This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
For example, when monitoring a database, you’ll want to know about any latency when writing data to a disk or average query response time. Examples include a spike in memory utilization, a decrease in cache hit ratio, or an increase in CPU utilization. The post Observability vs. monitoring: What’s the difference?
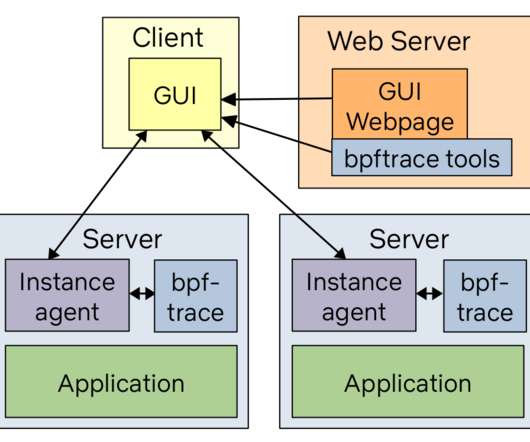
biolatency Disk I/O latency histogram heat map. cachestat File system cache statistics line charts. runqlat CPU scheduler latency heat map. In a previous blog post, [An Unbelievable Demo], I talked about how something similar happened many years ago where old tracing tool versions were used without updates.
My personal opinion is that I don't see a widespread need for more capacity given horizontal scaling and servers that can already exceed 1 Tbyte of DRAM; bandwidth is also helpful, but I'd be concerned about the increased latency for adding a hop to more memory. Ford, et al., “TCP
The mean and percentile measurements hide this structure, but the rest of this post will show how the structure can be measured and analyzed so that you can figure out a useful model of your system, understand what is driving the long tail of latencies and come up with better SLAs and measures of capacity. For this demo on an old MacBook (2.7
My personal opinion is that I don't see a widespread need for more capacity given horizontal scaling and servers that can already exceed 1 Tbyte of DRAM; bandwidth is also helpful, but I'd be concerned about the increased latency for adding a hop to more memory. Ford, et al., “TCP
biolatency Disk I/O latency histogram heat map 5. cachestat File system cache statistics line charts 7. runqlat CPU scheduler latency heat map 10. In a previous blog post, [An Unbelievable Demo], I talked about how something similar happened many years ago where old tracing tool versions were used without updates.
example.net --port=27017 --username=user --authenticationDatabase=admin --db=demo --collection=events --out=/opt/backup/mongodump-2011-10-24 Note : If we don’t specify the DB name or Collection name explicitly in the above “mongodump” syntax then the backup will be taken for the entire database or collections, respectively.
It’s widely accepted that self-hosted fonts are the fastest option: same origin means reduced network negotiation, predictable URLs mean we can preload , self-hosted means we can set our own cache-control. On a high-latency connection, this spells bad news. Put another-other way, this file is latency-bound, not bandwidth-bound.
Using CDN for the whole website, you can offload most of the website traffic to your CDN which will handle not only large traffic spikes but also reduce the latency of content delivery. They often get blindsided by vendor’s pitch and end-up making decision based on some fancy demos (see my post from 2014 on Adobe AEM ).
Estimated Input Latency tells us if we are hitting that threshold, and ideally, it should be below 50ms. Designed for the modern web, it responds to actual congestion, rather than packet loss like TCP does, it is significantly faster , with higher throughput and lower latency — and the algorithm works differently.
Estimated Input Latency tells us if we are hitting that threshold, and ideally, it should be below 50ms. PRPL stands for Pushing critical resource, Rendering initial route, Pre-caching remaining routes and Lazy-loading remaining routes on demand. An application shell is the minimal HTML, CSS, and JavaScript powering a user interface.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















Let's personalize your content