This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
It allows users to choose between different counting modes, such as Best-Effort or Eventually Consistent , while considering the documented trade-offs of each option. Failures in a distributed system are a given, and having the ability to safely retry requests enhances the reliability of the service.
Many of these projects are under constant development by dedicated teams with their own business goals and development best practices, such as the system that supports our content decision makers , or the system that ranks which language subtitles are most valuable for a specific piece ofcontent.
As Kubernetes adoption increases and it continues to advance technologically, Kubernetes has emerged as the “operating system” of the cloud. Kubernetes is emerging as the “operating system” of the cloud. Kubernetes is emerging as the “operating system” of the cloud. Kubernetes moved to the cloud in 2022.
Spring Boot 2 uses Micrometer as its default application metrics collector and automatically registers metrics for a wide variety of technologies, like JVM, CPU Usage, Spring MVC, and WebFlux request latencies, cache utilization, data source utilization, Rabbit MQ connection factories, and more. To learn more, see our documentation.
GenAI is prone to erratic behavior due to unforeseen data scenarios or underlying system issues. The RAG process begins by summarizing and converting user prompts into queries that are sent to a search platform that uses semantic similarities to find relevant data in vector databases, semantic caches, or other online data sources.
By Chris Wolfe , Joey Schorr , and Victor Roldán Betancort Introduction The authorization team at Netflix recently sponsored work to add Attribute Based Access Control (ABAC) support to AuthZed’s open source Google Zanzibar inspired authorization system, SpiceDB. This would be a significant departure from its existing policy based system.
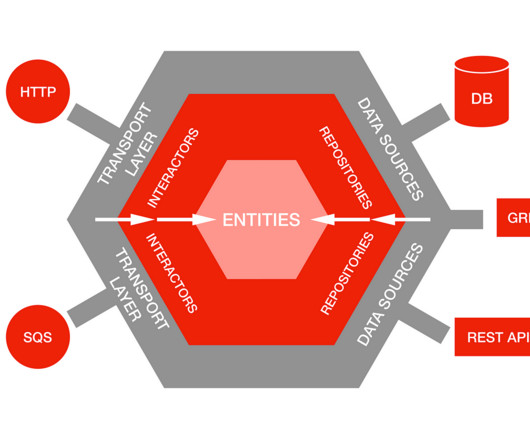
This means you no longer have to provision, scale, and maintain servers to run your applications, databases, and storage systems. Amazon SQS: The Amazon Simple Queue Service enables users to decouple and scale microservices, serverless applications, and distributed systems, reducing both IT overhead and total complexity. Data Store.
Browsers will cache tools popular among vocal, leading-edge developers. There's plenty of space for caching most popular frameworks. The best available proxy data also suggests that shared caches would have a minimal positive effect on performance. Browsers now understand the classic shared HTTP cache behaviour as a privacy bug.
No single service has complete context into how the system works. Best of all, our page can load much faster since everything is cached in Elasticsearch. Once all documents have been indexed with no errors, we swap the alias from the currently active index to the newly built index. Our data changes constantly?—?
In this post, we will explain the Redis transactional property of scripts, what this error is about, and why we must be extra careful about it on Sentinel-managed systems that can failover. The complete information on methods to kill the script execution and related behavior are available in the documentation. Demonstration.
In practice, session recording solutions make use of the document object model (DOM), which is a programming interface for web pages and document. Streamlined asset caching: Asset caching is critical for creating accurate replays. Make sure you know what assets your replay tool is recording and how you can access them.
The default storage engine in earlier versions was MMAPv1, which utilized memory-mapped files and document-level locking. It uses a filesystem cache and write-ahead log for crash recovery. However, keep in ming that it does not release space to the operating system. Compaction operation defragments data files & indexes.
This allows the app to query a list of “paths” in each HTTP request, and get specially formatted JSON (jsonGraph) that we use to cache the data and hydrate the UI. You can find a lot more details about how this works in the Spinnaker canaries documentation. This meant that data that was static (e.g.
Our UI runs on top of a custom rendering engine which uses what we call a “surface cache” to optimize our use of graphics memory. Surface Cache Surface cache is a reserved pool in main memory (or separate graphics memory on a minority of systems) that the Netflix app uses for storing textures (decoded images and cached resources).
Loosely defined, observability is the ability to understand what’s happening inside a system from the knowledge of the external data it produces, which are usually logs, metrics, and traces. Source: OpenTelemetry Documentation. OTel is a specialized protocol for collecting telemetry data and exporting it to a target system.
We store all OperationIDs which are in STARTED state in a distributed cache (EVCache) for fast access during searches. This API finds all Elasticsearch documents with ID1 and marks isAnnotationOperationActive=FALSE. We do that by excluding the following from all queries in our system.
To fix this, we've improved support for React Server Components (RSC) and added prefetch helpers to make it easier to utilize the power of RSCs running exclusively on the server, in combination with the highly dynamic client-side cache of React Query. You can read more in our Server Components documentation.
Note: Contrary to what the name may suggest, this system is not built as a general-purpose time series database. Those use cases are well served by the Netflix Atlas telemetry system. Effectively managing this data at scale to extract valuable insights is crucial for ensuring optimal user experiences and system reliability.
Spring Boot 2 uses Micrometer as its default application metrics collector and automatically registers metrics for a wide variety of technologies, like JVM, CPU Usage, Spring MVC, and WebFlux request latencies, cache utilization, data source utilization, Rabbit MQ connection factories, and more. To learn more, see our documentation.
Spring Boot 2 uses Micrometer as its default application metrics collector and automatically registers metrics for a wide variety of technologies, like JVM, CPU Usage, Spring MVC, and WebFlux request latencies, cache utilization, data source utilization, Rabbit MQ connection factories, and more. To learn more, see our documentation.
This data would be collated and authored in a Web Content Management System (WCMS) by a content editor. We had marketers from a Traditional CMS background who resisted the idea of delving into multiple systems and services when using a headless CMS. Comprehensive documentation and code samples are also a must. Content Previews.
Without going further into the reasons for such a need, I wanted to refresh this subject in terms of overhead related to running the command on production systems. A lot has changed since then, but many production systems alive today still run with affected versions. sbtest1 | analyze | status | OK | + -+ + -+ -+ 1 row in set (0.00
Statically linked application binaries have their merits; they’re self-contained and they don’t have dependencies on the systems they’re deployed to. From http.Transport documentation : By default, Transport caches connections for future reuse. is used to enforce a statically linked foxy executable.
This allows resource requests, including the HTML document itself, to be enriched with data during its lifecycle, and that information can be inspected for measuring the attributes of that resource! For the top-level HTML document, it is fetched upon user navigation but is still a resource request.
On design systems, UX, web performance and CSS/JS. Jamstack is popular with documentation sites that usually compile code to HTML files and host them on the CDN. Active Memory Caching. When you want to get data that you already had quickly, you need to do caching — caching stores data that a user recently retrieved.
The service workers enable the offline usage of the PWA by fetching cached data or informing the user about the absence of an Internet connection. When developing a PWA, you can cache the application shell’s resources and assets in the browser. Cached content with IndexedDB. Cache first, then network. Service Workers.
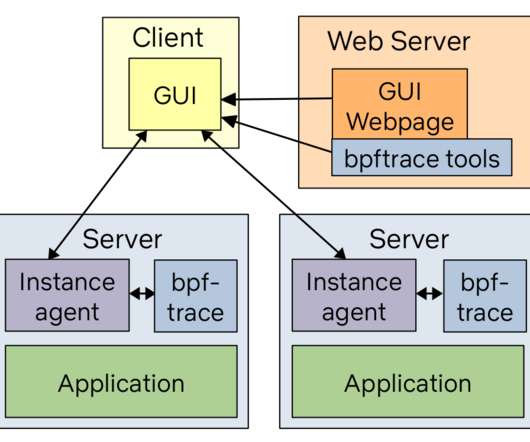
This is also applicable for people adding it to their own in-house monitoring systems. You likely already have agents running on all your customer systems. There are so many options it's really your own preference based on your existing system and customer environments. cachestat File systemcache statistics line charts.
During the 90s, we saw two content management systems for static sites — Microsoft FrontPage in 1996 and Macromedia Dreamweaver in 1997. These desktop applications incremented the tooling an inch closer to the modern Jamstack content management systems of today. These use cases include: Documentation. Large preview ).
How well does AMP perform when the library is served using the AMP cache? But what you don’t see is that Google gets that instantaneous loading by actively preloading AMP documents in the background. In the case of the search carousel, it’s literally an iframe that gets populated with the entirety of the AMP document.
50 ways to leak your data: an exploration of apps’ circumvention of the Android permissions system Reardon et al., Side-channels are typically an unintentional consequence of a complicated system. The OpenX SDK was found to be using the ARP cache side channel, and the code makes it clear the authors knew what they were doing.
Heading into 2024, SQL databases will remain essential in data management, increasingly using distributed systems to meet growing needs for scalability and reliability. Facing the complexities of these systems, we will also introduce some modern solutions that make database administration more streamlined.
No single service has complete context into how the system works. Best of all, our page can load much faster since everything is cached in Elasticsearch. Once all documents have been indexed with no errors, we swap the alias from the currently active index to the newly built index. Our data changes constantly?—?
ChatGPT: The InnoDB buffer pool is used by MySQL to cache frequently accessed data in memory. If we expand the cache concept more, the buffer pool could be even less if the working set (hot data) is smaller. Also, there is a documented bug: OPTIMIZE TABLE does not sort R-tree indexes, such as spatial indexes on POINT columns.
Recently I was asked about content management systems (CMS) of the future - more specifically how they are evolving in the era of microservices, APIs, and serverless computing. Raw content data along with templates are version controlled using Git or similar versioning systems. can generate an HTML-only website without involving a CMS.
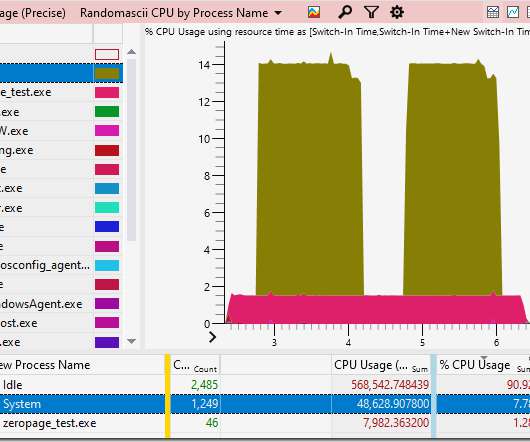
Downloads go through the cache, the cache is saved to disk, and saves to disk are slowed by (some) anti-virus software. This table told me that if I’m spending 16% of a core on page faults then I’m probably also spending – hidden in the System process – about 13.7% The system process manages to consume 29 processors (!!!)
In order to be supported, a database is required to fulfill a set of features that are commonly available in systems like MySQL, PostgreSQL, MariaDB, and others. We want to support these systems as a source so that they can provide their data for further consumption. Some of DBLog’s features are: Processes captured log events in-order.
The problem is that this system has a default libc that has been compiled without frame pointers, so any stack walking stops at the libc layer, producing a partial stack that's missing the application frames. This is pretty common and usually goes unnoticed as the flame graph looks ok at first glance. What are frame pointers?
Nx is an open-source build framework that helps you architect, test, and build at any scale — integrating seamlessly with modern technologies and libraries, while providing a robust command-line interface (CLI), caching, and dependency management. Nx uses distributed graph-based task execution and computation caching to speed up tasks.
In order to be supported, a database is required to fulfill a set of features that are commonly available in systems like MySQL, PostgreSQL, MariaDB, and others. We want to support these systems as a source so that they can provide their data for further consumption. Some of DBLog’s features are: Processes captured log events in-order.
The general idea is to cache and replay results, saving repeated executions of inner-side operators wherever possible. When a spool is able to replay cached results, this is known as a rewind. You may find it helpful to think of a spool rebind as a cache miss, and a rewind as a cache hit. Lazy Table Spool.
Also, high-quality documentation is available for developers with any development issues and queries. Also, there are tutorials, video forums, and documentation, making PHP development easy and troubleshooting more accessible. Various techniques, such as caching and optimization, improve the website’s performance and speed.
No single service has complete context into how the system works. Best of all, our page can load much faster since everything is cached in Elasticsearch. Once all documents have been indexed with no errors, we swap the alias from the currently active index to the newly built index. Our data changes constantly?—?
Werner Vogels weblog on building scalable and robust distributed systems. The original Dynamo design was based on a core set of strong distributed systems principles resulting in an ultra-scalable and highly reliable database system. All Things Distributed. Amazon DynamoDB â?? By Werner Vogels on 18 January 2012 07:00 AM.
Fragmentation is a common concern in some database systems. The principle of locality While the principle of locality is usually related to processors and cache access patterns, it also applies to data access in general. The freed space will not return to the file system but will be reused by new pages. What is fragmentation?
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content