This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
It allows users to choose between different counting modes, such as Best-Effort or Eventually Consistent , while considering the documented trade-offs of each option. After selecting a mode, users can interact with APIs without needing to worry about the underlying storage mechanisms and counting methods.
This means you no longer have to provision, scale, and maintain servers to run your applications, databases, and storage systems. Speed is next; serverless solutions are quick to spin up or down as needed, and there are no delays due to limited storage or resource access. AWS offers four serverless offerings for storage.
MongoDB offers several storage engines that cater to various use cases. The default storage engine in earlier versions was MMAPv1, which utilized memory-mapped files and document-level locking. Choosing the appropriate storage engine can have a significant impact on application performance.
are stored in secure storage layers. Amsterdam is built on top of three storage layers. It provides simple APIs for creating indices, indexing or searching documents, which makes it easy to integrate. Mapping is used to define how documents and their fields are supposed to be stored and indexed. Net, Ruby, Perl etc.).
Of the organizations in the Kubernetes survey, 71% run databases and caches in Kubernetes, representing a +48% year-over-year increase. Together with messaging systems (+36% growth), organizations are increasingly using databases and caches to persist application workload states.
Flexible Storage : The service is designed to integrate with various storage backends, including Apache Cassandra and Elasticsearch , allowing Netflix to customize storage solutions based on specific use case requirements. Note : With Cassandra 4.x
In practice, session recording solutions make use of the document object model (DOM), which is a programming interface for web pages and document. Streamlined asset caching: Asset caching is critical for creating accurate replays. Make sure you know what assets your replay tool is recording and how you can access them.
We store all OperationIDs which are in STARTED state in a distributed cache (EVCache) for fast access during searches. This API finds all Elasticsearch documents with ID1 and marks isAnnotationOperationActive=FALSE. This new operation is marked to be in STARTED state. They pass annotations along with the OperationID.
In response to these needs, developers now have the choice of relational, key-value, document, graph, in-memory, and search databases. This consistent performance is a big part of why the Snapchat Stories feature , which includes Snapchat's largest storage write workload, moved to DynamoDB. Build on.
Jamstack is popular with documentation sites that usually compile code to HTML files and host them on the CDN. Active Memory Caching. When you want to get data that you already had quickly, you need to do caching — caching stores data that a user recently retrieved. Caching Schemes. Caching Schemes.
Source: OpenTelemetry Documentation. The data is incredibly plentiful and difficult to store over long periods due to capacity limitations — a reason why private and public cloud storage services have been a boon to DevOps teams. This occurs once data is safely stored within a local cache. OpenTelemetry reference architecture.
The service workers enable the offline usage of the PWA by fetching cached data or informing the user about the absence of an Internet connection. When developing a PWA, you can cache the application shell’s resources and assets in the browser. Cached content with IndexedDB. Cache first, then network. Service Workers.
More specifically, we’re going to talk about storage and UI differences, which are the ones that most often cause confusion to developers when writing Flutter code that they want to be cross-platform. Example 1: Storage. Secure Storage On Mobile. The situation when it comes to mobile apps is completely different.
Nx is an open-source build framework that helps you architect, test, and build at any scale — integrating seamlessly with modern technologies and libraries, while providing a robust command-line interface (CLI), caching, and dependency management. Nx uses distributed graph-based task execution and computation caching to speed up tasks.
In response, we began to develop a collection of storage and database technologies to address the demanding scalability and reliability requirements of the Amazon.com ecommerce platform. After the successful launch of the first Dynamo system, we documented our experiences in a paper so others could benefit from them. Amazon DynamoDBâ??s
Today, we’ll address storing and serving files for both single-server and scalable deployments while considering factors like compression, caching, and availability. We’ll also discuss the costs and benefits of CDNs and dedicated file storage solutions. For more details, see the Django documentation. Media Files. Media Files.
IT professionals are familiar with scoping the size of VMs with regards to vCPU, memory, and storage capacity. Memory optimized – High memory-to-CPU ratio, relational database servers, medium to large caches, and in-memory analytics. Storage optimized – High disk throughput and IO. Premium storage support. Generation.
Its raison d’être is to cache result rows from a plan subtree, then replay those rows on subsequent iterations if any correlated loop parameters are unchanged. The documentation says only the following operators can rewind: Table Spool. I have not been able to find any official explanation or documentation about it.
1 among non-relational/document-based systems ( DB-Engines, July 2023 ). Instead of the table-based structure of relational databases, MongoDB stores data in documents and collections, a design for handling large amounts of unstructured data and for real-time web applications. It ranks No.
Note: We received feedback that there was some confusion on us calling this functionality “tail of the log caching” because our documentation and prior history has referred to the tail of the log as the portion of the hardened log that has not been backed up. Block storage is what you think of today as disk access.
The principle of locality While the principle of locality is usually related to processors and cache access patterns, it also applies to data access in general. Regarding tablespace and segment fragmentation, modern storage systems tend to reduce the impact of these types of fragmentation.
We can use 11ty’s new Serverless mode to build them on request using Netlify’s On-Demand Builders to cache each Madlib. For example, an “On-Demand Builder” is a serverless function dedicated to serving a cached file. Netlify then caches that page on its edge CDN for each additional call. Large preview ). More after jump!
This article isn’t about the act of lock escalation itself, which is already well documented and generally well understood. Much of the documentation is incorrect or at least imprecise about this and I’ve been unable to find a correct description in other writings. This appears to contradict the documentation in several respects.
Local-first apps keep their data in local storage on each device, but the data is also synchronised across all the devices on which a user works. One of the fruits of this work is an open-source JavaScript CDRT implementation called Automerge which brings CRDT-style merge operations to JSON documents. It should work without a network.
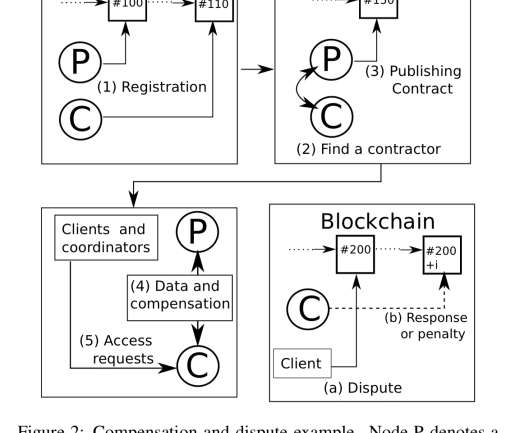
Our approach differs substantially by (1) providing economic incentives for data to be contributed and integrated into existing schemas, (2) offering a SQL interface instead of graph based approaches, (3) including the computational and storage infrastructure in the architectural vision. Coordinators that don’t want to pay contractors?
Configure the PostgreSQL hostname by editing configuration files and restarting the server, with secure storage of connection details to enhance security. Clearing your local machine’s DNS cache and setting up conditional forwarders on Hub VNET for customizing the DNS Server may help solve these issues.
As database performance is heavily influenced by the performance of storage, network, memory, and processors, we must understand the upper limit of these key components. There are several ways to find out this information with the easiest way being by referring to the documentation. For storage, FIO is generally used.
On the contrary, a native application of an e-commerce store can come at 30, 50, or even 100 MB and up, consuming internal device storage. Due to the use of modern frameworks, advanced caching and rendering, and data transmission via API, properly developed PWAs can be a seven-league step up to boost the store’s speed. Large preview ).
Obviously, there are ways to monitor the backup through storage monitoring or Pod status, but why bother if the Operator already provides this information? 274] "discovery finished, cache updated" I0706 14:43:28.285652 1 metrics_handler.go:99] Configuration derived for the three metrics discussed above can be found here.
Search Engine And Web Archive Cached Results. Another common category of imposter domains are domains used by search engines for delivering cached results or archived versions of page views. The message that appears above a cached search result in Google’s search service. Large preview ). Large preview ). on a regular basis?
Alternatively, you can upload output directory to cloud object/blob storage such as Amazon S3 or Azure Blob Storage and serve your site from there. Most of cloud object/blob storage services have native support for static site hosting. Circa 2014, I was working with a big Japanese automotive brand in Australia.
now has a version which will support parallelism for SELECT queries (utilizing the read capacity of storage nodes underneath the Aurora cluster). Aurora Parallel Query response time (for queries which can not use indexes) can be 5x-10x better compared to the non-parallel fully cached operations. Documentation: [link].
HammerDB is Free software and consequently engineers should consider not only how they can benefit from using the software but also how they can contribute to the community with code and documentation. Cached vs Scaled Workloads. Instead, most users prefer to implement a cached workload.
Unless a site is installed to the home screen as a PWA , any single page is just another in a series of documents that users experience as a river of links. A then-representative $200USD device had 4-8 slow (in-order, low-cache) cores, ~2GiB of RAM, and relatively slow MLC NAND flash storage. The Moto G4 , for example.
This isn’t true (more on that in a follow-up post), and sites which are built this way implicitly require more script in each document (e.g., The server sends it as a stream of bytes and when the browser encounters each of the sub-resources referenced in the document, it requests them. for router components). Parsing CSS.
It can be activated from SQL Server 2008 to 2014 inclusive using documented trace flag 610. FastLoadContext can be disabled on SQL Server 2016 using documented trace flag 692. GO. -- Clear the plan cache. GO. -- Clear the plan cache. We must also remember the final storage engine test for at least 100 rows: I >= 100.
For an example, see Craig Freedman’s article Read Committed and Updates on the Microsoft documentation site. Microsoft’s Craig Freedman gave some examples in blog posts now hosted on the Microsoft documentation site: Read Committed and Bookmark Lookup. Lock classes. SQL Server solves this problem using lock classes.
Make sure the drives are mounted with noatime and also if the drives are behind a RAID controller with appropriate battery-backed cache. For example: Read/Write tickets WiredTiger uses tickets to control the number of read / write operations simultaneously processed by the storage engine. By default, it uses 50% of the memory + 1 GB.
Cons of logical backups As it reads all data, it can be slow and will require disk reads too for databases that are larger than the RAM available for the WT cache—the WT cache pressure increases, which slows down the performance. Especially if going into or out of storage types that may throttle bandwidth/network traffic.
Does your web application make use of local storage? If so, then like many developers you may well be making the assumption that when you read from local storage, it will only contain the data that you put there. There are two basic requirements for a storage-based XSS attack. As Steffens et al. no sanitisation) at a sink.
But doesn’t AppCache let you cachedocuments you might want offline? ” , you say, “doesn’t AppCache also allow you to put documents in the cache directly, bypassing all of that?” The legacy web, however, can take as long as the TCP timeout (2 minutes in many devices) to end in failure.
Chrome has missed several APIs for 3+ years: Storage Access API. An extension to Service Workers that enables browsers to present users with cached content when offline. A-series chips have run circles around other ARM parts for more than half a decade, largely through gobsmacking amounts of L2/L3 cache per core.
Stage – Instrument starting with ‘stage’ provides the execution stage of any query like reading data, sending data, altering table, checking query cache for queries, etc. It may be because of several reasons, for example, storage is full. For example stage/sql/altering table. I have not enabled any other instrument explicitly.
Copyright The information contained in this document represents the current view of Microsoft Corporation on the issues discussed as of the date of publication. Microsoft may have patents, patent applications, trademarks, copyrights, or other intellectual property rights covering subject matter in this document.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content