This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
By: Rajiv Shringi , Oleksii Tkachuk , Kartik Sathyanarayanan Introduction In our previous blog post, we introduced Netflix’s TimeSeries Abstraction , a distributed service designed to store and query large volumes of temporal event data with low millisecond latencies. Today, we’re excited to present the Distributed Counter Abstraction.
Caching them at the other end: How long should we cache files on a user’s device? Plotted on the same horizontal axis of 1.6s, the waterfalls speak for themselves: 201ms of cumulative latency; 109ms of cumulative download. 4,362ms of cumulative latency; 240ms of cumulative download. Cache This is the easy one.
This gives fascinating insights into the network topography of our visitors, and how much we might be impacted by high latency regions. Round-trip-time (RTT) is basically a measure of latency—how long did it take to get from one endpoint to another and back again? What is RTT? Where Does CrUX’s RTT Data Come From?
Design a photo-sharing platform similar to Instagram where users can upload their photos and share it with their followers. High Level Design. Component Design. API Design. We have provided the API design of posting an image on Instagram below. API Design. Problem Statement. Architecture. Fetching User Feed.
We introduce a caching mechanism in the API gateway layer, allowing us to offload processing from singleton leader elected controllers without giving up strict data consistency and guarantees clients observe. We started seeing increased response latencies and leader servers running at dangerously high utilization.
Caching is a critical technique for optimizing application performance by temporarily storing frequently accessed data, allowing for faster retrieval during subsequent requests. Multi-layered caching involves using multiple levels of cache to store and retrieve data.
How To Design For High-Traffic Events And Prevent Your Website From Crashing How To Design For High-Traffic Events And Prevent Your Website From Crashing Saad Khan 2025-01-07T14:00:00+00:00 2025-01-07T22:04:48+00:00 This article is sponsored by Cloudways Product launches and sales typically attract large volumes of traffic.
Yet, many are confined to a brief temporal window due to constraints in serving latency or training costs. These insights have shaped the design of our foundation model, enabling a transition from maintaining numerous small, specialized models to building a scalable, efficient system.
We note that for MongoDB update latency is really very low (low is better) compared to other dbs, however the read latency is on the higher side. The latency table shows that 99th percentile latency for Yugabyte is quite high compared to others (lower is better). Again Yugabyte latency is quite high. Conclusion.
These include challenges with tail latency and idempotency, managing “wide” partitions with many rows, handling single large “fat” columns, and slow response pagination. It also serves as central configuration of access patterns such as consistency or latency targets.
Users might already have the file cached. If website-a.com links to [link] , and a user goes from there to website-b.com who also links to [link] , then the user will already have that file in their cache. On a slower, higher-latency connection, the story is much, mush worse. Penalty: Caching. All completely avoidable.
Because microprocessors are so fast, computer architecture design has evolved towards adding various levels of caching between compute units and the main memory, in order to hide the latency of bringing the bits to the brains. This avoids thrashing caches too much for B and evens out the pressure on the L3 caches of the machine.
The RAG process begins by summarizing and converting user prompts into queries that are sent to a search platform that uses semantic similarities to find relevant data in vector databases, semantic caches, or other online data sources.
Uploading and downloading data always come with a penalty, namely latency. Figure 2: Cloud Resource and Job Sizes This initial architecture was designed at a time when packaging from a list of chunks was not possible and terabyte-sized files were not considered. For write operations, those challenges do not apply.
This allows the app to query a list of “paths” in each HTTP request, and get specially formatted JSON (jsonGraph) that we use to cache the data and hydrate the UI. Being able to canary a new route let us verify latency and error rates were within acceptable limits. This meant that data that was static (e.g.
To support this growth, we’ve revisited Pushy’s past assumptions and design decisions with an eye towards both Pushy’s future role and future stability. In our case, we value low latency — the faster we can read from KeyValue, the faster these messages can get delivered.
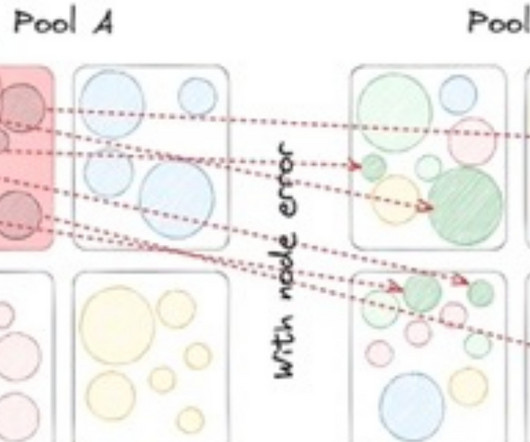
Rajiv Shringi Vinay Chella Kaidan Fullerton Oleksii Tkachuk Joey Lynch Introduction As Netflix continues to expand and diversify into various sectors like Video on Demand and Gaming , the ability to ingest and store vast amounts of temporal data — often reaching petabytes — with millisecond access latency has become increasingly vital.
We designed a unique concept called Annotation Operations which allows teams to create data pipelines and easily write annotations without worrying about access patterns of their data from different applications. But we cannot search or present low latency retrievals from files Etc. This is obviously very expensive.
Since its inception , Metaflow has been designed to provide a human-friendly API for building data and ML (and today AI) applications and deploying them in our production infrastructure frictionlessly. Deployment: Cache To produce business value, all our Metaflow projects are deployed to work with other production systems.
Key Takeaways Critical performance indicators such as latency, CPU usage, memory utilization, hit rate, and number of connected clients/slaves/evictions must be monitored to maintain Redis’s high throughput and low latency capabilities. It can achieve impressive performance, handling up to 50 million operations per second.
To further exacerbate the problem, the 302 response has a Cache-Control: must-revalidate, private. header , meaning that we will always make an outgoing request for this resource regardless of whether or not we’re hitting the site from a cold or a warm cache. com , which introduces yet more latency for the connection setup.
This is a set of best practices and guidelines that help you design and operate reliable, secure, efficient, cost-effective, and sustainable systems in the cloud. Storing frequently accessed data in faster storage, usually in-memory caching, improves data retrieval speed and overall system performance. Beyond
RevenueCat extensively uses caching to improve the availability and performance of its product API while ensuring consistency. The company shared its techniques to deliver the platform, which can handle over 1.2 billion daily API requests. The team at RevenueCat created an open-source memcache client that provides several advanced features.
Amazon ElastiCache is a fully managed, in-memory caching service for customers to optimize the latency, performance and cost of their read workloads. Today, we are further expanding the choices available for designing and developing highly scalable and high performance apps.
Video encoding is what MezzFS was originally designed for and remains one of its canonical use cases, so we’ll focus on video encoding to describe the problem that MezzFS solves. Disk Caching? — ? MezzFS can be configured to cache objects on the local disk. Regional caching? —?Netflix What problem are we solving?
a Fast and Scalable NoSQL Database Service Designed for Internet Scale Applications. Today is a very exciting day as we release Amazon DynamoDB , a fast, highly reliable and cost-effective NoSQL database service designed for internet scale applications. Amazon DynamoDB offers low, predictable latencies at any scale. Comments ().
Data lakehouses deliver the query response with minimal latency. Designed to provide a single source of truth for structured data, they offer a way for organizations to simplify data management by centralizing inputs. The performance of these queries needs to be at a level where they can support ad-hoc analytics use cases.
.’ Stateless is fine until you need state, at which point the coarse-grained solutions offered by current platforms limit the kinds of application designs that work well. On the Cloudburst design teams’ wish list: A running function’s ‘hot’ data should be kept physically nearby for low-latency access.
The fact that this shows up as CPU time suggests that the reads were all hitting in the system cache and the CPU time was the kernel overhead (note ntoskrnl.exe on the first sampled call stack) of grabbing data from the cache. This means that there is no caching between RuntimeBroker.exe and this file.
Key Takeaways Redis offers complex data structures and additional features for versatile data handling, while Memcached excels in simplicity with a fast, multi-threaded architecture for basic caching needs. Redis is better suited for complex data models, and Memcached is better suited for high-throughput, string-based caching scenarios.
When designing an architecture, many components need to be considered before deciding on the best solution. In this context, features like filtering, firewalling, or caching are redundant and may consume resources that could be allocated to scaling. MySQL Router is the one that has the higher latency no matter what.
As developers, we rightfully obsess about the customer experience, relentlessly working to squeeze every millisecond out of the critical rendering path, optimize input latency, and eliminate jank. On top of this foundation, we add layers of caching, prerendering and edge delivery optimizations — not the other way around.
Today, I'm excited to announce the general availability of Amazon DynamoDB Accelerator (DAX) , a fully managed, highly available, in-memory cache that can speed up DynamoDB response times from milliseconds to microseconds, even at millions of requests per second. Adding caching when your app is already experiencing load is not easy.
Streams provide you with the underlying infrastructure to create new applications, such as continuously updated free-text search indexes, caches, or other creative extensions requiring up-to-date table changes. DynamoDB Streams simplifies and improves this design pattern with a distributed systems approach.
Further, with the growth and scale of Amazon.com, boundless horizontal scale needed to be a key design point--scaling up simply wasn't an option. Use cases such as gaming, ad tech, and IoT lend themselves particularly well to the key-value data model where the access patterns require low-latency Gets/Puts for known key values.
There are two main types of DNS servers: authoritative servers and caching resolvers. But the real robustness of the DNS system comes through the way lookups are handled, which is what caching resolvers do. Caching techniques ensure that the DNS system doesnt get overloaded with queries. Recent Entries. Amazon DynamoDB â??
Why are developers using RInK systems as part of their design? Generally to cache data (including non-persistent data that never sees a backing store), to share non-persistent data across application services (e.g. The network latency of fetching data over the network, even considering fast data center networks. Who knew! ;).
My personal opinion is that I don't see a widespread need for more capacity given horizontal scaling and servers that can already exceed 1 Tbyte of DRAM; bandwidth is also helpful, but I'd be concerned about the increased latency for adding a hop to more memory. Ford, et al., “TCP
LinkedIn introduced Couchbase as a centralized caching tier for scaling member profile reads to handle increasing traffic that has outgrown their existing database cluster. The new solution achieved over 99% hit rate, helped reduce tail latencies by more than 60% and costs by 10% annually. By Rafal Gancarz
About 5 years ago, I introduced you to AWS Availability Zones, which are distinct locations within a Region that are engineered to be insulated from failures in other Availability Zones and provide inexpensive, low latency network connectivity to other Availability Zones in the same region.
For most high-end processors these values have remained in the range of 75% to 85% of the peak DRAM bandwidth of the system over the past 15-20 years — an amazing accomplishment given the increase in core count (with its associated cache coherence issues), number of DRAM channels, and ever-increasing pipelining of the DRAMs themselves.
There are several pressures on such a design: The volume of data continues to grow – by another 2 orders of magnitude this decade according to IDC – as does the velocity of data arrival and the variance in arrival rates. It’s limited by the laws of physics in terms of end-to-end latency. Emphasis mine ).
Prediction serving latency matters. Lesson 4: prediction serving latency matters. In a experiment introducing synthetic latency, Booking.com found that an increase of about 30% in latency cost about 0.5% Even mathematically simple models have the potential of introducing relevant latency.
Due to the design of web browser APIs, there are currently no mechanisms for querying requests and their relative responses after the fact. Here are a few that come to mind: Is this request served from the service worker cache? How long has a resource been in service worker cache? No References Required.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content