This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
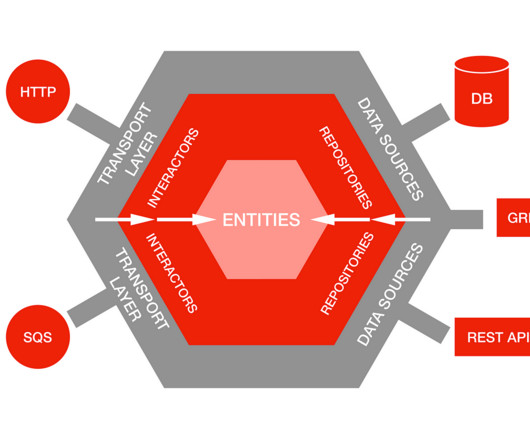
The strongest Kubernetes growth areas are security, databases, and CI/CD technologies. Strongest Kubernetes growth areas are security, databases, and CI/CD technologies. Of the organizations in the Kubernetes survey, 71% run databases and caches in Kubernetes, representing a +48% year-over-year increase.
This article is to simply report the YCSB bench test results in detail for five NoSQL databases namely Redis, MongoDB, Couchbase, Yugabyte and BangDB and compare the result side by side. I have used latest versions for each NoSQL DB and have followed the recommendations to run all the databases in optimized conditions. Load and 2.
This means you no longer have to provision, scale, and maintain servers to run your applications, databases, and storage systems. AWS AppSync: AppSync offers a fully managed approach to developing APIs with GraphQL — connecting to AWS DynamoLB or Lambda along with adding caches and client-side data. Data Store.
A common question that I get is why do we offer so many database products? To do this, they need to be able to use multiple databases and data models within the same application. Seldom can one database fit the needs of multiple distinct use cases. Seldom can one database fit the needs of multiple distinct use cases.
The RAG process begins by summarizing and converting user prompts into queries that are sent to a search platform that uses semantic similarities to find relevant data in vector databases, semantic caches, or other online data sources.
Specifically, how our team uses the relationships and schemas defined within GraphQL to automatically build and maintain a search database. Each service could potentially implement its own search database, but then we would still need an aggregator. Best of all, our page can load much faster since everything is cached in Elasticsearch.
a Fast and Scalable NoSQL Database Service Designed for Internet Scale Applications. Today is a very exciting day as we release Amazon DynamoDB , a fast, highly reliable and cost-effective NoSQL database service designed for internet scale applications. Werner Vogels weblog on building scalable and robust distributed systems.
Heading into 2024, SQL databases will remain essential in data management, increasingly using distributed systems to meet growing needs for scalability and reliability. According to 2023 statistics, 49% of web applications use an SQL-based database , with SQL having a 75% adoption rate in the IT industry.
The complete information on methods to kill the script execution and related behavior are available in the documentation. Get To Know the Redis Database: Iterating Over Keys. The ability to iterate cheaply over the Redis key space is very important to familiarizing yourself with the database contents. Learn more. Learn more.
sec) However, we can still find a warning in the official documentation , even for the 8.1 version, like this: ANALYZE TABLE removes the table from the table definition cache, which requires a flush lock. This makes the query wait for any long-running queries to finish but also can trigger cascading waiting for other incoming requests.
There are many naive solutions possible for this problem for example: Write different runs in different databases. Instead our challenge was to implement this feature on top of Cassandra and ElasticSearch databases because that’s what Marken uses. This is obviously very expensive. Write algo runs into files.
At authZ check time, provide the attributes for the identity to check, e.g. “can app bar in us-west-2 access this document.” A cleanup process to prune stale relationships from the database. SpiceDB is then responsible for figuring out which relations map back to the autoscaling group, e.g. name, environment, region, etc.
The default storage engine in earlier versions was MMAPv1, which utilized memory-mapped files and document-level locking. WiredTiger excels with operational databases and transactional workloads as it offers b-tree-based storage and well-ordered data structures. It uses a filesystem cache and write-ahead log for crash recovery.
See our documentation for more details on getting started or sign up for a free 15-day trial. According to the official AWS announcement, Graviton2-based Lambda functions offer up to 34% better price-performance improvement. For more information on AWS Lambda and Dynatrace click here.
To make data count and to ensure cloud computing is unabated, companies and organizations must have highly available databases. A basic high availability database system provides failover (preferably automatic) from a primary database node to redundant nodes within a cluster. HA is sometimes confused with “fault tolerance.”
Andreas Andreakis , Ioannis Papapanagiotou Overview Change-Data-Capture (CDC) allows capturing committed changes from a database in real-time and propagating those changes to downstream consumers [1][2]. In databases like MySQL and PostgreSQL, transaction logs are the source of CDC events. Designed with High Availability in mind.
Andreas Andreakis , Ioannis Papapanagiotou Overview Change-Data-Capture (CDC) allows capturing committed changes from a database in real-time and propagating those changes to downstream consumers [1][2]. In databases like MySQL and PostgreSQL, transaction logs are the source of CDC events. Designed with High Availability in mind.
Jamstack is popular with documentation sites that usually compile code to HTML files and host them on the CDN. Active Memory Caching. When you want to get data that you already had quickly, you need to do caching — caching stores data that a user recently retrieved. Caching Schemes. Caching Schemes.
At the same time that I see database engineers relying on the tool, sites such as StackOverflow are banning ChatGPT. ChatGPT: The InnoDB buffer pool is used by MySQL to cache frequently accessed data in memory. If we expand the cache concept more, the buffer pool could be even less if the working set (hot data) is smaller.
Note: Contrary to what the name may suggest, this system is not built as a general-purpose time series database. Partitioning Scheme At Netflix’s scale, the continuous influx of event data can quickly overwhelm traditional databases. Caching: Take advantage of immutability of data and cache it intelligently for discrete time ranges.
Source: OpenTelemetry Documentation. This occurs once data is safely stored within a local cache. Cloud databases excel at storing large volumes of information for later reference, and this data often has business value or privacy restrictions. OpenTelemetry reference architecture. What is telemetry data?
Specifically, how our team uses the relationships and schemas defined within GraphQL to automatically build and maintain a search database. Each service could potentially implement its own search database, but then we would still need an aggregator. Best of all, our page can load much faster since everything is cached in Elasticsearch.
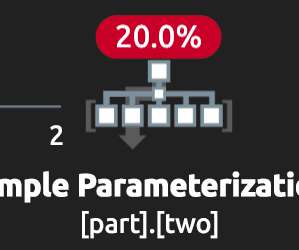
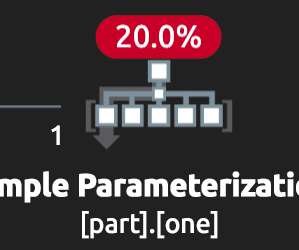
Simple parameterization has a number of quirks in this area, which can result in more parameterized plans being cached than expected, or finding different results compared with the unparameterized version. For the time being, let’s look at some examples using the Stack Overflow 2010 database on SQL Server 2019 CU 14. DisplayName.
The service workers enable the offline usage of the PWA by fetching cached data or informing the user about the absence of an Internet connection. When developing a PWA, you can cache the application shell’s resources and assets in the browser. Cached content with IndexedDB. Cache first, then network. Service Workers.
Specifically, how our team uses the relationships and schemas defined within GraphQL to automatically build and maintain a search database. Each service could potentially implement its own search database, but then we would still need an aggregator. Best of all, our page can load much faster since everything is cached in Elasticsearch.
Fragmentation is a common concern in some database systems. In databases, we can experiment with different types of fragmentation: Segment Fragmentation : segments are fragmented; they are stored not following the order of data, or there are empty pages gaps between the data pages. What is fragmentation?
MongoDB Community Edition software might set the stage for achieving your high-volume database goals, but you quickly learn that its features fall short of your enterprise needs. The popularity of MongoDB MongoDB has emerged as a popular database platform. 5 among all database management systems and No. It ranks No.
Whenever you install your favorite MySQL server on a freshly created Ubuntu instance, you start by updating the configuration for MySQL, such as configuring buffer pool, changing the default datadir director, and disabling one of the most outstanding features – query cache. It’s a nice thing to do, but first things first.
Imagine a world where your PostgreSQL® database connections are seamless and secure. Key Takeaways Understanding PostgreSQL hostname is essential for successful database connections. Understanding the PostgreSQL Hostname Hostname is a key factor for the effective management of PostgreSQL databases and providing secure access.
When deciding what to pick, there are many things to consider, like where the proxy needs to be, if it “just” needs to redirect the connections, or if more features need to be in, like caching and filtering, or if it needs to be integrated with some MySQL embedded automation. Given that, there never was a single straight answer.
This book has five major sections on MVCC and Isolation (108 pages), Buffer Cache and WAL (53 pages), Locks (42 pages), Query Execution (154 pages), and the types of indexes (127 pages). The illustrations are clear, and there are many reference pointers to the documentation or source code where needed. Is this an easy read?
Its raison d’être is to cache result rows from a plan subtree, then replay those rows on subsequent iterations if any correlated loop parameters are unchanged. The documentation says only the following operators can rewind: Table Spool. I have not been able to find any official explanation or documentation about it.
That’s why it’s essential to implement the best practices and strategies for MongoDB database backups. Why are MongoDB database backups important? Regular database backups are essential to protect against data loss caused by system failures, human errors, natural disasters, or cyber-attacks.
After we increased shared_buffers and restarted Postgres, the reads decreased to almost having to read nothing from the page cache or disks, and the writes are no longer done by the background writer but by the checkpointer. Percona Monitoring and Management is a best-of-breed open source database monitoring solution.
The main reason behind this is that MySQL is a relational database system (RDBMS), and any data that is going to be written in it must respect the RDBMS rules. In shard-nothing, each shard can live in a totally separate logical schema instance / physical database server/data center/continent. The POC Why this POC?
Also, high-quality documentation is available for developers with any development issues and queries. Also, there are tutorials, video forums, and documentation, making PHP development easy and troubleshooting more accessible. You can integrate PHP with many technologies, such as databases, web servers, CMS, etc.
Today, we’ll address storing and serving files for both single-server and scalable deployments while considering factors like compression, caching, and availability. Part 3 : Models, Admin, And Harnessing The Relational Database. Any file uploaded by a user, from profile pictures to personal documents, is called a media file.
This series doesn’t dwell too long on the basics but concentrates on less well-known aspects likely to trip up even the most experienced database professionals. In this first part, after a quick introduction, I look at the effects of simple parameterization on the plan cache. ALTER DATABASE SCOPED CONFIGURATION. sp_configure.
This article isn’t about the act of lock escalation itself, which is already well documented and generally well understood. Much of the documentation is incorrect or at least imprecise about this and I’ve been unable to find a correct description in other writings. Let’s look at some examples using a fresh database. GOTO Start.
They are responsible for the implementation of database systems, ensuring proper communication between various web services, generating backend functionality, and more. Laravel also offers its own database migration system and has a robust ecosystem. Backend developers work with a wide range of libraries, APIs, web services, etc.
Search Engine And Web Archive Cached Results. Another common category of imposter domains are domains used by search engines for delivering cached results or archived versions of page views. The message that appears above a cached search result in Google’s search service. Turning The Data Into Information. Large preview ).
HammerDB is a software application for database benchmarking. It enables the user to measure database performance and make comparative judgements about database hardware and software. Databases are highly sophisticated software, and to design and run a fair benchmark workload is a complex undertaking. The HammerDB name.
Note: We received feedback that there was some confusion on us calling this functionality “tail of the log caching” because our documentation and prior history has referred to the tail of the log as the portion of the hardened log that has not been backed up. Create / Alter Database … LOG ON. Tail Of Log Caching.
Percona Operators allow users to easily manage complex database systems in a Kubernetes environment. With Percona Operators , users can easily deploy, monitor, and manage databases orchestrated by Kubernetes, making it easier and more efficient to run databases at scale. yaml Inline is not handy if the configuration is big.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content