This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The strongest Kubernetes growth areas are security, databases, and CI/CD technologies. On-premises data centers invest in higher capacity servers since they provide more flexibility in the long run, while the procurement price of hardware is only one of many cost factors. Databases : Among databases, Redis is the most used at 60%.
These developments gradually highlight a system of relevant database building blocks with proven practical efficiency. In this article I’m trying to provide more or less systematic description of techniques related to distributed operations in NoSQL databases. Data Placement. System Coordination. Read/Write latency.
This means you no longer have to provision, scale, and maintain servers to run your applications, databases, and storage systems. Instead of worrying about infrastructure management functions, such as capacity provisioning and hardware maintenance, teams can focus on application design, deployment, and delivery. Simplicity. Data Store.
Infrastructure Optimization: 100% improvement in Database Connectivity. Reducing CPU Utilization to now only consume 15% of initially provisioned hardware. Missing Cache Settings – Make sure you cache resources that don’t change often on the browser or use a CDN.
a Fast and Scalable NoSQL Database Service Designed for Internet Scale Applications. Today is a very exciting day as we release Amazon DynamoDB , a fast, highly reliable and cost-effective NoSQL database service designed for internet scale applications. Werner Vogels weblog on building scalable and robust distributed systems.
Where you decide to host your cloud databases is a huge decision. But, if you’re considering leveraging a managed databases provider, you have another decision to make – are you able to host in your own cloud account or are you required to host through your managed service provider? Where to host your cloud database?
To make data count and to ensure cloud computing is unabated, companies and organizations must have highly available databases. A basic high availability database system provides failover (preferably automatic) from a primary database node to redundant nodes within a cluster. HA is sometimes confused with “fault tolerance.”
I am excited to share with you that today we are expanding DynamoDB with streams, cross-region replication, and database triggers. Streams provide you with the underlying infrastructure to create new applications, such as continuously updated free-text search indexes, caches, or other creative extensions requiring up-to-date table changes.
only to find that the resource they’re requesting isn’t in that PoP ’s cache. Database queries: Pages that require data from a database will incur a cost when searching over it. Routing: If you are using a CDN—and you should be!—a a customer in Leeds might get routed to the MAN datacentre.
Hardware Memory The amount of RAM to be provisioned for database servers can vary greatly depending on the size of the database and the specific requirements of the company. By caching hot datasets, indexes, and ongoing changes, InnoDB can provide faster response times and utilize disk IO in a much more optimal way.
On MySQL and Percona Server for MySQL , there is a schema called information_schema (I_S) which provides information about database tables, views, indexes, and more. The percentage in degradation will vary depending on many factors {hardware, workload, number of tables, configuration, etc.}.
Redis® is an in-memory database that provides blazingly fast performance. This makes it a compelling alternative to disk-based databases when performance is a concern. Redis returns a big list of database metrics when you run the info command on the Redis shell. This blog post lists the important database metrics to monitor.
As a MySQL database administrator, keeping a close eye on the performance of your MySQL server is crucial to ensure optimal database operations. This includes metrics such as query execution time, the number of queries executed per second, and the utilization of query cache and adaptive hash index.
Every database system has to ensure durability and reliability. ” This acts as a step to ensure durability by recovering lost data from the same journal files in case of crashes, power, and hardware failures between the checkpoints (see below) Here’s what the process looks like. wt and index-*.wt).
At the same time that I see database engineers relying on the tool, sites such as StackOverflow are banning ChatGPT. ChatGPT: The InnoDB buffer pool is used by MySQL to cache frequently accessed data in memory. If we expand the cache concept more, the buffer pool could be even less if the working set (hot data) is smaller.
Redis Monitoring Essentials Ensuring the performance, reliability, and safety of a Redis database requires active monitoring. With these essential support systems in place, you can effectively monitor your databases with up-to-date data about their health and functioning status at all times.
Maintaining rapidly changing data in back-end databases creates bottlenecks that impact responsiveness. In addition, repeatedly accessing back-end databases to serve up popular items, such as product descriptions and news stories, also adds to the bottleneck. The Solution: Distributed Caching.
Maintaining rapidly changing data in back-end databases creates bottlenecks that impact responsiveness. In addition, repeatedly accessing back-end databases to serve up popular items, such as product descriptions and news stories, also adds to the bottleneck. The Solution: Distributed Caching.
Why connect Power BI to a MySQL Database? Connecting Power BI to a MySQL database unlocks many benefits, enabling businesses to harness the full potential of their MySQL data. Selecting MySQL as the Data Source Click on the “Get Data” button and choose MySQL database as the data source from the available options.
Azure SQL Database is Microsoft's database-as-a-service offering that provides a tremendous amount of flexibility. Microsoft is continually working on improving their products and Azure SQL Database is no different. Gen 5 is the primary hardware option now for most regions since Gen 4 is aging out. HyperScale Database.
If you’re considering a database management system, understanding these benefits is crucial. DBMS enhances data security with encryption, implements various access controls, and enables improved data sharing and concurrent access, thus facilitating quick response to changes and maintaining consistent database accuracy.
Redis® Monitoring Essentials Ensuring the performance, reliability, and safety of a Redis® database requires active monitoring. With these essential support systems in place, you can effectively monitor your databases with up-to-date data about their health and functioning status at all times.
Hardware considerations The first thing we have to consider here is the resources that the underlying host provides to the database. Global caches like the InnoDB buffer pool and MyISAM key cache and session-level caches like the sort buffer, join buffer, random read buffer, etc. Do these queries use more caches?
MySQL performance tuning offers several significant advantages for effective database management and optimization. Enhanced Database Efficiency By adjusting configuration settings, you can markedly enhance the overall efficiency of your MySQL database. Experiencing database performance issues?
Key Takeaways Distributed storage systems benefit organizations by enhancing data availability, fault tolerance, and system scalability, leading to cost savings from reduced hardware needs, energy consumption, and personnel. Variations within these storage systems are called distributed file systems.
It has default settings for all of the database parameters. It is primarily the responsibility of the database administrator or developer to tune PostgreSQL according to their system’s workload. What is PostgreSQL performance tuning?
The rationale behind these methods is that frontend should be able to fetch transient information very efficiently and separately from fetching of heavy-weight domain entities because this information cannot be cached. So, the only way was to cache all necessary data to minimize interaction with RDBMS.
Traditionally records in a database were stored as such: the data in a row was stored together for easy and fast retrieval. Combined with the rise of data warehouse workloads, where there is often significant redundancy in the values stored in columns, and database models based on column oriented storage took off.
HammerDB is a software application for database benchmarking. It enables the user to measure database performance and make comparative judgements about databasehardware and software. Databases are highly sophisticated software, and to design and run a fair benchmark workload is a complex undertaking.
This removes the burden of purchasing and maintaining your hardware, storage and networking infrastructure, while still giving you a very familiar experience with Windows and SQL Server itself. You will still have to maintain your operating system, SQL Server and databases just like you would in an on-premises scenario. Esv3-series.
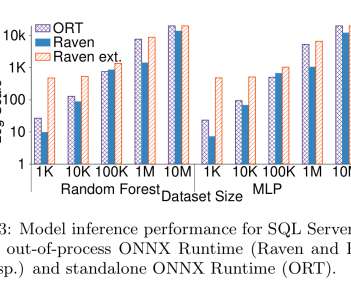
The motivation is not that inference will perform better inside the database, but that the database is the best place to take advantage of enterprise features (transactions, security, auditing, HA, and so on). These pipelines are stored directly in the database. End-to-end the picture looks like this: ( Enlarge ). The last word.
This article is an effort to explore techniques used by developers of in-stream data processing systems, trace the connections of these techniques to massive batch processing and OLTP/OLAP databases, and discuss how one unified query engine can support in-stream, batch, and OLAP processing at the same time.
An extension to Service Workers that enables browsers to present users with cached content when offline. is access to hardware devices. This allows customisation and use of specialised features without custom, proprietary software for niche hardware. Some commenters appear to confuse unlike hardware for differences in software.
A then-representative $200USD device had 4-8 slow (in-order, low-cache) cores, ~2GiB of RAM, and relatively slow MLC NAND flash storage. Hardware Past As Performance Prologue. Regardless, the overall story for hardware progress remains grim, particularly when we recall how long device replacement cycles are: Tap for a larger version.
Among the different components of modern software solutions, the database is one of the most critical. There are many times we get asked why some cloud instance performed poorly for their database application and almost always turned out to be some configuration error. TB)) for storage of database tablespaces and logging.
ETL is a product of the relational database era and it has not evolved much in last decade. Apache Arrow's in-memory columnar layout is specifically optimized for data locality for better performance on modern hardware like CPUs and GPUs. In contrast, Alluxio a middleware for data access - think Alluxio storage layer as fast cache.
Microsoft SQL Server I/O Basics Author: Bob Dorr, Microsoft SQL Server Escalation Published: December, 2004 SUMMARY: Learn the I/O requirements for Microsoft SQL Server database file operations. This cache is often supported by a battery-powered backup facility.
a 10TB database with 20% hot data) we observe a 2X improvement in throughput for random access across the 2TB hot dataset. In our experiment we deliberately size the active working-set to NOT fit into the metadata cache. On the same hardware with AES enabled – the time is cut in half. For large datasets (e.g.
This article will expand on my previous article and point out how these apply to SQL Server , Azure SQL Database , and Azure SQL Managed Instance. When looking at backups, I check for recovery model and the current history of backups for each database. Azure SQL Database and Azure Managed Instance have managed backups.
A wide range of users with different operating systems, browsers, hardware configurations and other variables provides a wide sample size that helps developers discover as many issues as possible. Teams can measure the performance of all application dependencies, including databases, web services, caching, and more.
On multi-core machines – which is the majority of the hardware nowadays – and in the cloud, we have multiple cores available for use. Aurora Parallel Query response time (for queries which can not use indexes) can be 5x-10x better compared to the non-parallel fully cached operations. The second and third run used the cached data.
MongoDB is an important database, and this paper explains the tunable (per-operation) consistency models that MongoDB provides and how they are implemented under the covers. Microsoft have a paper describing their new recovery mechanism in Azure SQL Database , the key feature being that it can recovery in constant time.
Looking beyond distributed caching, it’s their ability to perform data-parallel analysis that gives IMDGs such exciting capabilities. Application developers often deploy IMDGs as a distributed cache that sits between an application and its database; the IMDG offloads ephemeral data from the database.
Looking beyond distributed caching, it’s their ability to perform data-parallel analysis that gives IMDGs such exciting capabilities. Application developers often deploy IMDGs as a distributed cache that sits between an application and its database; the IMDG offloads ephemeral data from the database.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content