This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Concatenating our files on the server: Are we going to send many smaller files, or are we going to send one monolithic file? Caching them at the other end: How long should we cache files on a user’s device? Caching them at the other end: How long should we cache files on a user’s device? Cache This is the easy one.
By: Rajiv Shringi , Oleksii Tkachuk , Kartik Sathyanarayanan Introduction In our previous blog post, we introduced Netflix’s TimeSeries Abstraction , a distributed service designed to store and query large volumes of temporal event data with low millisecond latencies. Today, we’re excited to present the Distributed Counter Abstraction.
Caching is the process of storing frequently accessed data or resources in a temporary storage location, such as memory or disk, to improve retrieval speed and reduce the need for repetitive processing.
We introduce a caching mechanism in the API gateway layer, allowing us to offload processing from singleton leader elected controllers without giving up strict data consistency and guarantees clients observe. Active data includes jobs and tasks that are currently running. Titus Gateway handles user requests.
Redis , short for Remote Dictionary Server, is a BSD-licensed, open-source in-memory key-value data structure store written in C language by Salvatore Sanfillipo and was first released on May 10, 2009. Depending on how it is configured, Redis can act like a database, a cache or a message broker. Data Structures in Redis.
For the longest time now, I have been obsessed with caching. I think every developer of any discipline would agree that caching is important, but I do tend to find that, particularly with web developers, gaps in knowledge leave a lot of opportunities for optimisation on the table. Want to know everything (and more) about HTTP cache?
Second, developers had to constantly re-learn new data modeling practices and common yet critical data access patterns. To overcome these challenges, we developed a holistic approach that builds upon our Data Gateway Platform. Data Model At its core, the KV abstraction is built around a two-level map architecture.
Time To First Byte: Beyond Server Response Time Time To First Byte: Beyond Server Response Time Matt Zeunert 2025-02-12T17:00:00+00:00 2025-02-13T01:34:15+00:00 This article is sponsored by DebugBear Loading your website HTML quickly has a big impact on visitor experience. TCP: Establishing a reliable connection to the server.
Fetching data from the server and maintaining it is a very crucial issue in frontend development. library applications and how we maintain the server state with the library called React-Query. To manage the server state in the frontend and sync with the backend, we need to update, cache, or re-fetch the data efficiently.
Rajiv Shringi Vinay Chella Kaidan Fullerton Oleksii Tkachuk Joey Lynch Introduction As Netflix continues to expand and diversify into various sectors like Video on Demand and Gaming , the ability to ingest and store vast amounts of temporal data — often reaching petabytes — with millisecond access latency has become increasingly vital.
A shared characteristic in most (if not all) databases, be them traditional relational databases like Oracle, MySQL, and PostgreSQL or some kind of NoSQL-style database like MongoDB, is the use of a caching mechanism to keep (a copy of) part of the data in memory. So, how do you know if your hot data is in memory? MySQL does.
Before GraphQL: Monolithic Falcor API implemented and maintained by the API Team Before moving to GraphQL, our API layer consisted of a monolithic server built with Falcor. A single API team maintained both the Java implementation of the Falcor framework and the API Server. To launch Phase 1 safely, we used AB Testing.
The study analyzes factual Kubernetes production data from thousands of organizations worldwide that are using the Dynatrace Software Intelligence Platform to keep their Kubernetes clusters secure, healthy, and high performing. Big data : To store, search, and analyze large datasets, 32% of organizations use Elasticsearch.
This is guest post by Sachin Sinha who is passionate about data, analytics and machine learning at scale. Redis Server: 5.07, x86/64. MongoDB server: 4.4.2, BangDB server: 2.0.0, Load stage is to load the data and then run stage we run the test. Author & founder of BangDB. About YCSB. YugabyteDB:2.5.0,
Last week, I posted a short update on LinkedIn about CrUX’s new RTT data. Chrome have recently begun adding Round-Trip-Time (RTT) data to the Chrome User Experience Report (CrUX). Where Does CrUX’s RTT Data Come From? RTT data should be seen as an insight and not a metric. RTT isn’t a you-thing, it’s a them-thing.
Serverless architecture shifts application hosting functions away from local servers onto those managed by providers. This means you no longer have to provision, scale, and maintain servers to run your applications, databases, and storage systems. Data Store. Improving data processing. Let’s get started.
This blog post explores how AI observability enables organizations to predict and control costs, performance, and data reliability. It also shows how data observability relates to business outcomes as organizations embrace generative AI. GenAI is prone to erratic behavior due to unforeseen data scenarios or underlying system issues.
Andreas Andreakis , Ioannis Papapanagiotou Overview Change-Data-Capture (CDC) allows capturing committed changes from a database in real-time and propagating those changes to downstream consumers [1][2]. Requirements In a previous blog post, we discussed Delta , a data enrichment and synchronization platform.
When the server receives a request for an action (post, like etc.) from a client it performs two parallel operations: i) persisting the action in the data store ii) publish the action in a streaming data store for a pub-sub model. The streaming data store makes the system extensible to support other use-cases (e.g.
Andreas Andreakis , Ioannis Papapanagiotou Overview Change-Data-Capture (CDC) allows capturing committed changes from a database in real-time and propagating those changes to downstream consumers [1][2]. Requirements In a previous blog post, we discussed Delta , a data enrichment and synchronization platform.
the order of the rows on your Netflix home page, issuing content licenses when you click play, finding the Open Connect cache closest to you with the content you requested, and many more). In the Reliability space, our data teams focus on two main approaches. All these micro-services are currently operated in AWS cloud infrastructure.
We have several YouTube Tutorials and blog posts available that show how you can use Dynatrace RUM data for Web Performance & User Experience Optimization. Missing Cache Settings – Make sure you cache resources that don’t change often on the browser or use a CDN. Improve Above-the-fold User Experience with Dynatrace.
A lot of people surmise that TTFB is merely time spent on the server, but that is only a small fraction of the true extent of things. TTFB isn’t just time spent on the server, it is also the time spent getting from our device to the sever and back again (carrying, that’s right, the first byte of data!). But what else is TTFB?
It can happen on an edge API system servicing customer devices, between the edge and mid-tier services, or from mid-tiers to data stores. These include options where replay traffic generation is orchestrated on the device, on the server, and via a dedicated service. We will examine these alternatives in the upcoming sections.
This post looks at the other side of search: how to index data and make it searchable. Various creatives Marketing Tech supports To enable our marketing stakeholders to manage these creatives, we need to pull together data that is spread across many services?—?GraphQL GraphQL makes this aggregation easy.
If the script has already performed writes to the server and must still be killed, use the SHUTDOWN NOSAVE to shutdown the server completely. In fact, this discussion applies to any high availability system that depends on polling the Redis servers for health: Long-running scripts will initially block client commands.
The Multicore Era Over the past ~15 years, server processors from Intel and AMD have evolved from the early quad-core processors to the current monsters with over 50 cores per socket. “Concurrency” is the amount of data that must be “in flight” between the core and the memory in order to maintain a steady-state system.
Browsers will cache tools popular among vocal, leading-edge developers. There's plenty of space for caching most popular frameworks. The best available proxy data also suggests that shared caches would have a minimal positive effect on performance. Suppose a user has only downloaded part of the cache.
Rethinking Server-Timing As A Critical Monitoring Tool. Rethinking Server-Timing As A Critical Monitoring Tool. In the world of HTTP Headers, there is one header that I believe deserves more air-time and that is the Server-Timing header. Setting Server-Timing. Sean Roberts. 2022-05-16T10:00:00+00:00.
Netflix application identities are fundamentally attribute based: e.g. an instance of the Data Processor runs in eu-west-1 in the test environment with a public shard. An application owner might want to craft a policy like “Application members of the EU data processors group can access a PI decryption key”.
MySQL Server – Community Edition The problem applies to all versions of the upstream MySQL Community up to 8.0.23. Here is an example scenario you may end up here: mysql > select @@version,@@version_comment; + --+ + | @@version | @@version_comment | + --+ + | 5.7.43 | MySQL Community Server (GPL) | + --+ + 1 row in set (0.00
These expressions are evaluated in the current app session context, and can access data such as A/B test assignments, locality, device attributes, etc. Poor network connectivity coupled with frequently changing configuration values in response to user activity means that on-device rule evaluation is preferable to server-side evaluation.
New TanStack React Query integration See the blog post FormData / Non-JSON Content Types support One of our most requested features is the ability to send and receive more than simply JSON data. This enables you to build highly dynamic applications without suffering from server-client waterfalls.
As a result, web app attacks are the fastest-growing attack vector according to a recent data breach investigations report. This method involves providing the lowest level of access by default, deleting inactive accounts, and auditing server activity.
This allowed Android engineers to have much more control and observability over how we get our data. Background The Netflix Android app uses the falcor data model and query protocol. For example, the artwork service is separate from the video metadata service, but we need the data from both in the detail key.
This article explores the Hybrid Buffer Pool feature available in the SQL Server 2019. Introduction SQL Server uses Dynamic Random Access Memory (D-RAM) buffer pool for cachingdata pages retrieved from the disk. The buffer cache stores the page and writes back to disk only if it is modified.
By Karthik Yagna , Baskar Odayarkoil , and Alex Ellis Pushy is Netflix’s WebSocket server that maintains persistent WebSocket connections with devices running the Netflix application. This allows data to be sent to the device from backend services on demand, without the need for continually polling requests from the device.
When software runs in a monolithic stack on on-site servers, observability is manageable enough. OpenTelemetry, the open source observability tool, has emerged as an industry-standard solution for instrumenting application telemetry data to make it observable.
If we were to select the most important MySQL setting, if we were given a freshly installed MySQL or Percona Server for MySQL and could only tune a single MySQL variable, which one would it be? Sysbench ran on a third server, which I’ll refer to as the application server (APP).
consumers subscribe to data and are updated to the latest versions when they are published. Each version of the dataset is immutable and represents a complete view of the data?—?there there is no dependency on previous versions of data. Data model 1 topic -> many versions The top-level construct in Gutenberg is a “topic”.
When you add the Dynatrace extension to your Lambda functions, Dynatrace begins ingesting their metrics, logs, and traces, which you can monitor and correlate with data from the rest of your stack. In addition to the built-in views, Dynatrace provides data analysis tools that greatly enhance your abilities to query and chart metrics.
Logging provides additional data but is typically viewed in isolation of a broader system context. Observability is the ability to understand a system’s internal state by analyzing the data it generates, such as logs, metrics, and traces. Monitoring typically provides a limited view of system data focused on individual metrics.
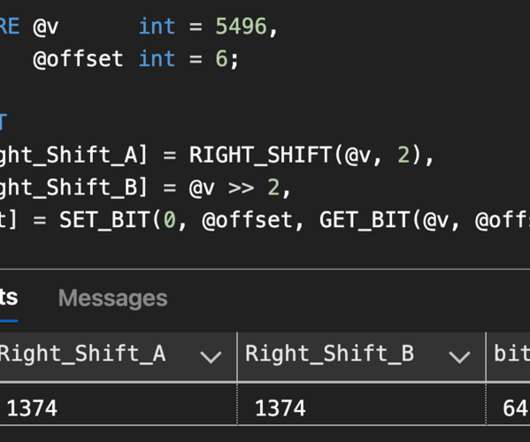
The need to manipulate data at the bit level with bitwise operations isn’t common in T-SQL, but you might stumble into such a need in some specialized scenarios. Even SQL Server stores some flag-based data using bitwise representation. Setting the server configuration option “ user options” using bitwise representation.
This Redis management solution allows startups up to enterprise-level organizations automate their Redis operations on Microsoft Azure dedicated cloud servers, alongside their other open source database deployments, including MongoDB , MySQL and PostgreSQL. PALO ALTO, Calif.,
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content