This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Caching them at the other end: How long should we cache files on a user’s device? Plotted on the same horizontal axis of 1.6s, the waterfalls speak for themselves: 201ms of cumulative latency; 109ms of cumulative download. 4,362ms of cumulative latency; 240ms of cumulative download. Cache This is the easy one.
By: Rajiv Shringi , Oleksii Tkachuk , Kartik Sathyanarayanan Introduction In our previous blog post, we introduced Netflix’s TimeSeries Abstraction , a distributed service designed to store and query large volumes of temporal event data with low millisecond latencies. Today, we’re excited to present the Distributed Counter Abstraction.
We note that for MongoDB update latency is really very low (low is better) compared to other dbs, however the read latency is on the higher side. The latency table shows that 99th percentile latency for Yugabyte is quite high compared to others (lower is better). Again Yugabyte latency is quite high. Conclusion.
Spring Boot 2 uses Micrometer as its default application metrics collector and automatically registers metrics for a wide variety of technologies, like JVM, CPU Usage, Spring MVC, and WebFlux request latencies, cache utilization, data source utilization, Rabbit MQ connection factories, and more. To learn more, see our documentation.
Generating the HTML document quickly plays a big part in minimizing TTFB delays. That means TTFB includes: Cross-origin redirects, Time spent connecting to the server, Same-origin redirects, and The actual request for the HTML document. On a high-latency connection with a 150 millisecond RTT, making those eight round trips will take 1.2
The RAG process begins by summarizing and converting user prompts into queries that are sent to a search platform that uses semantic similarities to find relevant data in vector databases, semantic caches, or other online data sources.
This allows the app to query a list of “paths” in each HTTP request, and get specially formatted JSON (jsonGraph) that we use to cache the data and hydrate the UI. You can find a lot more details about how this works in the Spinnaker canaries documentation. This meant that data that was static (e.g.
Rajiv Shringi Vinay Chella Kaidan Fullerton Oleksii Tkachuk Joey Lynch Introduction As Netflix continues to expand and diversify into various sectors like Video on Demand and Gaming , the ability to ingest and store vast amounts of temporal data — often reaching petabytes — with millisecond access latency has become increasingly vital.
But we cannot search or present low latency retrievals from files Etc. We store all OperationIDs which are in STARTED state in a distributed cache (EVCache) for fast access during searches. This API finds all Elasticsearch documents with ID1 and marks isAnnotationOperationActive=FALSE. This is obviously very expensive.
To further exacerbate the problem, the 302 response has a Cache-Control: must-revalidate, private. header , meaning that we will always make an outgoing request for this resource regardless of whether or not we’re hitting the site from a cold or a warm cache. com , which introduces yet more latency for the connection setup.
Best of all, our page can load much faster since everything is cached in Elasticsearch. Listening to Kafka events adds little latency, our fan out operations are really quick since we store foreign keys to identify the edges, and looking up data in an inverted index is fast as well. Our data changes constantly?—?
In response to these needs, developers now have the choice of relational, key-value, document, graph, in-memory, and search databases. Use cases such as gaming, ad tech, and IoT lend themselves particularly well to the key-value data model where the access patterns require low-latency Gets/Puts for known key values.
Spring Boot 2 uses Micrometer as its default application metrics collector and automatically registers metrics for a wide variety of technologies, like JVM, CPU Usage, Spring MVC, and WebFlux request latencies, cache utilization, data source utilization, Rabbit MQ connection factories, and more. To learn more, see our documentation.
Spring Boot 2 uses Micrometer as its default application metrics collector and automatically registers metrics for a wide variety of technologies, like JVM, CPU Usage, Spring MVC, and WebFlux request latencies, cache utilization, data source utilization, Rabbit MQ connection factories, and more. To learn more, see our documentation.
The default storage engine in earlier versions was MMAPv1, which utilized memory-mapped files and document-level locking. In-Memory Storage Engine, as the name suggests, stores data in memory for faster performance and lower latencies. It uses a filesystem cache and write-ahead log for crash recovery. released in December 2015.
This allows resource requests, including the HTML document itself, to be enriched with data during its lifecycle, and that information can be inspected for measuring the attributes of that resource! For the top-level HTML document, it is fetched upon user navigation but is still a resource request.
When deciding what to pick, there are many things to consider, like where the proxy needs to be, if it “just” needs to redirect the connections, or if more features need to be in, like caching and filtering, or if it needs to be integrated with some MySQL embedded automation. Given that, there never was a single straight answer.
Amazon DynamoDB offers low, predictable latencies at any scale. This is not just predictability of median performance and latency, but also at the end of the distribution (the 99.9th percentile), so we could provide acceptable performance for virtually every customer. s read latency, particularly as dataset sizes grow.
Jamstack is popular with documentation sites that usually compile code to HTML files and host them on the CDN. Active Memory Caching. When you want to get data that you already had quickly, you need to do caching — caching stores data that a user recently retrieved. Caching Schemes. Caching Schemes.
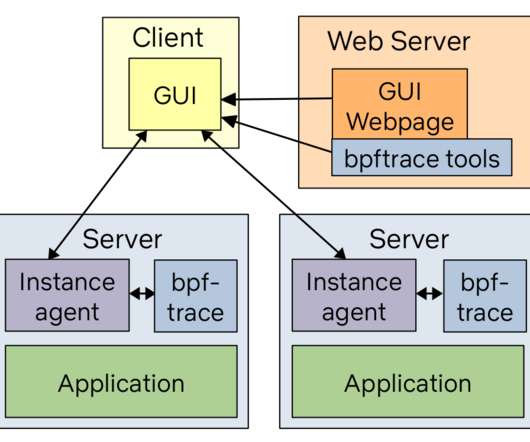
biolatency Disk I/O latency histogram heat map. cachestat File system cache statistics line charts. runqlat CPU scheduler latency heat map. There is already documentation as man pages and example files in the bcc and bpftrace repositories that you can link to, to help your customers understand the tool output.
ChatGPT: The InnoDB buffer pool is used by MySQL to cache frequently accessed data in memory. If we expand the cache concept more, the buffer pool could be even less if the working set (hot data) is smaller. Also, there is a documented bug: OPTIMIZE TABLE does not sort R-tree indexes, such as spatial indexes on POINT columns.
The mean and percentile measurements hide this structure, but the rest of this post will show how the structure can be measured and analyzed so that you can figure out a useful model of your system, understand what is driving the long tail of latencies and come up with better SLAs and measures of capacity.
All these resource hints use the rel attribute of the <link> element that you’ll be familiar with finding in the <head> of your HTML documents. The browser caches the results of these lookups, but they can be slow. You might think of a prefetch as being a bit like adding a file to the browser’s cache.
Best of all, our page can load much faster since everything is cached in Elasticsearch. Listening to Kafka events adds little latency, our fan out operations are really quick since we store foreign keys to identify the edges, and looking up data in an inverted index is fast as well. Our data changes constantly?—?
Redirects are often pretty light in terms of the latency that they add to a website, but they are an easy first thing to check, and they can generally be removed with little effort. I’m going to update my referenced URL to the new site to help decrease latency that adds drag to the initial page load. Text-based assets.
What’s interesting is there was little mention of static sites in MoveableType’s documentation at all. These use cases include: Documentation. Developers expect a lot from documentation sites, and a good experience will help win them over. Markdown is an excellent format for Documentation made even easier with a good CMS.
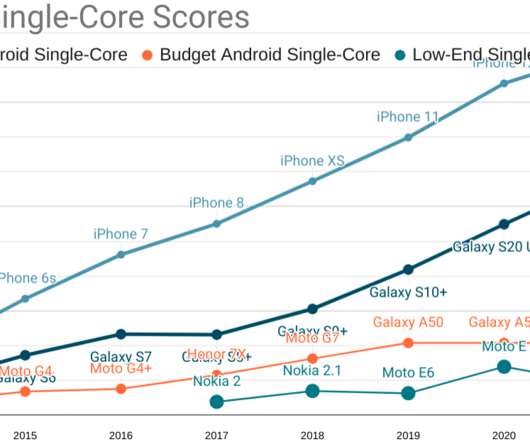
The talks are up on YouTube , including my own (behind a paywall, but the slides are freely available [1] ): The talk, like this post, is an update on network and CPU realities this series has documented since 2017. More importantly, it is also a look at what the latest data means for our collective performance budgets. 4GiB of RAM.
Best of all, our page can load much faster since everything is cached in Elasticsearch. Listening to Kafka events adds little latency, our fan out operations are really quick since we store foreign keys to identify the edges, and looking up data in an inverted index is fast as well. Our data changes constantly?—?
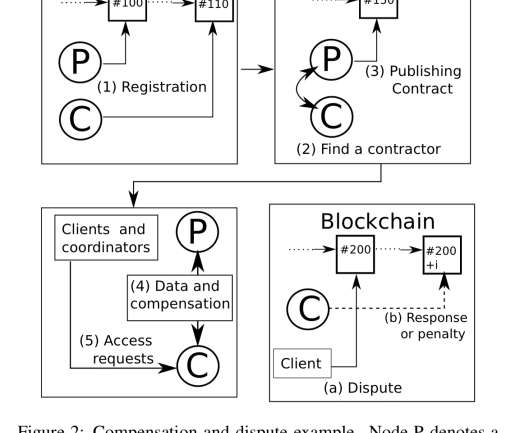
Caching of query results on the other hand, looks like a good business model, at large enough scale these might amount to pretty much the same thing). How’s that going to work given what we know about the throughput and latency of blockchains, and the associated mining costs?" An embodiment for structured data for IoT.
While dynamic serving provides simplicity in implementation, it imposes significant time costs due to the computational resources required to generate the pages and the latency involved in serving these pages to users at distant locations. The shorter the TTFB, the better the perceived speed of the site from the user’s perspective.
This way, log event processing can resume event-by-event afterwards, eventually discovering the watermarks, without ever needing to cache log event entries. Passive instances across regions are also possible, though it is recommended to operate in the same region as the database host in order to keep the change capture latencies low.
This way, log event processing can resume event-by-event afterwards, eventually discovering the watermarks, without ever needing to cache log event entries. Passive instances across regions are also possible, though it is recommended to operate in the same region as the database host in order to keep the change capture latencies low.
1 among non-relational/document-based systems ( DB-Engines, July 2023 ). Instead of the table-based structure of relational databases, MongoDB stores data in documents and collections, a design for handling large amounts of unstructured data and for real-time web applications. It ranks No.
Unless a site is installed to the home screen as a PWA , any single page is just another in a series of documents that users experience as a river of links. A then-representative $200USD device had 4-8 slow (in-order, low-cache) cores, ~2GiB of RAM, and relatively slow MLC NAND flash storage. The Moto G4 , for example.
This isn’t true (more on that in a follow-up post), and sites which are built this way implicitly require more script in each document (e.g., The server sends it as a stream of bytes and when the browser encounters each of the sub-resources referenced in the document, it requests them. for router components). Parsing CSS.
Short durations can be useful for understanding how well a WSS will fit into the CPU caches (L1/L2/L3, TLB L1/L2, etc). In this case, 28 Mbytes is a little larger than the LLC for this CPU, so may not cache so well (in a single LLC, anyway, and based on this single measurement). Why did I use a 100 ms interval? 16.570 403.66
Using CDN for the whole website, you can offload most of the website traffic to your CDN which will handle not only large traffic spikes but also reduce the latency of content delivery. They were using a very legacy CMS or more precisely a document management system which was painful to work with.
This approach was touted to be better for fine-grained caching because each subresource could be cached individually and the full bundle didn’t need to be redownloaded if one of them changed. Finally, not inlining resources has an added latency cost because the file needs to be requested. What Does It All Mean? Large preview ).
For heavily latency-sensitive use-cases like WebXR, this is a critical component in delivering a good experience. An extension to Service Workers that enables browsers to present users with cached content when offline. In the days that followed, belated documentation included a shocking revelation: against all expectations, iOS 14.5
The CFQ works well for many general use cases but lacks latency guarantees. The deadline excels at latency-sensitive use cases ( like databases ), and noop is closer to no schedule at all. Make sure the drives are mounted with noatime and also if the drives are behind a RAID controller with appropriate battery-backed cache.
The benchmarks are documented in the Blackwell Architecture Technical Brief and some screenshots of the GTC keynote, and Ill break those out and try to explain whats really going on from a benchmarketing approach. The configuration is documented in the following figure. we would expect.
Real-time software system – Collaboration tools used for video/audio conferencing, document writing, Chat applications, etc. with its low latency I/O operations, gives the benefit of ‘No buffering’ to developers. Performance: React uses Virtual DOM (document object model), which improves the performance of applications.
You can find more information about modifying this file within your server’s documentation. Because HTTP redirection is handled server-side, it is typically faster than client-side redirection, especially if the browser can cache the new location of the requested file. Implementing this requires access to your server’s.htaccess file.
Copyright The information contained in this document represents the current view of Microsoft Corporation on the issues discussed as of the date of publication. Microsoft may have patents, patent applications, trademarks, copyrights, or other intellectual property rights covering subject matter in this document.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content