distributed SQL databases is important for modern businesses to work efficiently and stay agile. Tools and Techniques for Scaling Distributed SQL Databases Several tools and techniques facilitate the efficient scaling of distributed SQL databases.
Next, we’ll look at how to set up servers and clients (that’s the hard part unless you’re using a content delivery network (CDN)). Using just a few (but still more than one), however, could nicely balance congestion growth with better performance, especially on high-speed networks. Servers and Networks.
Amazon ElastiCache customers will see their prices drop by up to 10%, depending on their cache node types. We continuously apply all our innovative skills to the design of datacenters, servers, storage, network, etc. to drive new efficiencies and higher reliability.
While caching continues to be a dominant use of ElastiCache for Redis, we see customers increasingly use it as an in-memory NoSQL database. ElastiCache for Redis Multi-AZ capability is built to handle any failover case for Redis Cluster with robustness and efficiency. This does not happen with ElastiCache for Redis.
Tinder is one example of a customer that is using the flexible schema model of DynamoDB to achieve developer efficiency. Typical use cases for a graph database include social networking, recommendation engines, fraud detection, and knowledge graphs. Amazon Neptune is a fully-managed graph database service.
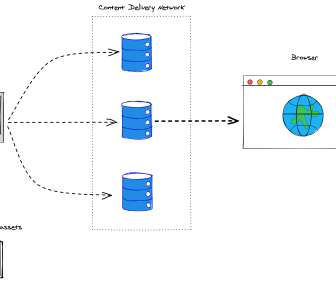
As you may already know, image optimization is the process that a high-quality image has to go through to be delivered in ideal conditions, sometimes with the help of an Image Transformation API and a global Content Delivery Network (CDN) to make the process simpler and scalable. Cache Your Images.
There’s another emerging option that we didn’t talk about there: the use of far-memory , memory attached to the network that can be remotely accessed without mediation by a local processor. Processor caches can help to hide local accesses too, but not remote accesses. Clients cache the entire tree, but not the hash tables.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content