This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
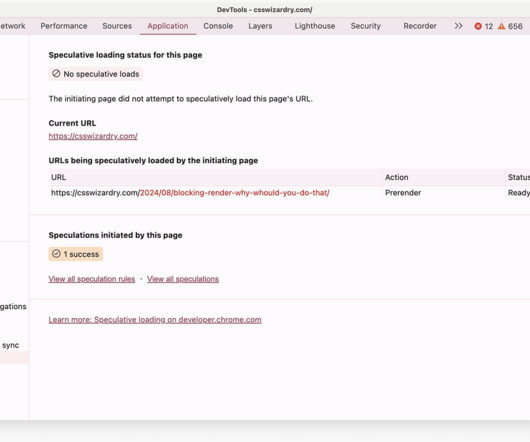
In this post, I’m going to break these processes down into each of: ? Caching them at the other end: How long should we cache files on a user’s device? Cache This is the easy one. Which brings me nicely on to… The important part of this section is cache busting. main.af8a22.css main.af8a22.css
It allows users to choose between different counting modes, such as Best-Effort or Eventually Consistent , while considering the documented trade-offs of each option. Best Effort Regional Counter This type of counter is powered by EVCache , Netflix’s distributed caching solution built on the widely popular Memcached.
For the longest time now, I have been obsessed with caching. I think every developer of any discipline would agree that caching is important, but I do tend to find that, particularly with web developers, gaps in knowledge leave a lot of opportunities for optimisation on the table. Want to know everything (and more) about HTTP cache?
Consider these examples from the updated documentation: You can choose the right level of runtime configurability versus fixed deployments by mixing Parameters and Configs. Take a look at two interesting examples of this pattern in the documentation. this could take a few minutes) All packages already cached in s3.
KeyCDN has significantly simplified the way images are transformed and delivered with our Image Processing service. Our Image Processing service makes it easy to do that. Our Image Processing service will automatically optimize the image quality and reduce the size of the image if no query string is provided.
It provides simple APIs for creating indices, indexing or searching documents, which makes it easy to integrate. Mapping is used to define how documents and their fields are supposed to be stored and indexed. All the assets of a specific type use the specific index defined for that asset type to create or update the asset document.
Amazon compute solutions are designed to streamline resource provisioning and container management with two services: AWS Lambda : Lambda provides serverless compute infrastructure that lets you run code in response to predetermined events or conditions and automatically manage all compute resources required for these processes. Data Store.
Spring Boot 2 uses Micrometer as its default application metrics collector and automatically registers metrics for a wide variety of technologies, like JVM, CPU Usage, Spring MVC, and WebFlux request latencies, cache utilization, data source utilization, Rabbit MQ connection factories, and more. To learn more, see our documentation.
Of the organizations in the Kubernetes survey, 71% run databases and caches in Kubernetes, representing a +48% year-over-year increase. Together with messaging systems (+36% growth), organizations are increasingly using databases and caches to persist application workload states.
The RAG process begins by summarizing and converting user prompts into queries that are sent to a search platform that uses semantic similarities to find relevant data in vector databases, semantic caches, or other online data sources. Observing AI models Running AI models at scale can be resource-intensive.
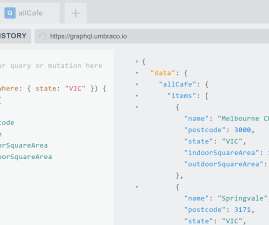
By batching and parallelizing the requests to retrieve many creatives via a single query to the GraphQL server, we can optimize the index building process. Best of all, our page can load much faster since everything is cached in Elasticsearch. Keeping Everything Up To Date Indexing the data once isn’t enough.
Browsers will cache tools popular among vocal, leading-edge developers. There's plenty of space for caching most popular frameworks. The best available proxy data also suggests that shared caches would have a minimal positive effect on performance. Browsers now understand the classic shared HTTP cache behaviour as a privacy bug.
In practice, session recording solutions make use of the document object model (DOM), which is a programming interface for web pages and document. Replays provide on-demand data about where conversion processes aren’t working. Streamlined asset caching: Asset caching is critical for creating accurate replays.
While this strategy is effective, it’s not simple: highly dynamic sites can be difficult to extract styles from, the process needs to be automated, we have to make assumptions about what above the fold even is, it’s hard to capture edge cases, and tooling still in its relative infancy.
Workloads using multi-threading and multi-processing, or performing many I/O operations, can experience lower execution time and, consequently, even lower costs based on execution time and configured memory size. See our documentation for more details on getting started or sign up for a free 15-day trial.
Moreover, features like Instant Run and the Gradle Build Cache weren’t supported. Out-of-the-box support for Instant Run and the Gradle Build Cache make the auto-instrumentation process barely noticeable. Performance-wise, bytecode instrumentation is a fast process that doesn’t impact build time.
Many Dynatrace monitoring environments now include well beyond 10,000 monitored hosts—and the number of processes and services has multiplied to millions of monitored entities. Best practice: Reduce bandwidth consumption by caching and keeping information. Dynatrace news.
This allows the app to query a list of “paths” in each HTTP request, and get specially formatted JSON (jsonGraph) that we use to cache the data and hydrate the UI. You can find a lot more details about how this works in the Spinnaker canaries documentation. This meant that data that was static (e.g.
To fix this, we've improved support for React Server Components (RSC) and added prefetch helpers to make it easier to utilize the power of RSCs running exclusively on the server, in combination with the highly dynamic client-side cache of React Query. You can read more in our Server Components documentation. ts // @filename: server.ts
Our UI runs on top of a custom rendering engine which uses what we call a “surface cache” to optimize our use of graphics memory. Surface Cache Surface cache is a reserved pool in main memory (or separate graphics memory on a minority of systems) that the Netflix app uses for storing textures (decoded images and cached resources).
Source: OpenTelemetry Documentation. This information is gathered from remote, often inaccessible points within your ecosystem and processed by some sort of tool or equipment. Traces are the act of following a process (for example, an API request or other system activity) from start to finish, showing how services connect.
To further exacerbate the problem, the 302 response has a Cache-Control: must-revalidate, private. header , meaning that we will always make an outgoing request for this resource regardless of whether or not we’re hitting the site from a cold or a warm cache. There was no appetite for providing or even documenting the alternative (i.e.
The default storage engine in earlier versions was MMAPv1, which utilized memory-mapped files and document-level locking. It uses a filesystem cache and write-ahead log for crash recovery. MongoDB makes use of both the filesystem cache and the WiredTiger internal cache. released in December 2015.
The unique Dynatrace OneAgent for Go monitoring allows you to monitor your statically linked Go processes in the same way as is already possible for dynamically linked Go processes. The next step for all Go applications is to create a process-monitoring rule that enables deep monitoring of each statically linked Go application.
Spring Boot 2 uses Micrometer as its default application metrics collector and automatically registers metrics for a wide variety of technologies, like JVM, CPU Usage, Spring MVC, and WebFlux request latencies, cache utilization, data source utilization, Rabbit MQ connection factories, and more. To learn more, see our documentation.
Spring Boot 2 uses Micrometer as its default application metrics collector and automatically registers metrics for a wide variety of technologies, like JVM, CPU Usage, Spring MVC, and WebFlux request latencies, cache utilization, data source utilization, Rabbit MQ connection factories, and more. To learn more, see our documentation.
Moving to a headless CMS is not an easy decision and the selection process should not be taken lightly. The process of defining this sound, logical taxonomy structure for the content items you create and publish is known as content modeling. Comprehensive documentation and code samples are also a must.
In response to these needs, developers now have the choice of relational, key-value, document, graph, in-memory, and search databases. Document: Document databases are intuitive for developers to use because the data in the application tier is typically represented as a JSON document. Build on.
This can be reduced by a proper code-review process. You can check out the documentation to get started with Hygen. Check out their documentation regarding how to get started with Redux Toolkit. Your application might also suffer from caching, and performance issues. applications.
This allows resource requests, including the HTML document itself, to be enriched with data during its lifecycle, and that information can be inspected for measuring the attributes of that resource! For the top-level HTML document, it is fetched upon user navigation but is still a resource request.
Every unnecessary bit of JavaScript code you bundle and serve will be more code the client has to load and process. Jamstack is popular with documentation sites that usually compile code to HTML files and host them on the CDN. Active Memory Caching. Caching partially stores your data and is not used as permanent storage.
Zombies probably won’t consume 32 GB of your memory like they did to me, but zombie processes do exist, and I can help you find them and make sure that developers fix them. He’d even written a tool that would dump a list of zombie processes – their names and counts. I ran his tool and it showed 506,000 zombie processes!
The service workers enable the offline usage of the PWA by fetching cached data or informing the user about the absence of an Internet connection. When developing a PWA, you can cache the application shell’s resources and assets in the browser. Cached content with IndexedDB. Cache first, then network. Service Workers.
Modern software loves to use additional processes so I wasn’t surprised when the busiest process wasn’t SoundRec.exe , but the verbosely named “RuntimeBroker.exe <Microsoft.WindowsSoundRecorder>”. but it appears that RuntimeBroker was – on the same thread – scanning part or all of my documents directory.
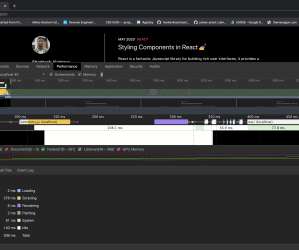
The Four LCP Subparts LCP subparts split the Largest Contentful Paint metric into four different components: Time to First Byte (TTFB) : How quickly the server responds to the document request. Large preview ) Time To First Byte The first step to display the largest page element is fetching the document HTML.
The service extracts these fields from events as they stream in, indexing the resultant documents into Elasticsearch. Once a range of data becomes immutable, we can safely do things like caching, compressing, and compacting it for reads. Buffering Writes We frequently leverage this service for handling bursty workloads.
Nonetheless, we found a number of limitations that could not satisfy our requirements e.g. stalling the processing of log events until a dump is complete, missing ability to trigger dumps on demand, or implementations that block write traffic by using table locks. Some of DBLog’s features are: Processes captured log events in-order.
Nonetheless, we found a number of limitations that could not satisfy our requirements e.g. stalling the processing of log events until a dump is complete, missing ability to trigger dumps on demand, or implementations that block write traffic by using table locks. Some of DBLog’s features are: Processes captured log events in-order.
Windows has long had a reputation for slow file operations and slow process creation. This weeks’ blog post covers a technique you can use to make process creation on Windows grow slower over time (with no limit), in a way that will be untraceable for most users! A long-standing correctness bug in the Windows file cache: Compiler bug?
Let’s look at some questions I did that a MySQL DBA usually needs to answer in an interview process. ChatGPT: The InnoDB buffer pool is used by MySQL to cache frequently accessed data in memory. If we expand the cache concept more, the buffer pool could be even less if the working set (hot data) is smaller.
Its performance will depend on how you use React when building it, and on your understanding of how React operates and the process through which components live through the various phases of their lifecycle. During the initial rendering process, React builds a DOM tree of components. Note : See the documentation for more information.
How well does AMP perform when the library is served using the AMP cache? But what you don’t see is that Google gets that instantaneous loading by actively preloading AMP documents in the background. In the case of the search carousel, it’s literally an iframe that gets populated with the entirety of the AMP document.
Simple parameterization has a number of quirks in this area, which can result in more parameterized plans being cached than expected, or finding different results compared with the unparameterized version. Reputation = 252552 ; These statements result in six cached plans, three Adhoc and three Prepared : Different guessed types.
By batching and parallelizing the requests to retrieve many creatives via a single query to the GraphQL server, we can optimize the index building process. Best of all, our page can load much faster since everything is cached in Elasticsearch. Keeping Everything Up To Date Indexing the data once isn’t enough.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content